绑定手机号
确认绑定









本文分享论文『Higher Order Recurrent Space-Time Transformer for Video Action Prediction』,由 NVIDIA 开源《HORST》,用Transformer解决 Early Recognition 和 Anticipation 任务,惊叹又一任务被Transformer攻陷!
详细信息如下:

论文链接:https://arxiv.org/abs/2104.08665
项目链接:https://github.com/CorcovadoMing/HORST
导言:赋予机器强大的视觉预测能力是迈向大规模视频智能的关键一步。目前,这方面的主要建模范式是序列学习,主要通过LSTM来实现。在语言处理的深度学习应用中,Feed-forward Transformer结构已经取代了递归模型设计,在计算机视觉中Transformer也部分取代了递归模型设计。
在本文中,作者研究了Transformer结构在视频预测任务中的能力。为此,作者提出了HORST,这是一种高阶递归层设计,其核心设计是视频自注意的时空分解。HORST在Something-Something数据集上基于早期动作识别(early action recognition)任务和在EPIC-Kitchens数据集上基于动作预期(action anticipation)任务实现了不错的性能,这表明了更高层次的自注意设计的有效性。
从视频中识别人的行为是计算机视觉中一个被广泛研究的问题。大多数工作已经将动作识别作为视频片段分类问题来处理,最近几乎所有方法都使用深度学习,推动了从视频中进行时空特征学习的发展。
视频片段的动作识别中的一个基本假设是完整性和同步观察,即,要被识别的动作是立即可访问的,并且完全表示在视频片段中。这种完备性假设不适用于动作预测任务,即根据对过去的观察来预测未来。
实际上,随着时间的推移,观测可能会逐渐细化,以执行和重新验证未来的预测。这些都是基于视频预测的许多真实世界应用之间共享的需求,例如人机协作、实时视频监控和自动驾驶。
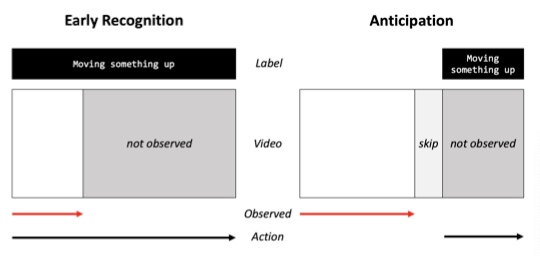
上图说明了早期动作识别和动作预期这两个主要的视频动作预测任务的问题设置。与动作识别相反,两者都需要预测超出观察到的视频子片段范围的动作标签。
在早期动作识别任务中,目标标签是全局的,虽然没有达到其全部程度,但是动作已经被表示为子片段中(即根据部分动作,预测完整动作)。在动作预期任务中,目标动作仅与子片段中的信号保持因果关系,而不能在子片段中直接观察到(即根据当前动作,预测下一个动作)。
用于动作预期和早期动作识别的标准建模框架是递归序列预测,其中视频帧被顺序处理以逐步更新相关视频内容的表示。最近的工作已经扩展到LSTM或GRU的设计上,以实现能够捕获跨时间的高阶相关性的模型,并通过自调节学习框架中的动态重加权机制修改中间表示。这些工作的共同目标是减轻由于预测误差累积而导致的性能下降。
在本文中,作者探索了用于预测任务(如动作预期和早期动作识别)的时空Transformer的设计和有效学习。Transformer在语言的ML应用中替换了递归模型,并在CV任务中也逐步成为主流网络。最新的工作表明,无卷积的纯Transformer结构可以在动作分类上与视频CNN达到相当的性能。在视频预测任务中,LSTM仍然是SOTA的方法中常用的建模范式,本文研究了Transformer是否可以在视频预测任务中取代LSTM。
为了验证这一点,作者提出了一种新的高阶递归层,其核心元素是视频自注意的时空分解。它在注意机制中维护状态队列以跟踪先前记录的信息,并且在每个时间步更新队列的方式是循环的。
方法
2.1. Preliminaries
Higher Order Recurrence
传统的递归网络遵循一阶马尔可夫假设,其中步骤t的输出仅取决于其先前的t−1状态,即:
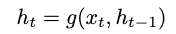
其中,g可以是包括LSTM和GRU的任意非线性函数,是当前输入,是当前和先前的隐藏状态。
扩展到更高阶马尔可夫假设,其中步骤t的输出取决于t−S到t−1的多个历史状态,其中S代表阶数,即:
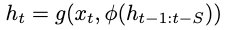
其中是状态队列的聚合函数。
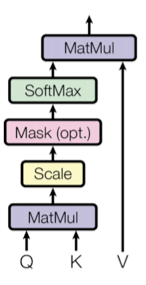
如上图所示,Transformer提出的attention机制将query Q、key K和value V作为输入。通过计算Q和K之间的点积,使用Softmax函数进行缩放,并将其乘以V,即可获得结果:
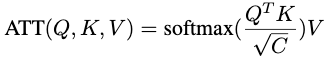
其中C是缩放因子。这种attention机制是无参数的,并且Transformer的学习能力依赖于之前的线性投影,它将给定层输入x映射到三个输入Q,K,V。
2.2. Spatial-Temporal Attention
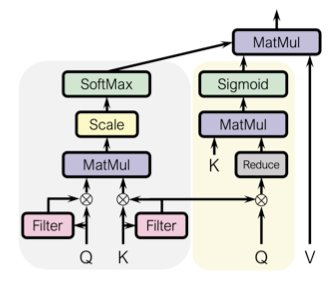
为了充分利用时空结构中的有效信息,作者提出了一种轻量级且计算效率高的attention机制,该机制集成了来自不同分支的时空算子。上图展示了本文提出attention机制的示意图,为了定义空间和时间分支操作符,作者引入了用于key和query的空间滤波器映射,用于attend到key和query中的相关空间区域,如下所示:
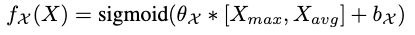
其中∗是卷积,是通道平均和最大池化,和是卷积核和偏置,Sigmoid用于映射到范围[0:1]。作者使用作为权重映射来过滤key和query空时注意力。
为每个时间步的空间注意力提供像素方向的权重矩阵。权重矩阵通过点积、全局平均池化和Sigmoid来进行计算,如下所示:
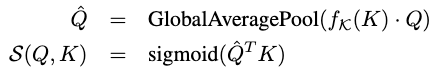
其中是element-wise的乘法。
是在时间维度中的重要性权重。权重是通过dot-product attention和Softmax来计算的,如下所示:
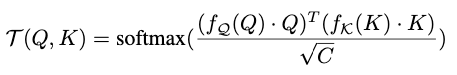
结合空间和时间分支,作者提出了自注意的时空分解:
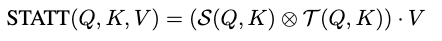
其中是cross-product。
本文的时空设计需要
2.3. Higher Order Recurrent Space Time Transformer
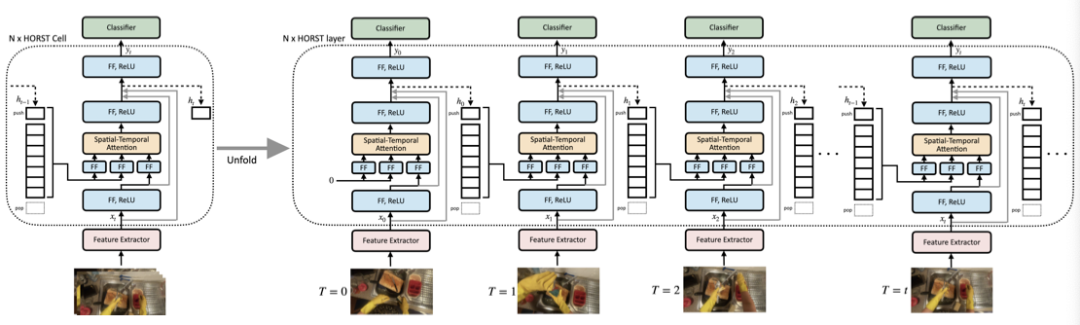
上图显示了HORST结构及其处理视频输入的展开图。所有FF块都是Conv-LayerNorm。在每一步t,首先通过2D-CNN主干网络处理视频帧以获得特征图,并用对其进行编码以获得中间表示。然后使用独立地将投影到Q、K、V。
计算完attention之后,再使用将时空注意输出投影到。最终的层输出为将用映射得到,并且用进行残差。将新状态推入队列,并且弹出最旧的状态。表示如下:
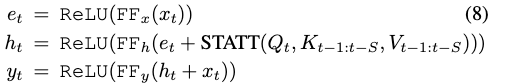
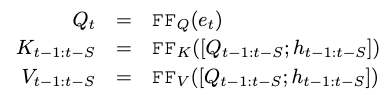
其中就是concat操作。
3.1. Early Action Recognition
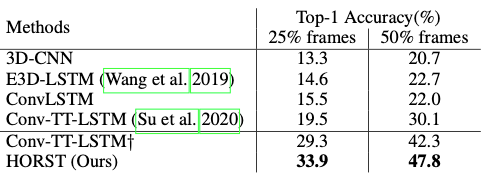
上表给出了SSv2 25%和50%早期动作识别的结果,可以看出本文的方法的性能优越性。
Visualization Analysis

上表展示了SSv2数据集上的时间和空间attention map的可视化。
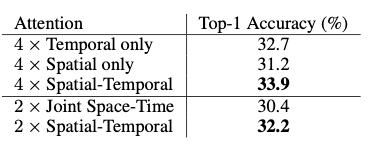
上表给出了不同attention变体的实验结果。
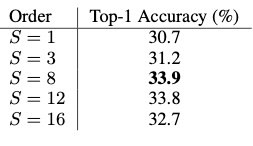
上表给出了attend阶数的实验结果,可以看出,S=8时能够达到比较好的实验结果。
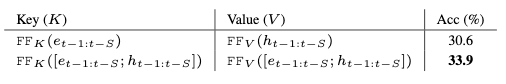
上表比较了两种不同的时空注意输入选择的结果。
3.2. Action Anticipation
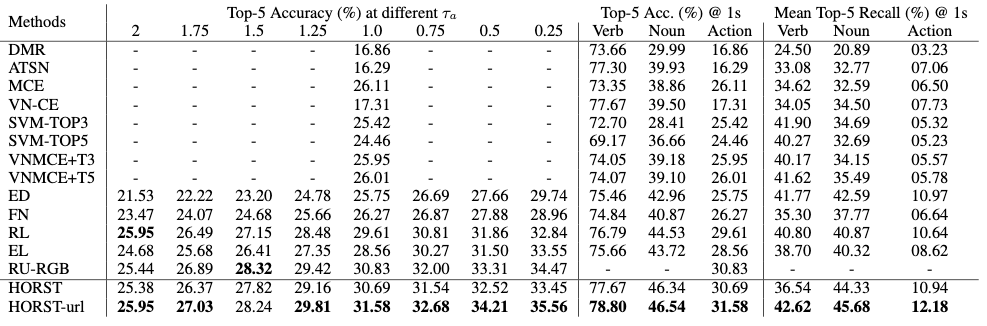
上表展示了不同预期时间的Top-5准确率,并给出了每个动词、名词和动作在时的Top-5准确率和Top-5平均召回率。
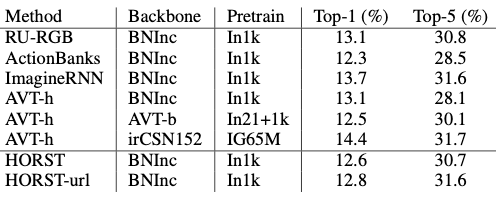
上表给出了在时,EK55 数据集上的TOP-1和TOP-5准确率。

上表给出了EK100 数据集上的实验结果。
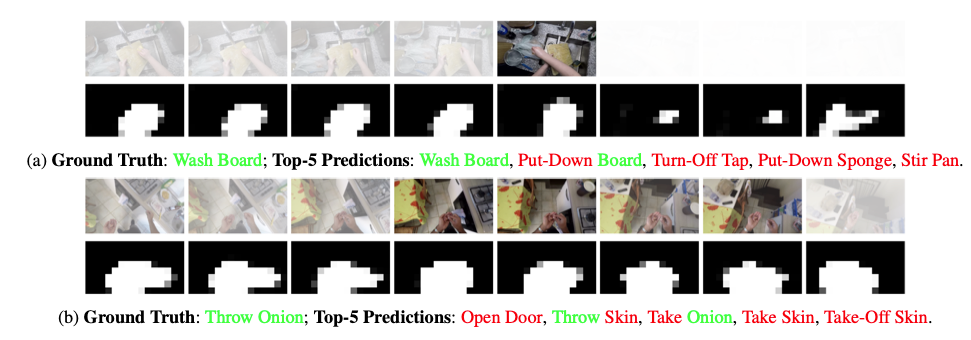
上表给出了EK55数据集上的可视化结果。
总结
在本文中,作者提出了HORST,这是一个基于Transformer的视频动作预测模型。它对自注意的时空分解揭示了模型行为的视觉解释。另外,HORST在动作预期任务上与SOTA性能相匹配,并在早期动作识别任务上以很大的优势达到了SOTA的性能。
目前,Transformer逐渐“统治”了CV和NLP领域的各个任务,但是在视频预测这一块还没有涉及,在本文中作者提出的HORST填补了这一空白,进一步促进了Transformer在CV领域的发展。








