绑定手机号
确认绑定









在自动驾驶中,通过RGB图像或激光雷达点云进行目标检测已得到广泛探索。然而,如何使这两个数据源相互补充和有益,仍然是一个挑战。AutoAlignV1和AutoAlignV2主要是中科大、哈工大和商汤科技等(起初还包括香港中文大学和清华大学)的工作。
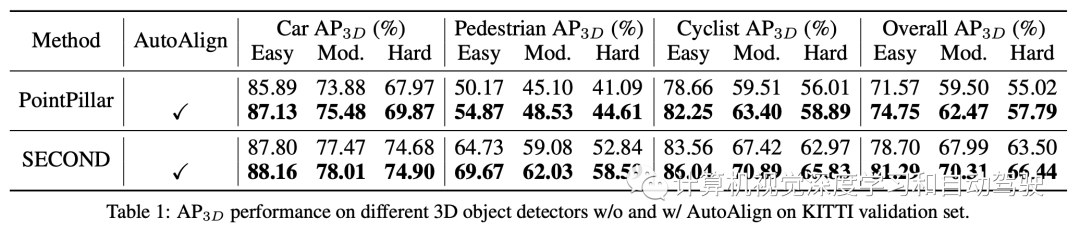
AutoAlignV1来自arXiv论文“AutoAlign: Pixel-Instance Feature Aggregation for Multi-Modal 3D Object Detection“,上传于2022年4月。

本文提出一种用于3D目标检测的自动特征融合策略AutoAlign V1。用一个可学习的对齐图(learnable alignment map)来建模图像-点云之间的映射关系,而不是建立与摄像机投影矩阵的确定性对应关系。该图使模型能够以动态和数据驱动的方式自动对齐非同态特征。具体而言,设计了一个交叉注意特征对齐模块,自适应地对每个体素的像素级图像特征进行聚集。为了增强特征对齐过程中的语义一致性,还设计了一个自监督跨模态特征交互模块,通过该模块,模型可以通过实例级特征引导学习特征聚合。
多模态3-D目标检测器可以大致分为两类:决策级融合和特征级融合。前者以各自的模式检测目标,然后在3D空间中将边框集合在一起。与决策级融合不同的是,特征级融合将多模态特征组合成单个表征来检测目标。因此,检测器可以在推理阶段充分利用来自不同模态的特征。有鉴于此,最近开发了更多的特征级融合方法。
一项工作将每个点投影到图像平面,并通过双线性插值获得相应的图像特征。虽然在像素级精细地执行了特征聚合,但由于融合点的稀疏性,将丢失图像域中的密集模式,即破坏图像特征中的语义一致性。
另一项工作用3D检测器提供的初始方案,获得不同模态的RoI特征,并连接在一起进行特征融合。它通过执行实例级融合来保持语义一致性,但在初始提议生成阶段存在如粗糙的特征聚合和2D信息缺失的问题。
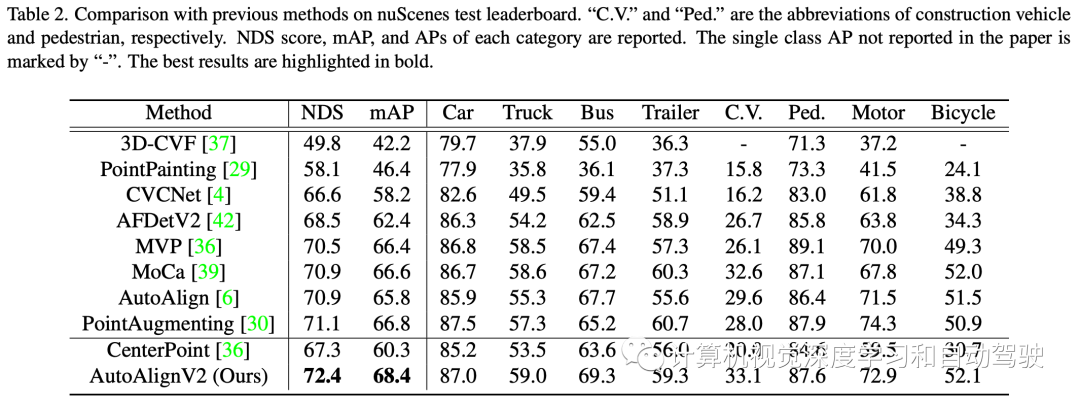
为了充分利用这两种方法,作者提出了一种用于3-D目标检测的集成多模态特征融合框架,名为AutoAlign。它使检测器能够以自适应的方式聚合跨模态特征,在非同态表征之间的关系建模中证明是有效的。同时,它利用像素级的细粒度特征聚合,同时通过实例级特征交互保持语义一致性。
如图所示:特征交互作用于两个层面:(i)像素级特征聚合;(ii)实例级特征交互。
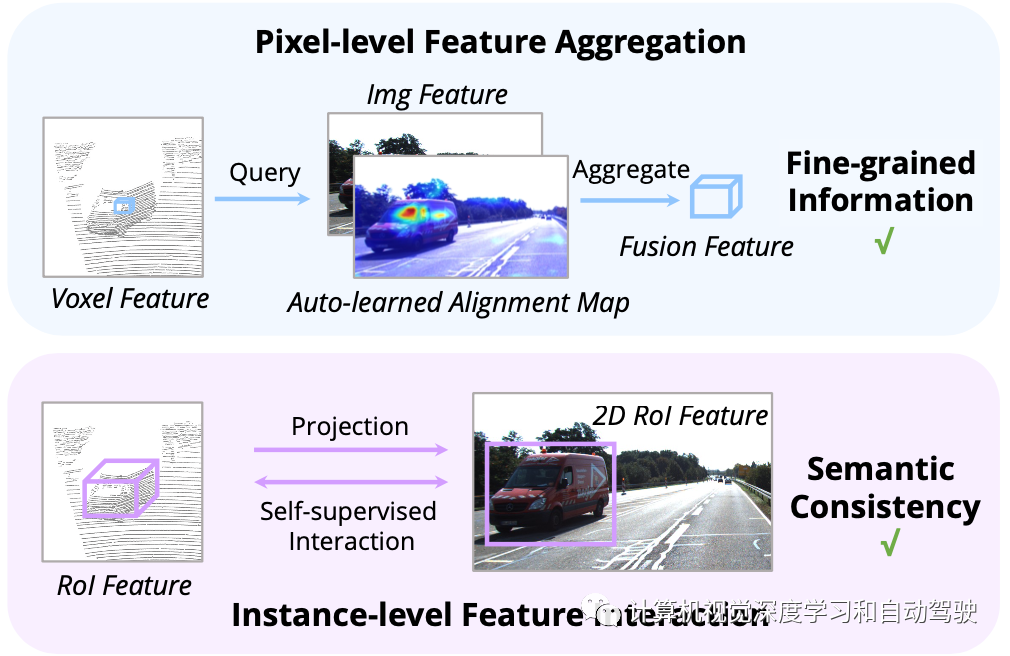
先前的工作主要利用摄像机投影矩阵以确定性方式对齐图像和点特征。这种方法是有效的,但可能会带来两个潜在问题:1)该点无法获得图像数据的更广泛视图,2)仅保持位置一致性,而忽略语义相关性。因此,AutoAlign设计了交叉注意特征对齐(CAFA)模块,在非同态表征之间自适应地对齐特征。CAFA(Cross-Attention Feature Alignment)模块不采用一对一的匹配模式,而是使每个体素感知整个图像,并基于可学习对齐图(learnable alignment map)动态地关注像素级2D特征。
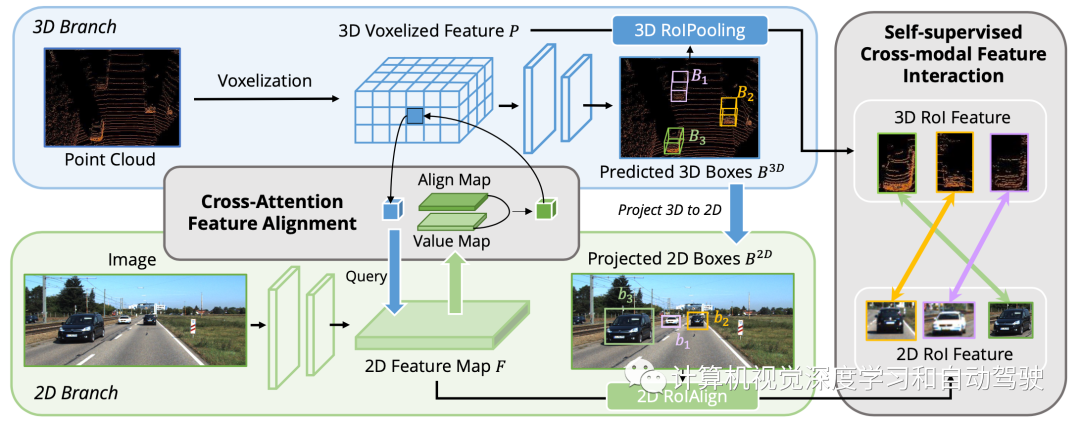
如图所示:AutoAlign由两个核心组件组成,CAFA在图像平面执行特征聚合,提取每个体素特征的细粒度像素级信息,SCFI(Self-supervised Cross-modal Feature Interaction)执行跨模态自监督,使用实例级引导,增强CAFA模块的语义一致性。
CAFA是聚集图像特征的细粒度范例。但是,它无法捕获实例级信息。相反,基于RoI的特征融合保持了目标的完整性,同时在提议生成阶段会受到粗糙特征聚集和2D信息缺失的影响。
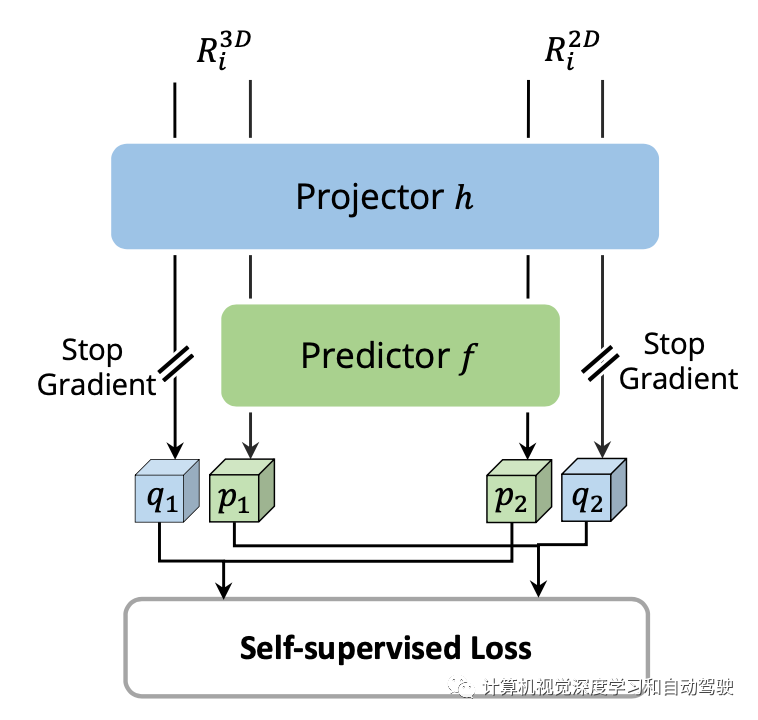
为了弥合像素级和实例级融合之间的差距,引入了自监督跨模态特征交互(SCFI)模块来指导CAFA的学习。它直接利用3D检测器的最终预测作为提议,利用图像和点特征进行精确的提议生成。此外,没有将跨模态特征连接在一起进行进一步的边框优化,而是在跨模态特征对中加入相似性约束,作为特征对齐的实例级引导。
给定2D特征图和相应的3D体素化特征,随机采样N个区域3D检测框,然后用摄像头投影矩阵投影到2D平面,从而生成一组成2D框对。一旦获得成对框,在2D和3D特征空间采用2DRoIAlign和3DRoIPooling来获得各自的RoI特征。
对于每个成对的2D和3D RoI特征,对来自图像分支的特征和来自点分支的体素化特征,执行自监督跨模态特征交互(SCFI)。两个特征都送入一个投影头,转换一个模态的输出以匹配另一个模态。引入一个有两个全连接层的预测头。如图所示:
尽管多任务学习非常有效,但很少有工作讨论图像域和点域的联合检测。在以前的大多数方法中,图像主干是外部数据集预训练权重直接初始化的。在训练阶段,唯一的监督是从点分支传播的3D检测损失。考虑到图像主干的大量参数,2D分支更有可能在隐监督下达到过拟合。为了正则化从图像中提取的表征,将图像分支扩展到Faster R-CNN,并用2D检测损失对其进行监督。


AutoAlignV2来自“AutoAlignV2: Deformable Feature Aggregation for Dynamic Multi-Modal 3D Object Detection“,上传于2022年7月。

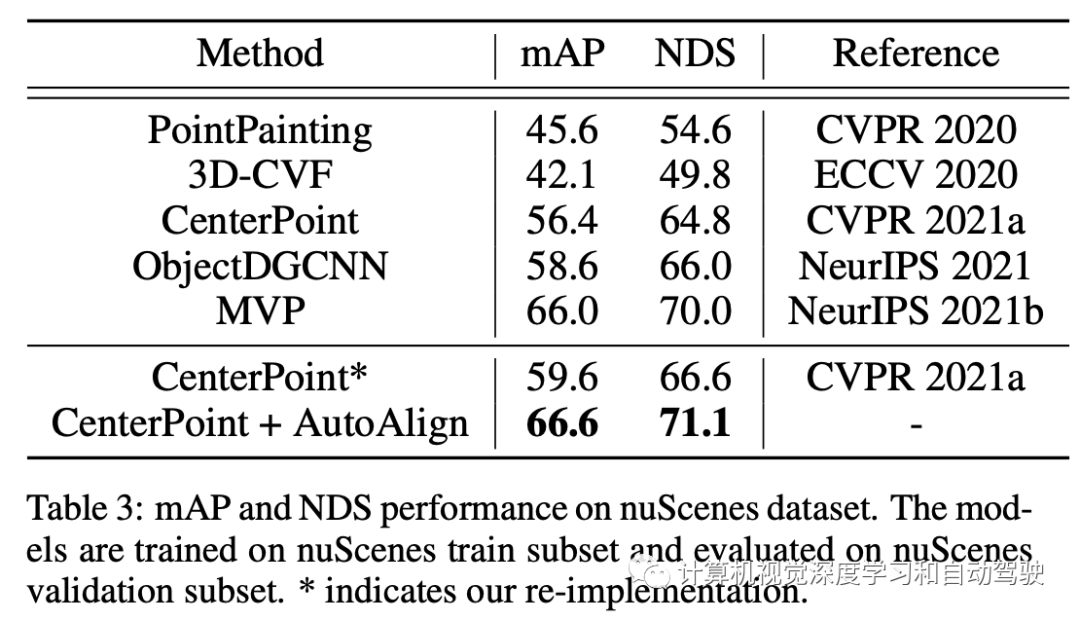
AutoAlign存在着由全局注意机制引入的高计算成本。为此,构建在AutoAlign之上,作者提出AutoAlignV2,一个更快、更强的多模式3D检测框架。为了解决计算成本问题,本文提出跨域DeformCAFA(Cross-Attention Feature Alignment)模块。它关注用于跨模态关系模型的稀疏可学习采样点,这增强了对标定误差的容忍度,并大大加快了跨模态的特征聚合。为了克服多模态设置下复杂的GT-AUG,在给定深度信息情况下针对基于图像patch的凸组合,设计了一种简单而有效的跨模态增强策略。此外,通过一种图像级dropout训练方案,模型能够以动态方式进行推理。
代码将开源:https://github.com/zehuichen123/AutoAlignV2.
注:GT-AUG(“SECOND: Sparsely embedded convolutional detection“. Sensors,2018),一种数据增强方法
如何有效地结合激光雷达和摄像头的异构表示进行3-D目标检测尚未得到充分的探索。当前训练跨模态检测器的困难归因于两个方面。一方面,结合图像和空间信息的融合策略仍然是次优的。由于RGB图像和点云之间的异构表示,将特征聚集在一起之前需要仔细对齐。AutoAlign提出一种用于自动配准的可学习全局对齐模块,并实现了良好的性能。然而,它必须在CSFI模块的帮助下进行训练,获取点和图像像素之间内部的位置匹配关系。
此外,注意风格的操作复杂性是图像大小的二次关系,因此在高分辨率特征图上应用query是不切实际的。这种限制可能导致图像信息粗糙和不准确,以及FPN带来分层表示的丢失。另一方面,数据增强,尤其是GT-AUG,是3D检测器实现竞争性结果的关键步骤。就多模态方法而言,一个重要的问题是在执行剪切和粘贴操作时如何保持图像和点云之间的同步。MoCa在2D域中使用劳动密集型掩码标注,获得精确的图像特征。边框级标注也适用,但需要精细复杂的点过滤。
AutoAlignV2方法
AutoAlignV2的目的是有效地聚集图像特征,以进一步增强3D目标检测器的性能。从AutoAlign的基本架构开始:将成对图像输入到一个轻量级主干网ResNet,再输入FPN获得特征图。然后,通过可学习对齐图(learnable alignment map)聚合相关图像信息,在体素化阶段丰富非空体素的3D表示。最后,增强的特征将馈送到后续的3D检测流水线中,生成实例预测。
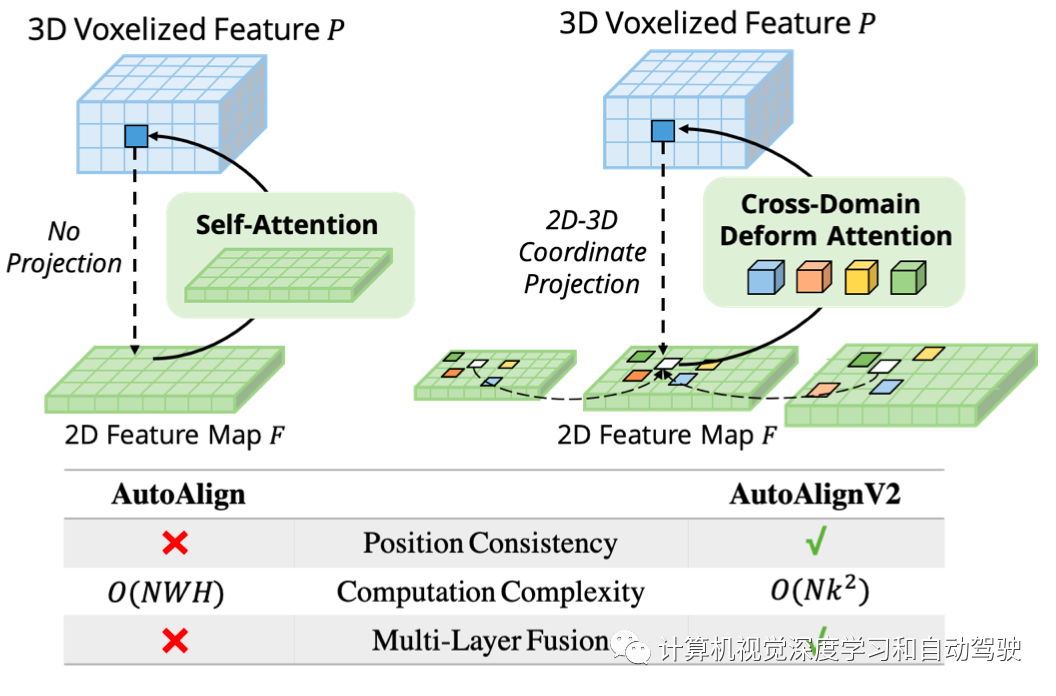
如图是AutoAlignV1和AutoAlignV2的比较:AutoAlignV2提示对齐模块有确定性投影矩阵保证的一般映射关系,同时保留自动调整特征聚合位置的能力。由于计算成本较轻,AutoAlignV2能够聚合分层图像信息的多层特征。
这种范例可以数据驱动的方式聚合异构特征。然而,有两个主要瓶颈仍然阻碍性能。第一个是低效的特征聚合。虽然全局注意图自动实现RGB图像和激光雷达点之间的特征对齐,但计算成本很高。第二种是图像和点之间的复杂数据增强同步。GT-AUG是高性能3D目标检测器的关键步骤,但如何在训练期间保持点与图像之间的语义一致性仍然是一个复杂的问题。
如图所示,AutoAlignV2由两部分组成:跨域DeformCAFA模块和深度-觉察GT-AUG数据增强策略,另外还提出了一种图像级dropout训练策略,使模型能够以更动态的方式进行推理。

变形特征聚合
CAFA的瓶颈在于,将所有像素作为可能的空间位置。基于2D图像的属性,最相关的信息主要位于几何邻近的位置。因此,不必考虑所有位置,而只考虑几个关键点区域。如图所示,这里引入了一种新的跨域DeformCAFA操作,该操作大大减少了采样候选者,并为每个体素query特征动态地确定图像平面的关键点区域。
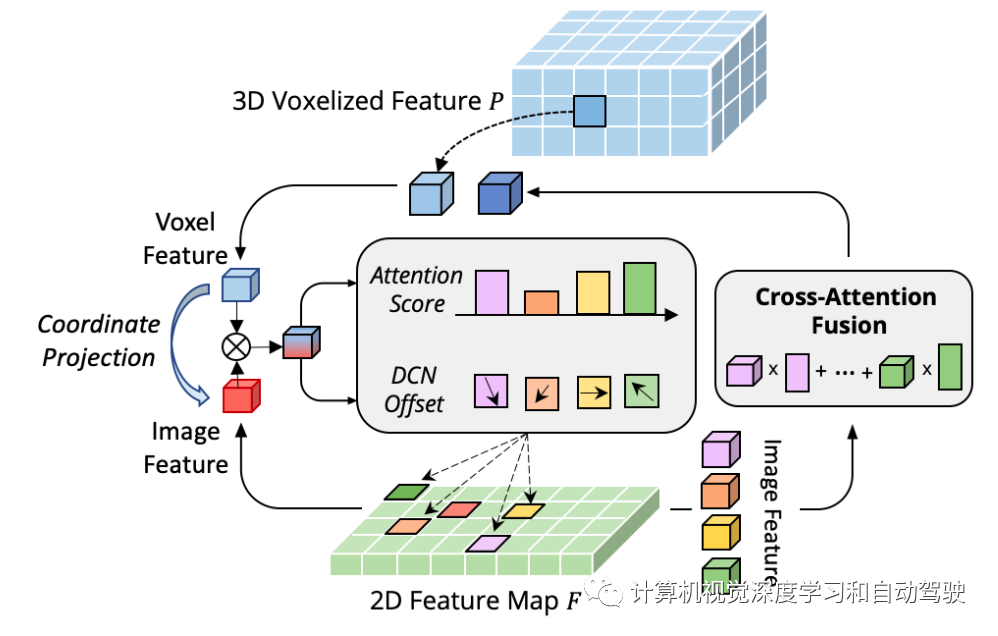
借助于动态生成的采样偏移,DeformCAFA能够比普通操作更快地进行跨域关系建模。能够执行多层特征聚合,即充分利用FPN层提供的分层信息。DeformCAFA的另一个优点是,显式地保持与摄像机投影矩阵的位置一致性,获得参考点。因此,即使不采用AutoAlign中提出的CFSI模块,DeformCAFA也可以产生语义和位置一致的对齐。
与普通的非局部操作相比,稀疏样式的DeformCAFA大大提高了效率。然而,当直接应用体素特征作为token来生成注意权重和可变形偏移量时,检测性能几乎无法与双线性插值相比,甚至更差。仔细分析,在token生成过程中存在跨域知识翻译问题。和通常在单峰设置下的原始变形操作不同,跨域注意需要两种模态的信息。然而,体素特征仅由空域表征组成,很难感知图像域的信息。因此,降低不同模态之间的交互非常重要。
假设每个目标的表示可以明确分解为两个组成部分:域特定信息和实例特定信息。前者指的是表征本身相关的数据,包括域特征的内置属性,而后者不管目标编码在哪个域,所表示的是有关目标的ID信息。
深度-觉察的GT-AUG
对于大多数深度学习模型而言,数据增强是实现竞争性结果的关键部分。然而,在多模态3D目标检测方面,在数据增强中将点云和图像组合在一起时,很难保持二者之间的同步,这主要是由于目标遮挡或视点的变化。为了解决这个问题,设计了一种简单而有效的跨模态数据增强算法,名为深度-觉察GT-AUG。该方法放弃了复杂的点云过滤过程或图像域精细掩码标注的要求。相反,从3D目标标注中引入深度信息,mix-up图像区域。
具体而言,给定要粘贴的虚拟目标P,遵循GT-AUG相同的3D实现。至于图像域,首先按照从远到近的顺序进行排序。对于每个要粘贴的目标,从原始图像中裁剪相同的区域,并在目标图像上以α的混合比组合。如下算法1中显示详细的实现。

深度-觉察GT-AUG仅在3D域中遵循增强策略,但同时通过基于mix-up的剪切和粘贴(cut-and-paste)保持图像平面的同步。关键点是,在原始2D图像粘贴增强的patches后,MixUp技术不会完全移除相应的信息。相反,它会衰减此类信息相对于深度的紧致性,以保证对应点的特征存在。具体而言,如果一个目标被其他实例遮挡n次,则该目标区域的透明度,根据其深度顺序以因子(1− α)^n衰减。
如图所示是一些增强的例子:

图像级别dropout训练策略
实际上,图像通常是一种输入选项,并非所有3D检测系统都支持。因此,更现实、更适用的多模态检测解决方案应采用动态融合方式:当图像不可用时,模型就基于原始点云检测目标;当图像可用时,该模型进行特征融合并产生更好的预测。为了实现这一目标,提出一种图像级dropout训练策略,在图像级随机dropout聚集的图像特征,并在训练期间用零填充。如图所示:(a) 图像融合;(b) 图像级dropout融合。

由于图像信息间歇性丢失,模型应逐渐学会将2D特征用作一种替代输入。