绑定手机号
确认绑定










本文作者来自中国科学技术大学、杭州像衍科技和浙江大学,作者提出了一种从单目视频重建穿衣服的人体模型的方法,只需在普通彩色摄像头之前自转一圈,便可以得到你的虚拟化身!
作者将 3D 人体的隐式表达和显式表达相结合,使用符号距离场 (隐式表达) 表示标准姿态空间下的人体,在视频的每一帧提取人体网格 (显式表达),借助学习到的前向变形场 (Forward Deformation Field) 将标准姿态空间下的人体网格变形到当前姿态下,并通过极小化轮廓损失、光滑损失等能量项来优化人体网格的形状,以得到具有更多细节的人体网格。和当前已有方法相比,文章方法不需要提前获取目标人体的模板网格 (对比 LiveCap, DeepCap 等方法),也不需要大量带纹理的人体模型用于网络训练 (对比 PIFu、PIFuHD 等方法),只需通过自监督的方法便可以从穿着任意服装的人体视频重建出带有众多细节的人体网格。总体来说,文章方法是一种基于优化的方法,需要针对每个个体进行人体模型的优化、重建,作者提到当前需要相对较长的时间才能得到结果,但具体时间目前未知,后续代码将会开源,大家可以保持关注!
项目主页:https://jby1993.github.io/SelfRecon


杭州像衍科技 (Image Derivative Inc.) 成立于2021年9月,创始团队与技术骨干主要来自于浙江大学 CAD&CG 国家重点实验室与中国科学技术大学,公司核心产品是三维数字人内容创作平台,涵盖便捷的三维人体建模与编辑、人体运动捕捉与生成、高真实感人体实时渲染等技术。平台通过移动端APP与云计算方式服务普通用户、应用开发者、内容创作者,应用场景包括支持多模态交互的虚拟数字人主播、远程全息沉浸式视频会议、虚拟现实教育等。
公司官网:https://idr.ai
文章方法的流程如下图所示,作者会同时维护显式和隐式两种人体几何表达,在每一帧使用前向变形场 (Forward Deformation Field) 来生成每一帧的显式人体网格。变形场由两个部分组成
第一部分使用一个可学习的 MLP 来表达每一帧的人体非刚性变形 (Non-rigid Deformation),以为标准姿态下的人体网格增加更多细节;
第二部分是蒙皮变形场 (Skinning Deformation Field),用于将标准姿态下的网格变形到当前帧姿态;
对于显式人体网格,作者使用可微的 Mask 损失、变形约束损失和骨架光滑损失来控制人体形状,对于人体隐式曲面,作者使用非刚性光线投射 (Non-rigid Ray Casting) 来计算光线和变形后的隐式曲面的交点,再使用颜色信息和交点特性来增加几何细节。
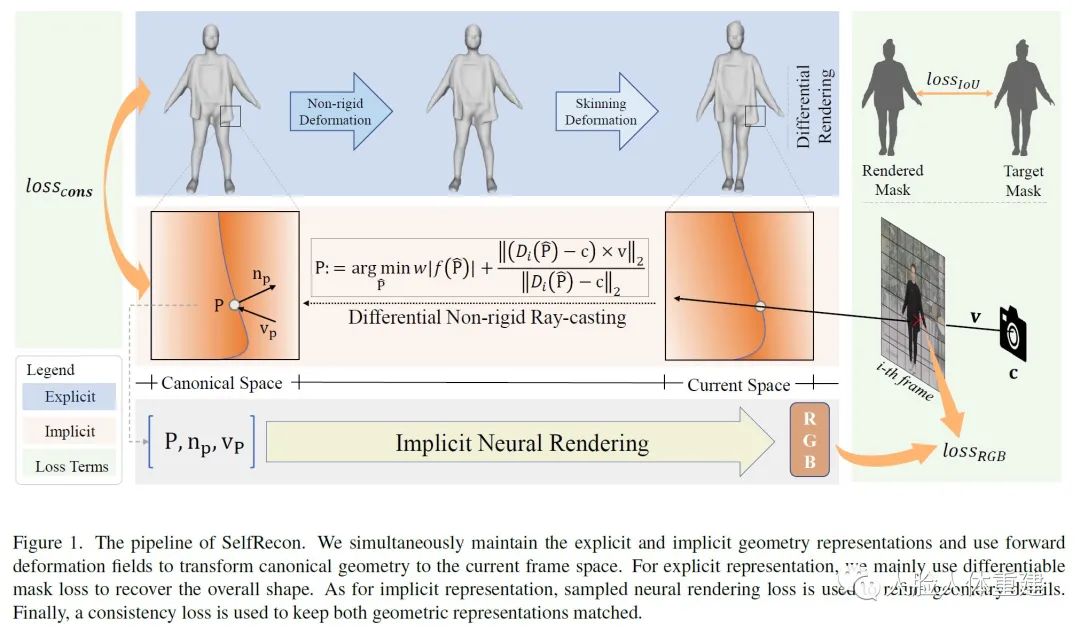 Pipeline
Pipeline对于一段含有 帧的人体自转视频,作者首先采用 VideoAvatar[2] 的方法来生成 SMPL 人体模型的初始形状 和每一帧的姿态参数 ,再预定义一个 A 姿态参数来生成初始的标准姿态空间的人体网格 ,并使用 来初始化隐式和显式表达。
作者将标准姿态空间下的模板人体网格 表示为符号距离场 (SDF) 的零等值面,SDF 由包含可学习权重 的 MLP 表示:
作者通过 IGR[5] 方法使用初始人体网格 来初始化 。
作者使用骨骼动画来驱动大范围的人体运动,为了表达服装的非刚性变形,作者增加了一个变形场来刻画非刚性变形。因此变形场包含两部分变形。
Non-rigid Deformation Field
使用包含可学习权重 的 MLP 来表达非刚性变形场。对于第 帧, 将可优化的条件变量 作为输入,使用与第 帧相对应的非刚性变形对标准姿态空间下的人体网格顶点进行变形。
Skinning Transformation Field
给定第 帧的姿态参数 ,需要定义标准姿态空间到当前姿态的蒙皮变形场 。作者将 SMPL 的蒙皮权重扩散到整个空间并进行光滑得到 ,其在后续过程中是固定的。
这样通过将 和 相结合,可以得到最终的变形场 ,其将第 帧的条件变量 和 SMPL 的姿态参数 作为输入,将标准姿态空间下的人体网格增加细节后变换到第 帧的姿态下。下图展示了标准姿态空间下的每一帧人体非刚性变形和作用蒙皮变形后的网格结果。

作者参考 [3] 中提出的可变形 SDF 渲染方法,使用显式网格来帮助找到射线与变形后的零等值面的交点。
论文 IDR [4] 提出可以使用一个 MLP 来估计渲染方程,并能在一定程度上将光照和材质解耦,对于刚性物体, 将零等值面上的点的位置、法向、视角方向和全局几何特征向量作为输入,估计该点沿着输入视角方向的颜色。作者将其推广到本文的非刚性情况。
对于一段含有 帧的视频,要优化的变量 为
其中 、 、 分布是 SDF、Implicit Rendering Network 和 Non-rigid Deformation Field 中的 MLP 的可学习权重, 是相机参数。文章的目标便是设计损失函数,优化变量








