绑定手机号
确认绑定









大家好,我是 Jack。
CVPR、SIGGRAPH 等各种计算机视觉的顶级会议,在 6 月份都陆续结束了。
话说,小伙伴们都斩获了几篇论文?
今天继续给大家带来一些有趣的 AI 算法。
根据文字,生成说话的面孔,还能带肢体动作。
比如,输入中文:
我爱你

语言选择韩语,然后选择语速、动作、视频背景。
生成的视频效果:
选择成中文,动作选择伸两只手,我们再看下效果:
也可以输入我们耳熟能详的:

效果是这样的:
再比如:

效果是这样的:
算法支持的语言有:汉语、英语、日语、韩语,从效果看还都挺标准的。
这个算法是一个 CVPR 的最新论文的 Demo 效果,可以在线体验。
体验地址:
https://huggingface.co/spaces/CVPR/ml-talking-face
论文地址:
https://arxiv.org/abs/2205.06421
算法的框架是这样的:
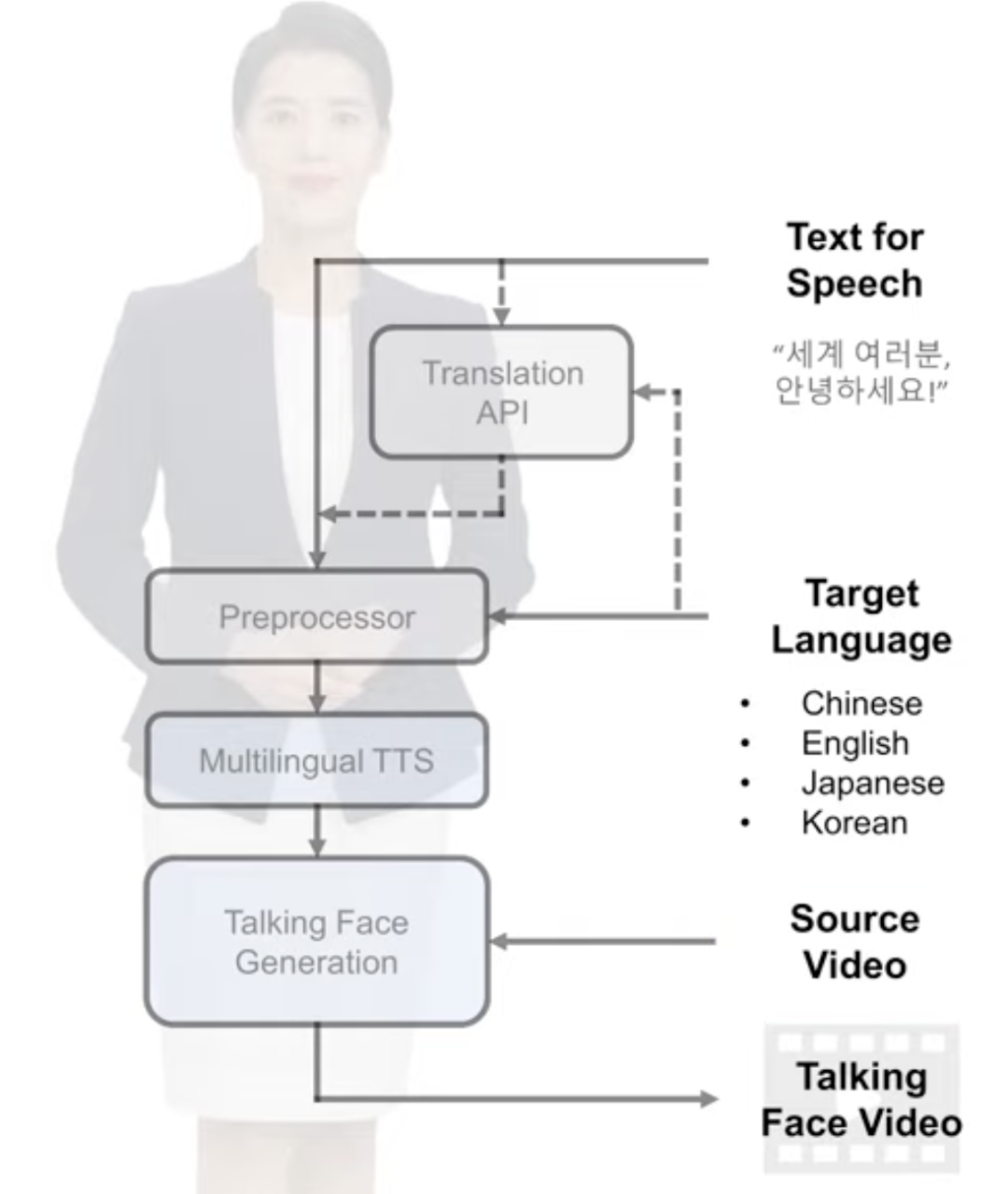
使用谷歌翻译 API 先对输入文字进行翻译,生成目标语言,然后使用 TTS 算法,就是一个 Text-To-Speech 算法,生成对应的音频,再根据音频,生成视频。
音频生成视频的算法,我之前写过,比如 LSP 算法:
不过他们用的不是这个,是一个类似算法 Wav2Lip。
https://github.com/Rudrabha/Wav2Lip
说实话,这套系统逐渐成熟,客服这类的岗位,就会逐渐被代替了。
当然,也要谨防这类技术的诈骗。
比如,眼见为实,耳听为虚已经是过去式了,现在眼见也未必为真。
AI 算法,视频都能给你生成了。
也是一篇顶会的论文,直接上效果:

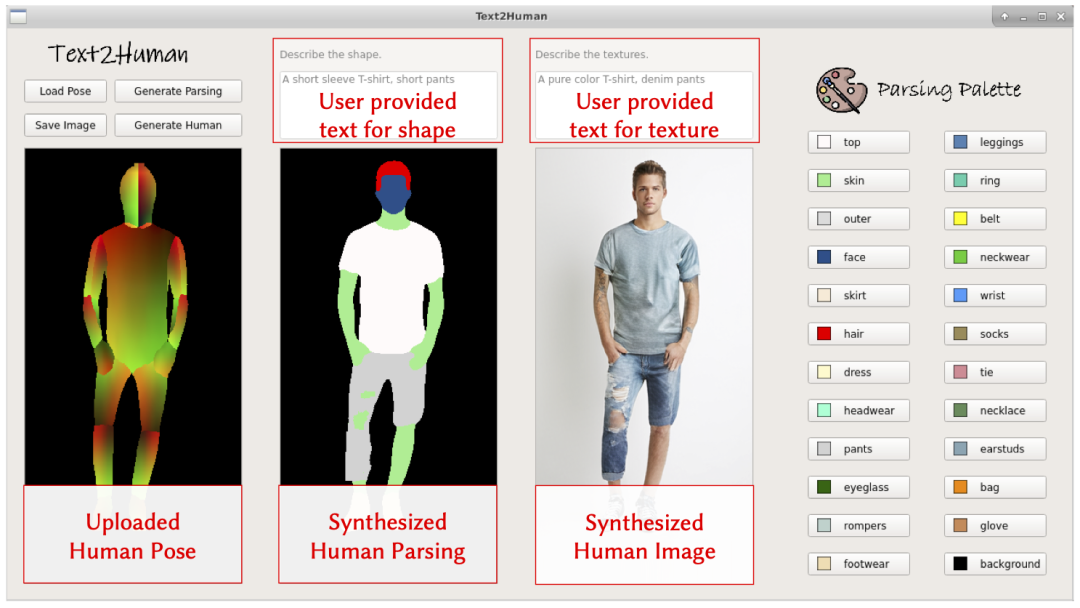
算法如其名,Text2Human。
根据文字描述,生成不同衣着的人。
A man wears a short-sleeve and short rompers with denim meterials.
用法就是:描述一下性别和穿的衣服,算法就能自动生成对应的图片。
可以选择不同的姿态:
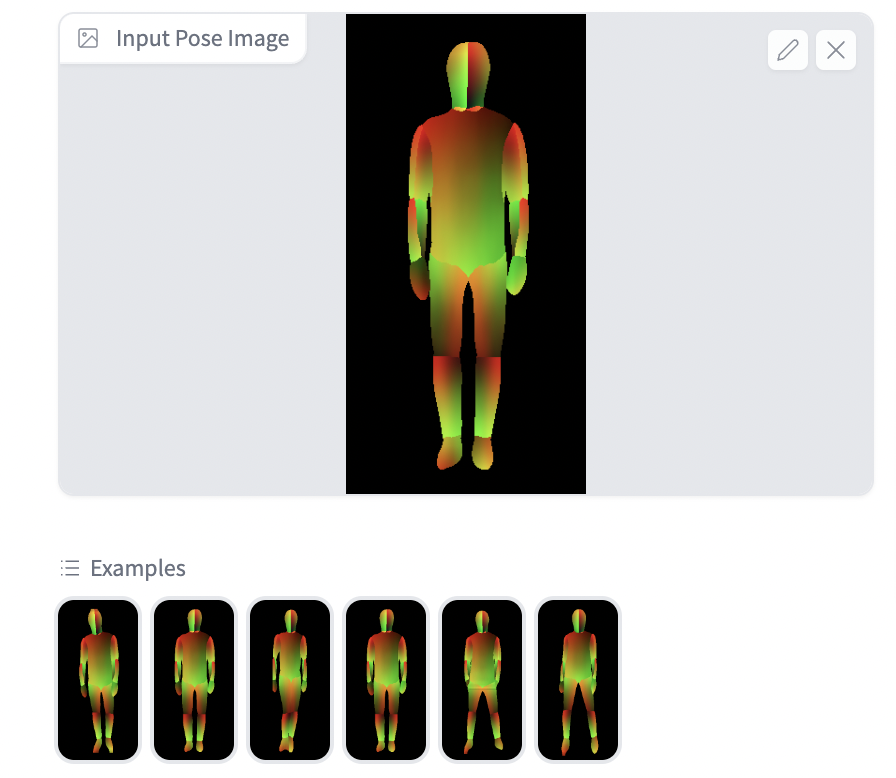
然后输入描述即可生成对应的图片。
这个算法已经开源,作者还做了一个 UI 界面。
项目地址:
https://github.com/yumingj/Text2Human
不过这个需要一些编程基础才能体验,毕竟环境搭建起来也要花费一阵子。
当然,想省事,也可以在线体验:
https://huggingface.co/spaces/hysts/Text2Human
这类算法也挺有意思,扩展一下,就是在线试衣。
将生成的人物照片,指定为固定的人,比如自己。
足不出户,就能使用手机 APP 在线试穿各种衣服。








