绑定手机号
确认绑定










这项工作旨在通过专注于使用路边激光雷达对环境的 3D 感知来应对自动驾驶的挑战。作者设计了一个 3D 目标检测模型,可以实时检测路边 LiDAR 中的交通参与者。本文的模型使用现有的 3D 检测器作为基线并提高了其准确性。
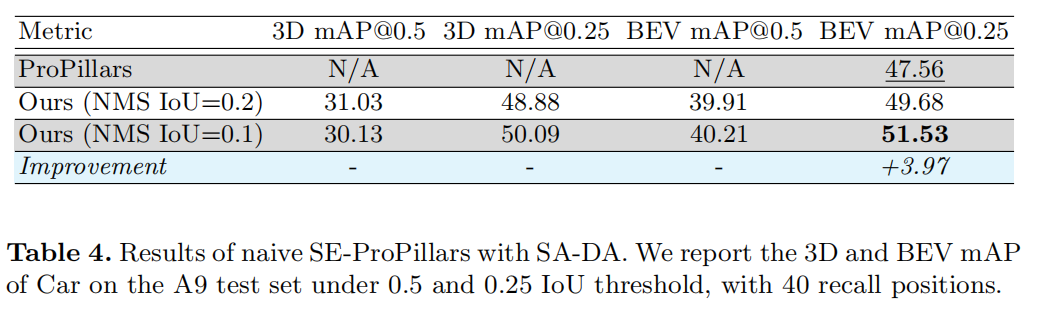
为了证明所提出的模块的有效性,作者在3个不同的车辆和基础设施数据集上训练和评估模型。为了展示本文所提检测器的领域适应能力,作者在来自中国的基础设施数据集上对其进行训练,并在德国记录的不同数据集上进行迁移学习。作者对检测器中的每个模块进行了几组实验和消融研究,实验结果表明本文的模型在很大程度上优于基线,而推理速度为 45 Hz(22 ms)。
通过基于 LiDAR 的 3D 检测器做出了重大贡献,该检测器可用于智慧城市应用,为自动驾驶车联网提供具有深远意义的视野。连接到路边传感器的车辆可以获得拐角处其他车辆的信息,以改进其路径和机动规划,进而提高道路交通安全。
根据特征表示的形式,LiDAR-only 3D 目标检测器可以分为4种不同的类型:
point-based方法
voxel-based方法
hybrid point and voxel 方法
projection-based方法
1.1、Point-based Methods
在基于点的方法中,特征通过采样子集或派生的虚拟点保持逐点特征的形式。PointRCNN 使用 PointNet++ 主干从原始点云中提取逐点特征,并执行前景分割。然后对于每个前景点,它会生成一个 3D 提议,然后是点云 ROI 池化和基于规范变换的边界框细化过程。
基于点的方法通常必须处理大量的逐点特征,这导致推理速度相对较低。为了加速基于点的方法,3DSSD 引入了特征最远点采样 (F-FPS),它计算特征距离以进行采样,而不是传统距离最远点采样 (D-FPS) 中的欧几里德距离。3DSSD 的推理速度可与基于Voxel的方法相媲美。
1.2、Voxel-based Methods
VoxelNet 将 3D 空间划分为等间距的Voxel,并将point-wise特征编码为voxel-wise特征。然后 3D 卷积中间层对这些编码的Voxel特征进行操作。稀疏点云空间上的 3D 卷积带来了太多不必要的计算成本。SECOND 提出使用稀疏卷积中间提取器,大大加快了推理时间。
在 PointPillars 中,点云被分成pillars(vertical columns),它们是特殊的Voxel,沿 z 方向没有任何分区。pillars的特征图可以被视为伪图像,因此昂贵的 3D 卷积被 2D 卷积取代。PointPillars 在 TensorRT 加速的帮助下达到了最快的速度。
SA-SSD 在稀疏卷积中间层添加了一个可分离的辅助网络来预测point-wise前景分割和中心估计任务,可以提供额外的点级监督。SA-SSD 还提出了一种part-sensitive warping(PS-Warp)操作作为额外的检测头。它可以减轻预测边界框和分类置信度图之间的错位,因为它们是由检测头中的两个不同卷积层生成的。
CIA-SSD 也注意到了错位问题。它设计了一个 IoU 感知的置信度校正模块,在检测头中使用一个额外的卷积层来进行 IoU 预测。预测的 IoU 值用于校正分类分数。通过仅引入一个额外的卷积层,CIA-SSD 比 SA-SSD 更轻量级。
SE-SSD 提出了一个self-ensembling post-training框架,其中一个预训练的教师模型产生预测,这些预测除了来自标签的hard targets之外,还用作soft targets。这些预测通过 IoU 与学生的预测相匹配,并由一致性损失监督。soft targets更接近学生模型的预测,因此可以帮助学生模型微调其预测。这里SE-SSD还提出了Orientation-Aware Distance-IoU Loss来替代训练后边界框回归的smooth-L1损失,以提供监督信号。SE-SSD 还设计了形状感知数据增强模块来提高学生模型的泛化能力。
1.3、Hybrid Methods
混合方法旨在利用基于Point和基于Voxel的方法。基于Point的方法具有更高的空间分辨率但涉及更高的计算成本,而基于Voxel的方法可以有效地使用 CNN 层进行特征提取,但会丢失局部point-wise信息。因此混合方法试图在它们之间取得平衡。
HVPR 是一种single-stage检测器。它有两个特征编码器流,分别提取Point特征和Voxel特征。提取的特征被整合在一起并分散成一个伪图像作为混合特征。在混合特征图上执行一个卷积中间模块,然后是一个single-stage检测头。
STD 是一个two-stage检测器,它使用 PointNet 来提取point-wise特征。具有球形Anchor点的基于Point的proposal生成模块旨在实现高召回率。然后一个 PointsPool 模块对每个proposal进行Voxel化,然后是一个 VFE 层。在框细化模块中,将 CNN 应用于这些Voxel以进行最终预测。
PV-RCNN 使用 3D 稀疏卷积进行Voxel特征提取。每个卷积层都添加了一个Voxel集抽象(Voxel-SA)模块,将Voxel特征编码为一小组关键点,通过最远点采样对其进行采样。然后通过前景分割分数重新加权关键点特征。最后,它们用于增强 ROI 网格点以进行细化。
R-CNN 从多视图投影中提取point-wise特征。它将点云分别投影到笛卡尔坐标下的鸟瞰图和Pillar坐标下的透视图。BEV 特征和point-voxel (PV) 特征连接在一起以在 BEV 中生成proposal,并融合在一起作为point-wise空心 3D (H3D) 特征。然后在 3D 空间上执行Voxel化,并将point-wise H3D 特征聚合为 voxel-wise H3D 特征以进行细化过程。
1.4、Projection-based Methods
RangeDet 是一种基于 LiDAR 的 anchor-free single-stage 3D 目标检测器,纯粹基于 range view representation。RangeDet结构紧凑,没有量化误差。使用 RTX 2080 TI GPU 的推理速度为 12 Hz。运行时间不受检测距离扩展的影响,但是 BEV 表示会随着检测范围的增加而减慢推理时间。
RangeRCNN 是另一个使用range image、point view和bird’s eye view (BEV) 的 3D 目标检测器。anchor在 BEV 中定义,以避免尺度变化和遮挡。此外,使用两阶段区域卷积神经网络(RCNN)来提高 3D 检测性能。
本文设计了一个实时 LiDAR-only 3D 目标检测器(SE-ProPillars),可以应用于现实世界的场景。设计的 SE-ProPillars 模型的架构如图 1 所示。
2.1、Point Cloud Registration
首先为安装在基础设施上的 LiDAR 设计了一种点云配准算法,以增加点密度并促进检测任务。
这里将2台 Ouster OS1-64 激光雷达并排安装(彼此相距约 13 m)在龙门桥上。2个 LiDAR 都使用 ROS 进行时间同步,ROS 时间本身与 NTP 时间服务器同步。一台 LiDAR 被视为源 (),另一台被视为目标 ()。2个 LiDAR 传感器都捕获 N 次点云扫描,每次扫描都标有 Unix 时间戳: 和 。目标是通过将源点云转换为目标点云的坐标系,将两个点云置于同一个坐标系中。
为了实现这一点,需要找到一组对应对 和 ,其中 对应于 。然后通过最小化对应之间的均方根误差 (RMSE) 来估计包括旋转 R 和平移 t 的刚性变换 T。

受前人工作的启发,作者提供了一个初始变换矩阵来帮助配准算法更好地克服局部最优。初始变换是通过实时运动学 (RTK) GPS 设备获得的。通过这种初始变换,连续配准不太可能陷入局部最优。连续配准是通过点对点ICP完成的。在 Intel Core i7-9750H CPU 上,两台以 10 Hz 运行的 Ouster LiDAR 的注册过程需要 18.36 毫秒。使用 2 m 的voxel大小可以实现 0.52164 的 RMSE。图 4 显示了配准前后的点云扫描。
2.2、Voxelization
这里将原始点云划分为vertical pillars,然后将它们输入神经网络。这些是不沿vertical轴分割的特殊voxels。与voxels相比,pillars有几个优点。由于网格单元较少,基于pillars的主干比基于voxels的主干更快。耗时的 3D 卷积中间层也被淘汰,取而代之的是 2D 卷积。
这里也不需要沿 z 方向超参数手动调整 bin 大小。如果pillars包含的点多于阈值中指定的点,则使用最远点采样将这些点二次采样到阈值。如果pillars包含的点数少于阈值,则用零填充以使维度一致。由于稀疏问题,大多数pillars都是空的。这里根据pillars的中心记录非空pillars的坐标。在特征提取过程中不考虑空pillars,直到所有pillars都被分散回伪图像以进行 2D 卷积。
2.3、Stacked Triple Attention
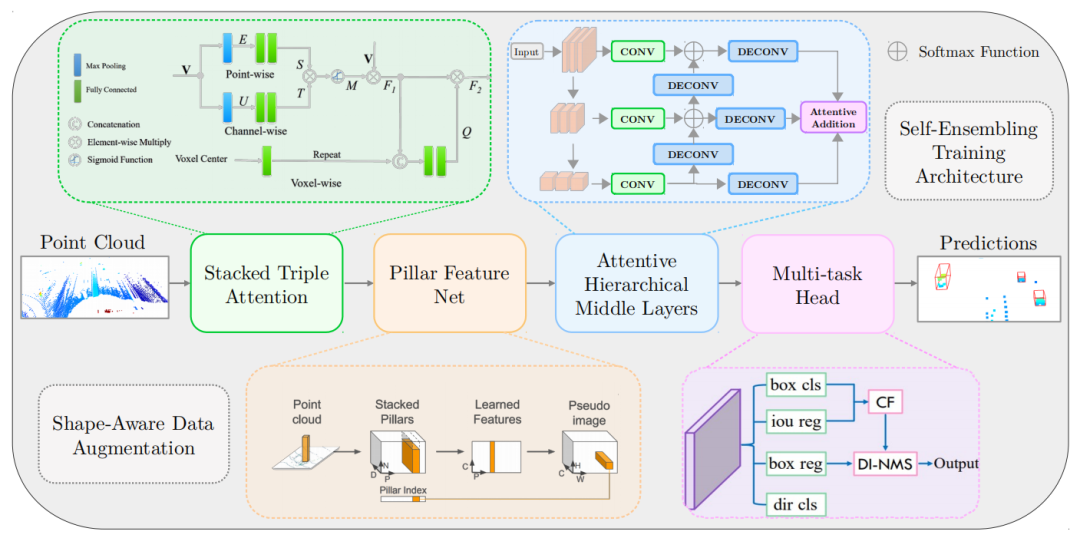
Stacked Triple Attention 模块用于更鲁棒和有区别的特征表示。该模块最初是在 TANet 中引入的,它增强了对难以检测的对象的学习,并更好地处理了嘈杂的点云。TA 模块使用 point-wise、channel-wise 和 voxel-wise attention 提取每个pillars内部的特征。本模块中的注意力机制遵循 Squeeze-and-Excitation 模式。
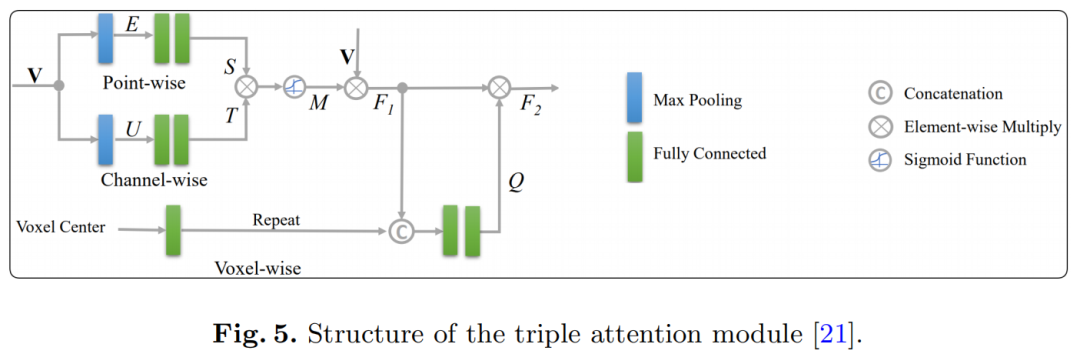
Triple Attention module的结构如图5所示。模块的输入V是一个P×N×C张量,其中P是非空pillars的数量,N是最大点数每个pillars,C 是输入的point-wise特征的维度。
在上分支的point-wise注意力中,遵循 Squeeze-and-Excitation 模式,首先执行最大池化以聚合通道维度上的point-wise特征,然后使用两个完全连接层。
类似地,中间分支 channel-wise attention 在它们的 point-wise 维度上聚合 channel-wise 特征,得到 channel-wise attention 分数 T。然后 S 和 T 通过 element-wise 乘法组合,然后用 sigmoid 函数得到注意力尺度矩阵 M,M = σ(S×T)。然后将 M 与输入 V 相乘,得到特征张量 F1。
在底部分支voxel-wise attention中,F1 中的 C-dim 通道特征被voxel中心(pillars所有点的算术平均值)放大到 C + 3-dim,以获得更好的voxel感知。然后放大的 F1 被送入2个全连接层。2个FC层分别将point-wise和channel-wise维度压缩为1,得到voxel-wise attention score。最后,一个 sigmoid 函数生成voxel注意力尺度 Q,与原始 F1 相乘以生成 TA 模块 F2 的最终输出。
为了进一步利用多级特征注意力,作者将2个triple attention modules堆叠在一起,其结构类似于 ResNet 中的 skip connections(见图 6)。

第一个模块将原始点云作为输入,而第二个模块处理提取的高维特征。对于每个 TA 模块,输入被连接或求和到输出以融合更多的特征信息。每个 TA 模块后面都有一个全连接层,以增加特征维度。在 TA 模块内部,注意力机制仅重新加权特征,但不增加它们的维度。
2.4、Pillar Feature Net
这里作者选择 PointPillars 作为基线,以牺牲推理时间为代价提高其 3D 检测性能。在没有 TensorRT 加速的情况下,PointPillars 的推理速度为 42 Hz。由于速度和准确性之间存在权衡,可以通过合并额外的模块来进一步提高准确性,而不会过多牺牲推理速度。
由图 1 所示的pillar feature net(PFN)。将pillars作为输入,提取pillars特征,并将pillars分散回伪图像,用于中间层的 2D 卷积操作。pillars特征网络充当堆叠triple attention modules的附加特征提取器。来自具有形状 (P × N × C) 的堆叠 TA 模块的逐点pillars组织特征被馈送到一组 PFN 层。每个 PFN 层都是简化的 PointNet,它由线性层、Batch-Norm、ReLU 和最大池化组成。最大池化特征连接回 ReLU 的输出,以保持每个pillars的逐点特征维度,直到最后一个 FPN 层。最后一个 FPN 层进行最终的最大池化并输出 (P × C) 特征作为pillars特征。然后将pillars特征散射回原始pillars位置,形成(C×H×W)伪图像,其中H和W是pillars网格的高度和宽度。这里空pillars的位置用零填充。
2.5、Attentive Hierarchical Middle Layers
作者将 PointPillars 的主干与 Attentive Hierarchical Backbone 交换,以对来自pillars特征网络的伪图像执行 2D 卷积。图 7 描绘了attentive hierarchical中间层的结构。
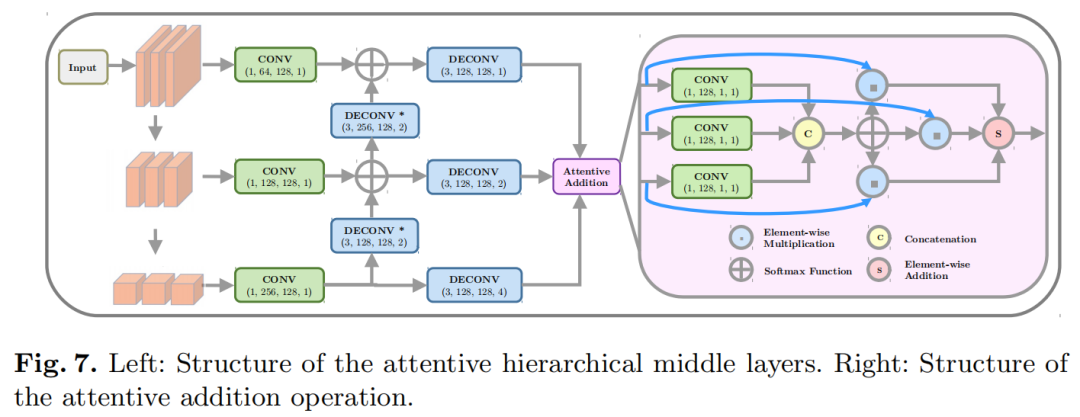
在第一阶段,伪图像的空间分辨率通过3组卷积逐渐下采样。每组包含3个卷积层,其中第一个卷积层的stride为 2 用于下采样,随后的2个层仅用于特征提取。在下采样之后,应用反卷积操作来恢复空间分辨率。反卷积层(用星号标记)以stride=2 恢复特征图的大小,并按元素将它们添加到上分支。其余3个反卷积层使所有3个分支具有相同的大小(原始特征图的一半)。然后最后的3个特征图通过一个 attentive addition组合在一起,以融合空间和语义特征。注意力加法使用普通注意力机制。所有3个特征图都通过卷积操作,并按通道连接为注意力分数。softmax 函数生成注意力分布,并将特征图与相应的分布权重相乘。最后的元素加法给出了最终的注意力输出一个(C×H/2×W/2)特征图。
2.6、Multi-task Head
多任务头输出最终类(基于置信度分数)、3D 框位置(x、y、z)、尺寸(l、w、h)、旋转(θ)和检测到的目标的方向。方向(前/后)进行分类,以解决正弦误差损失无法区分翻转框的问题。4个卷积层分别对特征图进行操作。图 1 显示了右下角的多任务头的简要结构。4个头之一是 IoU 预测头,它预测GT边界框和预测框之间的 IoU。它是在 CIA-SSD 中引入的,用于处理预测的边界框和相应的分类置信度图之间的错位。错位主要是因为这两个预测来自不同的卷积层。基于这个 IoU 预测,使用置信度函数 (CF) 来校正置信度图,并使用距离变化 IoU 加权 NMS (DI-NMS) 模块对预测的边界框进行后处理。
距离变量 IoU 加权 NMS 旨在处理长距离预测,以更好地将远边界框与GT对齐,并减少误报预测。如果预测的框接近透视原点会为那些具有高 IoU 的框预测赋予更高的权重。如果预测框距离较远给予相对统一的权重,以获得更平滑的框。
2.7、Shape-Aware Data Augmentation
数据增强已被证明是一种有效的方法,可以更好地利用训练数据集并帮助模型更加泛化。使用 SE-SSD 提出的Shape-Aware数据增强方法(见图8)。
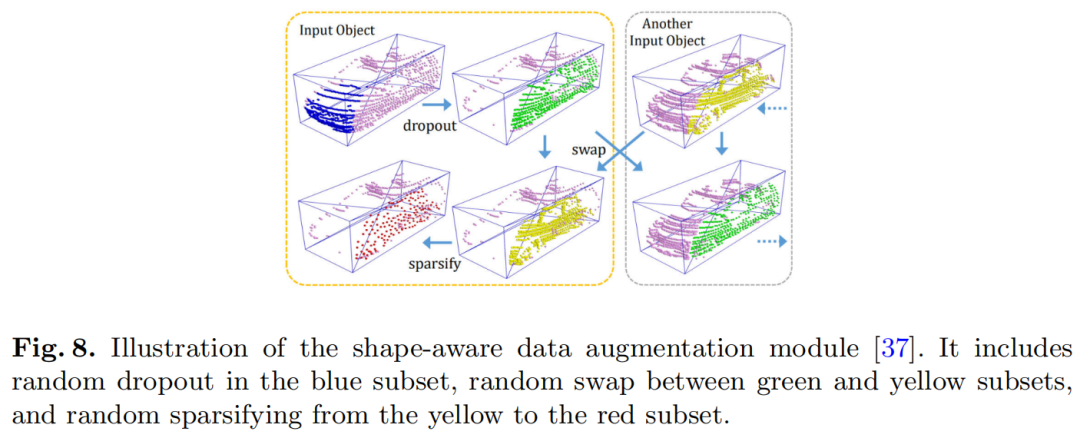
该模块简化了对同一类中对象的部分遮挡、稀疏和不同形状的处理。GT框分为6个金字塔子集。然后使用3个操作独立地扩充每个子集,随机dropout、随机swap和随机sparsifying。
在Shape-Aware增强之前也应用了一些传统的增强方法,例如 旋转、翻转和缩放。
2.8、Self-Ensembling Training Framework
此外,作者引入自集成训练框架进行后训练:首先训练图 9 所示的模型但没有自集成模块,然后将预训练的模型作为教师模型进行训练具有相同网络结构的学生模型。

教师模型的预测可以用作soft targets。结合来自GT的hard targets,这样便可以为学生模型提供更多信息。学生模型和教师模型使用相同的预训练参数进行初始化。在训练期间,首先将原始点云输入到教师模型并获得教师预测。然后将全局变换作为软目标应用于教师预测。对于hard targets,应用相同的全局变换以及形状感知数据增强。之后,将增强的点云提供给学生模型并获得学生预测。
在硬监督中引入了Orientation-aware distance-IoU(OD-IoU) 损失,以更好地对齐学生预测和hard targets之间的框中心和方向。与普通的 IoU 损失相比,OD-IoU 损失还考虑了2个框之间的距离和方向差异。
最后,使用基于 IoU 的匹配来匹配学生和教师的预测。使用分类分数和边界框预测的一致性损失来为学生模型提供软监督。训练学生模型的总体损失包括:
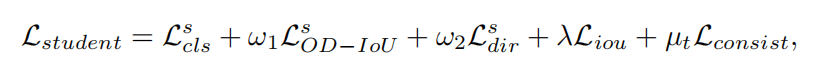
其中 是框分类的focal loss, 是边界框回归的 OD-IoU 损失, 是方向分类的交叉熵损失, 是检测头中 IoU 预测的平滑 L1 损失 , 是一致性损失,ω1, ω2, λ 和 µt 是损失的权重。
在训练后,教师模型的参数根据学生模型的参数进行更新,采用指数移动平均(EMA)策略,权重衰减为 0.999。
消融实验
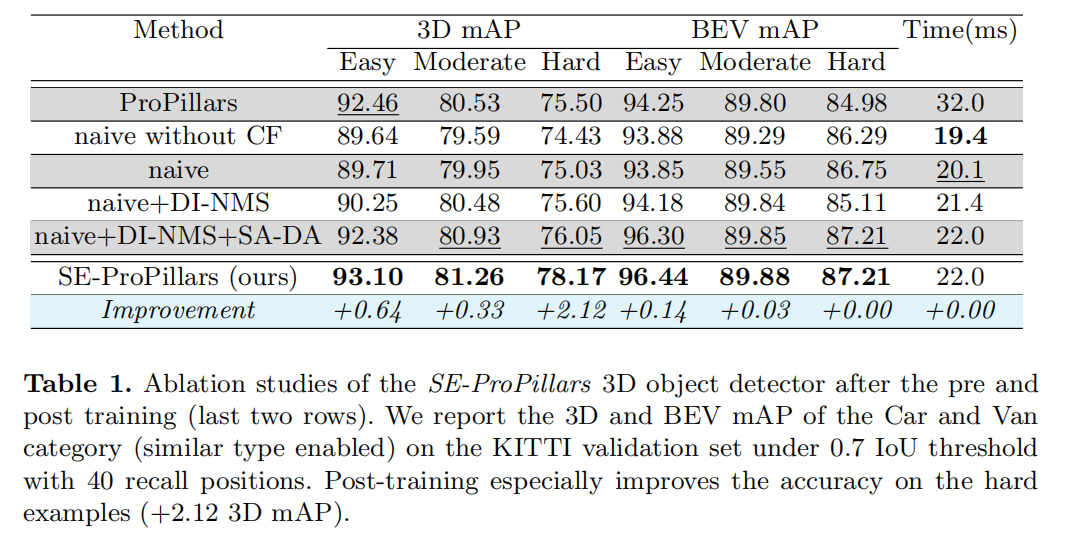
Kitti数据集
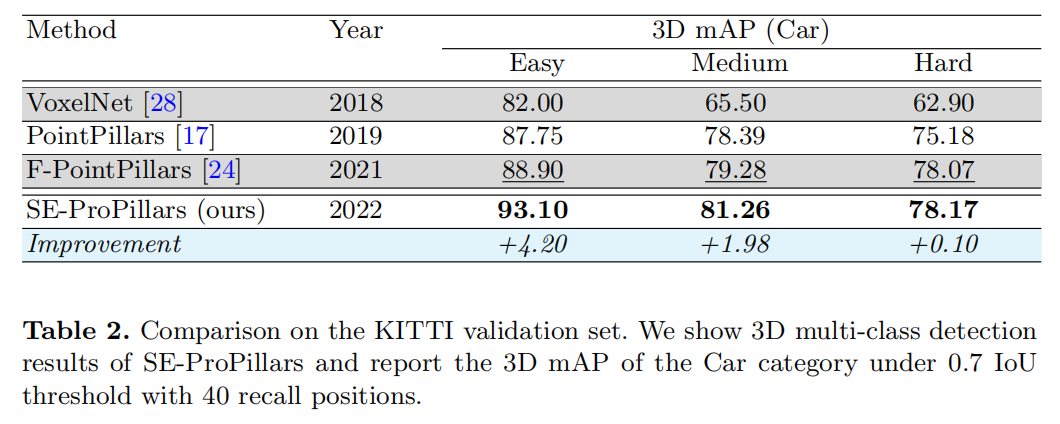
IPS300+ Roadside数据集
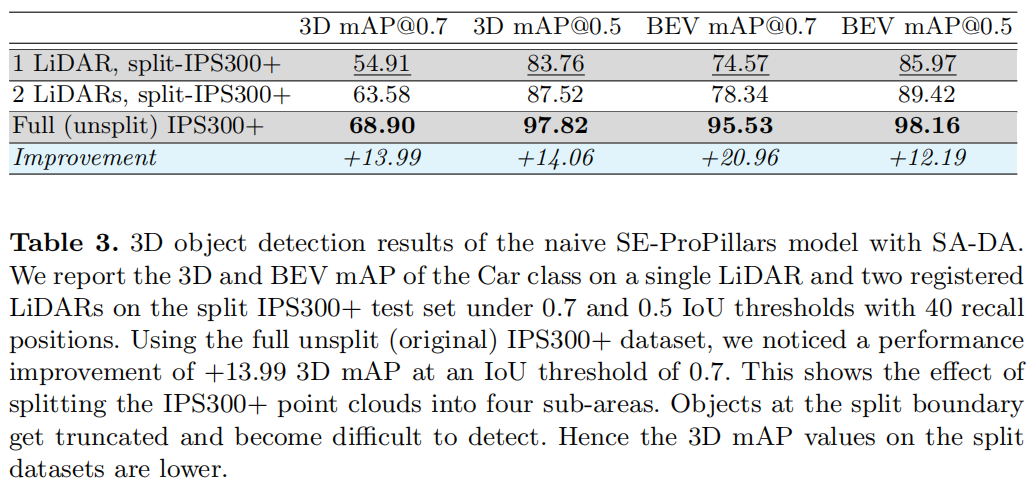
A9数据集
[1].Real-Time And Robust 3D Object Detection with Roadside LiDARs








