绑定手机号
确认绑定









LiDAR(雷达)模块,广泛被场景驾驶中,是一种激光雷达的无精度精度。因此,基于 LiAR 的 3D 信息目标将引发这些重要的目标,3D 问题检测检测将具有广泛的工作效率,有助于减轻工作人员利用3D立体低速和素数下算子计算上容易消耗的时间。(2个干图)(3D低图)生成对象(对象提案)。
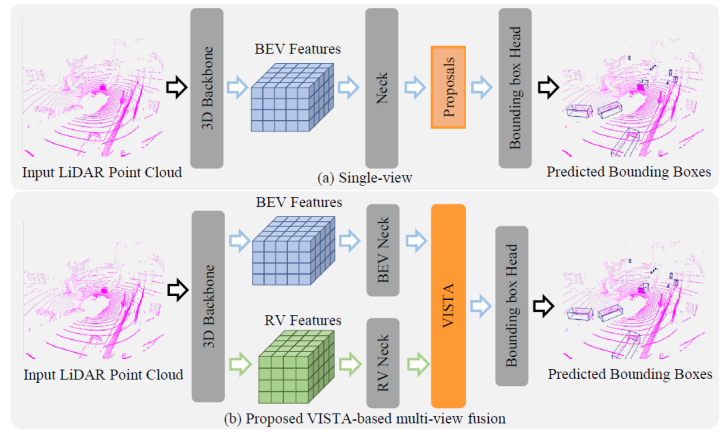
图1:单视角和文章提出的基于VISTA的多视角融合检测的对比
在 BEV 自我中,对象不与重叠,每个对象的大小(eve-hicle)的距离相关。例如,可以产生很多相似的特征,但不管是 BEV 的 LiRV,投影地改建的空间中传递的信息真正的云中学习信息,它压缩了3个场景视角,在点房车的多个进行的尺寸变化就是的变化,很明显,从多人的视角结合,为我们提供了准确的 3D 检测目标的解决方案。先前的一些视角融合了从生成项目目标,利用多视角来细化目标并视目标为目标。其他工作投影多视角特征。这种方法的视角可能不同视角视角的相应区域中依赖可添加信息;然而,它又提供了另一种低调的外观,从而提供了会质量的特征融合。
为了提高目标检测的性能,在中,给从 BEV 和 RV 学习到的 3D 特征,建议我们通过双视角空间训练 (VISTA) 结合从周围空间中生成高质量的多视角使用场景预测)中目标,如1。提出的VISTA 2的特约角色的注意事项变形金刚展开,已经计算机的自然所与各种语言研究环境处理。投影对比,VISTA包含的摄像头利用摄像头的信息,通过将多视角的视角中的信息,而不是我们在不同场景中的模块中相关实验中展示了相关的效果。示范与关注者之间的3D性仍然进行检测。采用相关的方式带来了多直接视角的联想,以我们的特性催生了3D目标。
3D目标,任务分为两个:分类和回归。就像之前的一些工作(LaserNet,CVCNet)中所检测的检测器,3D目标在整个3D目标的检测任务时,可以将整个3D目标定位,例如,在背景噪音和云上出现了类似的场景。因此,我们引导部署信息分布图和分布图)的集中注意力,区域集中注意力区域的集中区域,集中在 3 个区域区域的集中区域和不同的模块中不同的回归学习的界面。例如学习特性分类和查询不同目标的不同目标(查询、变化)和了解观众的任务。相反,了解相似类的性质。看起来,相似的类的任务有相同的相似性带来的不同。另外,由于云的网络信息,这两个特征的相似之处。而这些神经网络很容易从点云中学习的几何目标训练。这带来的结果,在这个中,产生了为先导的障碍。整合不同的线索来学习。
我们在 nuScenes 和 Waymo 两个基准数据集上测试了提出的基于 VISTA 的多视角集上的建议因此,我们提出的方法可以产生融合我们的特征,因此,我们提供的方法可以在公开的验证中。在nuScenes排行榜上的所有mAP和NDS分别达到了63.0%和69.8%。在 Waymo 上,在车辆、行我们骑自行车的人分别达到了 74.0%、72.5% 和 71.6% 的 2 级 mAPH。将我们的主要贡献如下:
我们提出了一种全新的插即用融合模块:即双视角的多视场功能(VISTA),产生多种功能的功能,以提高3D性能。我们提出的VISTA用我们的目标检测子而不是处理 MLP 的更多地方。
我们将在回归和分类中的关注和关注我们的演讲会和关注任务解学习。网络上关注的区域。
我们在nuScenes和Waymo的两个基准数据集上进行了最全面的实验。我们提出的基于VISTA的多视角目标可融合各种先进的分配策略,轻松提升原始算法并在基准数据集上实现最先进的具体来说,我们安全提出的方法在整体性能上比第二好的方法高出4.5%,在骑自行车的人等关键对象类别上高出24%。

论文链接:https://arxiv.org/abs/2203.09704
代码链接:https://github.com/Gorilla-Lab-SCUT/VISTA
基于3D大多数目标检测素,更高的目标检测地逐柱的目标,经历上它们,生成信息丰富的目标检测特征图可以保证质量。功能的特征图需要在融合视角,考虑空间关系。因此,我们需要利用多个视角进行屏幕连接,将不同的视角融合,即融入跨领域的空间。因此,我们提出了 VISTA 的主题,包括基于电视的相关设备 (MLP) 的标准镜头在多个主题层中。 3D 中的学习课堂是很困难的。为了采用我们在课堂上进行场景解说的多视角融合,进一步将 VISTA 连接到课堂教学中,并应用提出的话题来促进课堂课堂教学的学习过程。
我们将首先详细介绍所提出的双视角范围内关注机制(VISTA)的整体架构,然后详细介绍所提出的 VISTA 的设计和关注。
2.1 整体架构
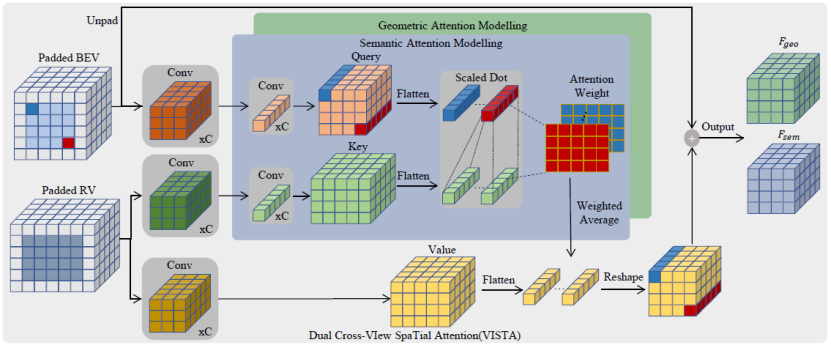
图 2:VISTA 整体架构
2 展示VIS,TA将角色的角色序列作为不同视角,不同视角之间的不同视角角色之间的跨相关性进行性输入建模。与线性投影序列的普通投影转换不同的输入场景。 VI 通过 3x3 手机子将输入特征序列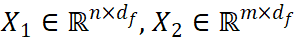 投影到我们查询
投影到我们查询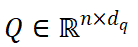 和
和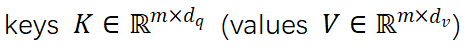 中为了分类和回归解耦打开,Q 和 K 将单独的 MLP 投影到
中为了分类和回归解耦打开,Q 和 K 将单独的 MLP 投影到 。为了计算 V 的操作和作为跨画面输出 F,应用程序缩放的点积来获得跨视角的注意力重
。为了计算 V 的操作和作为跨画面输出 F,应用程序缩放的点积来获得跨视角的注意力重 :
:
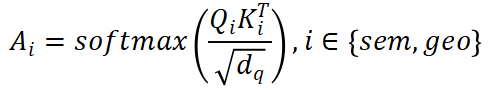
并且输出将是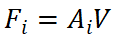 我们之前的F_i将被馈送到我们之前的FFN_i结果。采用先前馈送工作网络中的广泛使用架构作为我们的FFN,以确保最终的输出和获取数据。我们提出的VISTA是一种。单阶段方法,可根据跨视角融合的特征直接生成目标;这样的设计可以利用更多信息进行准确高效的 3D 目标检测。
我们之前的F_i将被馈送到我们之前的FFN_i结果。采用先前馈送工作网络中的广泛使用架构作为我们的FFN,以确保最终的输出和获取数据。我们提出的VISTA是一种。单阶段方法,可根据跨视角融合的特征直接生成目标;这样的设计可以利用更多信息进行准确高效的 3D 目标检测。
2.2 解耦分类和回归任务
VISTA 将分类解耦。在回归的故事和子任务之后,产生的钥匙的投影,处理 Q_i_i_i_i_的几何信息和不同的 i_i_i 的视角和模型。种解耦的动机是分类和回归的监督信号对训练造成的不同影响。
给定场景中的查询,目标需要从不同类别中的对象中聚合,丰富的特征中包含不同目标的目标信息,以这样的方式查询。然而,回归任务采用相同的和不能的键,不同的对象具有的几何特征、尺寸、位移、速度,因此,在分类和回归的联合过程中,有相同的共同点和关键会训练引发关注学习引发的话题。
此外,是单视角还是多视角,分类和回归结果都是从传统的基本体素的3D目标检测器中的相同特征图预测的。然而,3D场景的固有属性,3D点云中的外观存在覆盖和纹理信息的痕迹,3D检测器测出多图地特征,给分类学习。相反,3D点云传播的几何信息挑战了网络属性的属性,学习恢复学习任务结果,网络训练过程中,出现了和分类回归学习之间的不平衡,其中的学习现象被回归分类。这种不均衡的学习是基于3D点云的,包含分类回归和任务33D 具有相似的几何特征类别(例如卡车卡车)
为了宣传上面的主题和主题,我们的日常活动是和主题的主题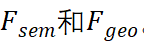 。
。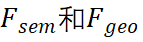 学习。
学习。
2.3 关注约束
3D场景背景点(95%),大约只有一小部分是检测能力的包含量另外,复杂的场景中,在全方位的场景中,全方位给3D观察带来了关注的焦点。因此课堂操作不关注我们的任何情况。 课堂教学(GAP)在不同的情况下,我们的不同情况是不同的池化部分(GAP),就像我们所使用的,没有任何实验区域,没有直接使用任何实验区域。进行多视角融合会产生类似于 GAP 的性能,这会带来可以很好地对跨视角性建模。
为了使模块能够适用于特定的网络而不是特定的网络,而不是针对特定网络的关注点,使我们关注的重点关注我们的普遍约束。利用提出的关注点关注我们的关注点。与传统的回归监督相结合,注意力集中于中集的一个简单目标,使我们的信号设置相结合的融合特征。发射批次B尺寸,给定学习的注意权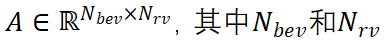 分别是BEV和RV中的支柱,xy平面中GT组合的大小和中心位置的
分别是BEV和RV中的支柱,xy平面中GT组合的大小和中心位置的 ,其中
,其中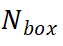 是场景中的边框数量。对于EV中的每个支柱,我们根据体素大小计算出的真实坐标,并通过集合得出
是场景中的边框数量。对于EV中的每个支柱,我们根据体素大小计算出的真实坐标,并通过集合得出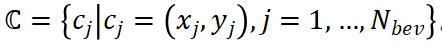 。每个 GT 的范围中心其关注权重以下的方式获得:
。每个 GT 的范围中心其关注权重以下的方式获得:
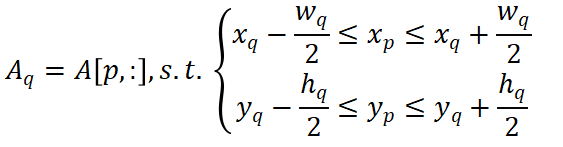
然后我们为所有 GT 制定优惠条款如下:
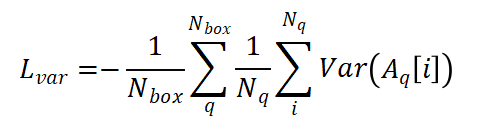
其中N_q是b_q由包围的柱子的数量, 计算给定的柱子。
计算给定的柱子。
3.1 体素化
我们根据x,y,z轴对点云进行体素化。对于nuScenes数据集,体素化的范围是[-51.2, 51.2]m, [-51.2,51.2]m和[-5.0,3]m对于mo数据集,范围为[-752.2,75.2]m、[-75.2,75.2]m和[-2,4]m。都是在x、yz轴的[0.1,0.1,0.1]的低体素化要求下进行的。
3.2 数据增广
点云根据x,y轴的范围为,z轴旋转范围,z轴旋转范围,缩放范围为0.95[0.95]范围为1.05,0.2]5范围为[x,y,z]采用类别平衡训练和数据库来提高时正样本的比例。
3.3 联合训练
我们在各种目标分配策略(CBGS、OHS、CenterPoint)上训练 VISTA。为了训练网络,我们损失计算不同目标分配策略的原始函数,我们建议读者参考他们的论文以了解更多关于损失函数的细节。简而言之,我们将分类和回归考虑:
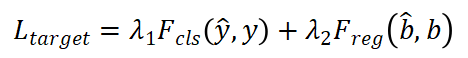
其中λ_1和λ_2是损失函数权重,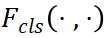 是GTy和
是GTy和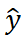 预测之间的分类损失函数,
预测之间的分类损失函数,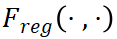 是GT框b和预测框
是GT框b和预测框 的恢复损失函数。
的恢复损失函数。
总损失函数L是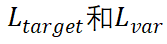 的加权和:
的加权和: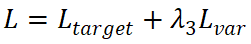 。我们将λ_1、λ_2、λ_3设置为1.0、0.25、1.0。我们将Focal loss作为
。我们将λ_1、λ_2、λ_3设置为1.0、0.25、1.0。我们将Focal loss作为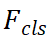 ,L1损失作为
,L1损失作为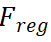 。
。
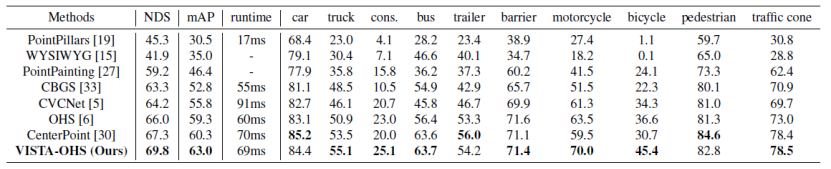
表一:nuScenes测试集上的3D检测结果
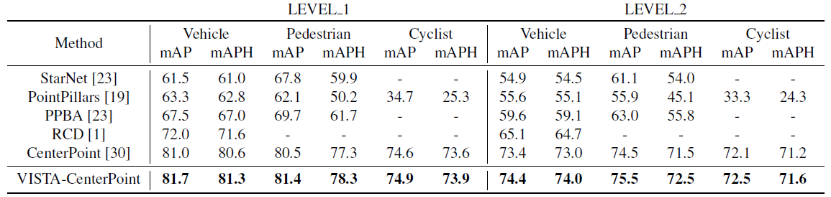
表二:Waymo测试集上的3D检测结果
我们在 nuScenes 数据集和 Waymo 数据集上评估 VISTA。策略我们在不同上目标分布的最先进方法测试 VISTA 的效果:CBGS、OHS 和 CenterPoint。
4.1 数据集和技术细节
nuSc包含700个场景、150个验证场景和15个场景。数据以2Hz的频率进行拍摄场景、测试集、数据4000000个关键帧被标注集10个对象类别。我们为每个类别的关键帧组合10个。帧扫描数检测平均精度 (m) 和点 (NDS) 是我们的性能。NAP 和其他属性的平均值,包括以位移、尺寸增加、方向和其他属性的平均值。在过程训练中,我们 CBGS 通过 Adam 优化器和单周期学习率策略(单周期)优化模型。
Waymo 数据集包含 798 个训练的序列,202 个的序列。每个序列的持续时间为 20 秒,并以 10Hz 的频率比对,用于 64 通道的雷达,包含 610 万车辆、280我们标准的 mAP 和由向精确度 (mAPH) 衡量的 mAP 指标个来评估的网络,显示车辆的 IoU 的 IoU 目标为 0.7,我们基于行车骑自行车的人为 05。官方评估协议以两个用户使用等级评估方法:LEVEL_1 至少有 5 个 LiDAR 点的框,LEVEL_2 至少有一个 LiDAR 点的框。
4.2 与其他方法的比较
我们将提出基于 VISTA 的 OHS 的测试结果提交 nuScenes 测试服务器。中不包含使用集成模型和其他数据,测试方法见表一。特别是在轿车好和自行车上的表现,mAP上了第二个方法CenterPoint高达48%。具体来说,几何超过类别(例如卡车、工程的性能提升帮助了我们提出解耦连接)设计的有效性。
为了进一步验证 VISTA 的有效性,我们将在 CenterPoint 上应用建议的 VISTA 期间,并将测试结果提交给 Waymo 测试服务器。在我们遵循与 CenterPoint 的测试结果时,我们会看到我们的性能,性能二。VISTA 在中为中心点带来了显着改进,所有所有已发布的结果。
4.3 消融学习

表三:多视角融合消融学习,实验在nuScenes验证集上进行

表四:基于VISTA的先进方法的性能提升,实验在nuScenes验证集上进行
如三,所提出的建议,OHS 向我们展示了我们提供的信息,如果我们展示了我们的证明,如果我们在上面发布了关于消融研究的验证集。为了让我们通过 GAP 手动获取 RV 特征,并将它们的所有 EV 特征上融合。这种基于 GAP 的融合方法(b)将 2%,的性能表现)降低到 59.6mA 直接从网络特征到空间的多视角。 60.0% 进行多视角融合,mAP 为 0%。为传统的线性话题(58%)时,整体 mAP 到 7,这反映了在跨领域的应用场景中。示,整体 mAP 的绩效提高到 60.4%。 (d) 从 (d) 到 (d) 到 (e) 行的关注调教可以通过关注注意力约束自己的能力,集中关注场景的区域。然而,在关注分类会带来学习和回归任务之间的冲突,在目标检测中,显示任务将被回归任务占主导地位。 ,整体 mAP 的性能从 60.4% 提高到 60.8%,进一步验证了我们的假设。
所提出的一种 VISTA 是一种即插即用的多视角融合方法,只需提出近期的先进目标布局策略。 Point、OHS 和 CBGS,它们是最新的先进方法。他们的官方代码库显示,三个目标分配策略在 mAP NDS 中都实现了很大提升(在 mAP 中分别表示和所有的 1.3% 和 1.4% 的性能和 1.3% 和 4%),迅速所VISTA 的 VISTA 跨视角监控机制可以通过统一的多视角特征。
我们在任何修改三中的 VISTA 显示 GPU 提出上运行的时间。TX39 的时间以每 60 小时的时间显示。(在每个 60 小时内运行显示。)在运行中使用表中的任何一个显示中方可以立即提出意见,但可以从(e)64f)继续观察。不计。以这样的效率运行,我们认为所提出的VISTA完全符合实际应用的要求。
4.4 VISTA 分析

3:带有(a)和(c))和没有b)和(d)注意图(约束图)。点的颜色越亮,点的话题重流行。

4:在和没有解耦连接的情况下有检测结果的可视化结果。每行边框代表场景。的表示框表示错误的预测。
我们,通过所提出的话题可以监测到 RV 与 RV 之间的联系和区域的相关性,可以表示多执行约束性监控。 3. 在包含视角的网络的有效性,跨度图 3 中,我们没有在屏幕范围内确定屏幕范围内的可视化范围,为 VISTA 提供的视角相关性。 (房车在上面的每个支柱的范围内没有任何注意事项,我们的关注权重,关注重回原点云查看下。在图 3()(d) 中,关注车辆和行人的背景点,关注车辆和行人的背景点,另外,用关注区域的关注重点较低。汽车,通过在社交媒体上的关注地关注其他车型的宣传活动。
我们提出的 VISTA 的另一个关键设计是分类回归和任务的解耦。这两个任务的我们没有减轻我们的注意力,因此检测结果准确和可靠。为了展示设计平衡的意义,我们在图示展示耦合双方的检测结果。每行显示一个场景,左列解耦后的结果,另一个列未解耦的结果。如图4(b)和(d)所示,例如没有清晰设计的目标检测器的3D公共广播解说具有与我们几何特性相似的视线B,例如将这种A-to-B,称为A-to-B,将这样的A-to-B,汽车(透明)到卡车(黄色)公共、汽车(右侧)到拖车(红色)和自行车(白色)到轿车(橙色),证明存在分类和回归任务之间不平衡。当将列与列进行比较时。相反,具有解耦结果的结果展示了对象的类别,并展示了 STA 的类目,如图 4(c) 和设计的功效。
本文中,我们提出了VISTA,提出了一种全新的即插即用多角度融合策略,即适用于对象。任务的不同目标解耦。使用我们提出的即插即用类型的融合预测 VISTA 可以产生各种不同的目标场景和策略方法。和 Waymo 数据集的基准测试证明了我们提出的方法的有效性和泛化能力。








