绑定手机号
确认绑定









Large Model vs Tiny Model

本文明确指出大模型过拟合,需要通过dropout等正则化技术和数据增强来提升精度;而小模型是欠拟合的,需要增强网络技术,正则化技术对小网络是有害的。
如上图所示ResNet50(大模型)正则化后,精度都有所提升,NetAug会掉点;而MobileNetV2-Tiny(小模型)正则化会掉点,NetAug会提升精度。
Formulation
标准的随机梯度下降公式为:
因为小模型的容量受限,比起大模型更容易陷入局部最优,最终导致不能得到最佳性能。为了提升小模型的精度,就需要引入额外的监督信号(比如KD和multi-task learning方法)。dropout方法鼓励模型的子集进行预测,而本文提出的NetAug则鼓励小模型作为一组大模型的子模型进行预测(这组大模型通过增强小模型的width构建的)。总的loss函数可以写成:
表示一个增强的大模型(包含需要的小模型 ,参数共享), 是缩放系数。
Constructing Augmented Models
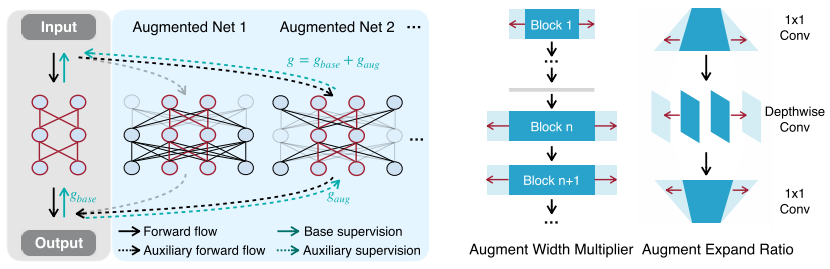
如左图所示,构建一个最大的增强模型(包含需要的小模型,参数共享),其他增强模型从最大增强模型中采样。这种参数共享构建supernet的方式,之前在one-shot NAS中非常流行,详细可以看我之前的文章:https://zhuanlan.zhihu.com/p/74985066。
如右图所示,NetAug通过调整width构建其他增强模型,比起通过调整depth构建增强模型,训练开销更小。构建增强模型引入augmentation factor r和diversity factor s两个超参数,假设我们需要的小模型其中一个卷积宽度是w,最大增强模型的卷积宽度就是rxw,s表示从w到rw宽度之间等间距采样s个增强模型卷积宽度。比如r=3,s=2,那么widths=[w, 2w, 3w]。
训练阶段,NetAug在每个step采样一个增强模型进行辅助训练。NetAug训练额外开销相比baseline增加了16.7%,推理额外开销为0。
1.Effectiveness of NetAug for Tiny Deep Learning

可以看到,NetAug和KD是正交的,可以在KD基础上继续提升性能。
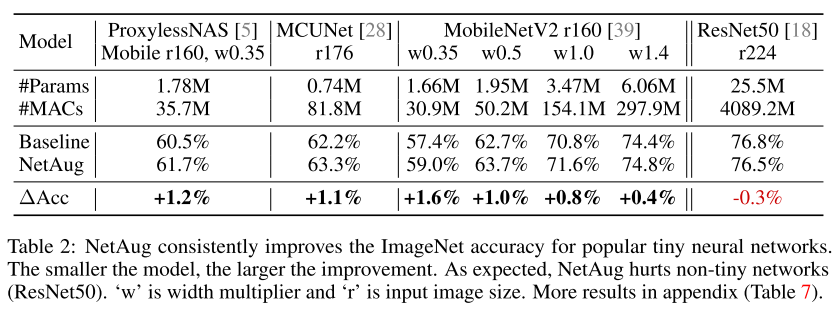
在流行的小模型和NAS模型基础上,NetAug可以继续提升性能,但是对于大模型(ResNet50)来说,NetAug是有害的。
2.Comparison with Regularization Methods
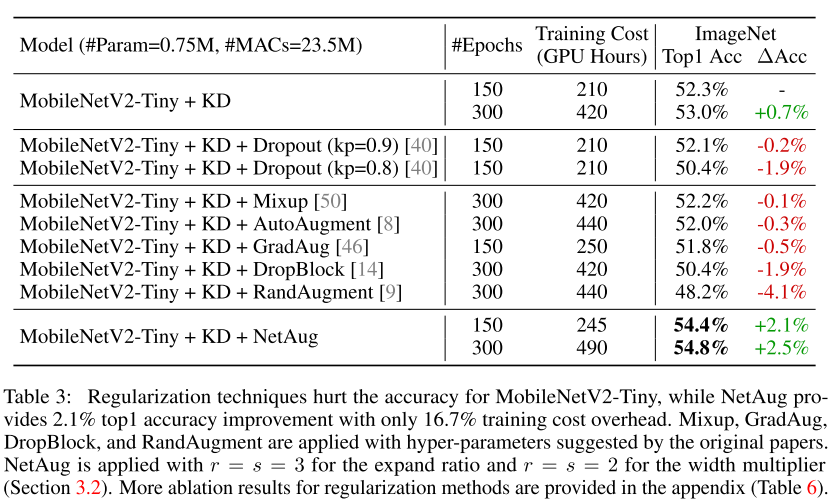
正则化技术对于小模型来说是有害的。
3.Combined with Network Pruning
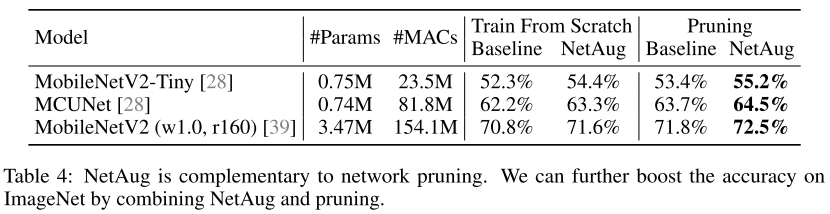
在Pruning的基础上,NetAug也能提升性能。
4.Large Model vs Tiny Model
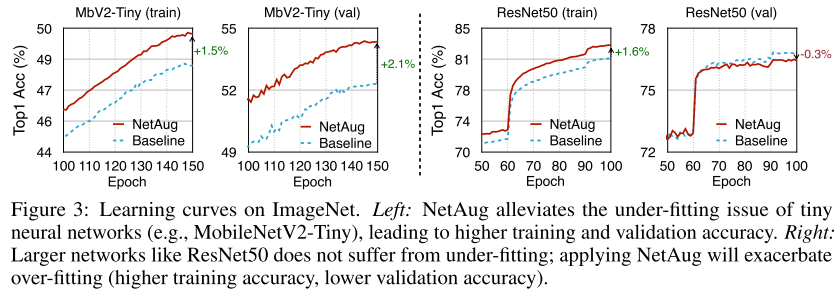
上图清晰的揭示了本文提出的结论,小模型欠拟合,NetAug可以提升性能;大模型过拟合,NetAug是有害的。
5.The Number of Augmented Model
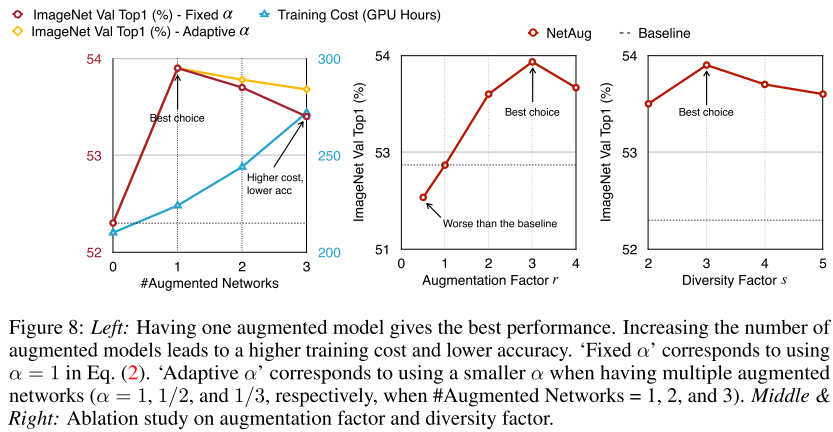
实验表明,每个step采样一个augmented model是最有的,r和s超参数都设置为3最优。
NetAug vs OFA
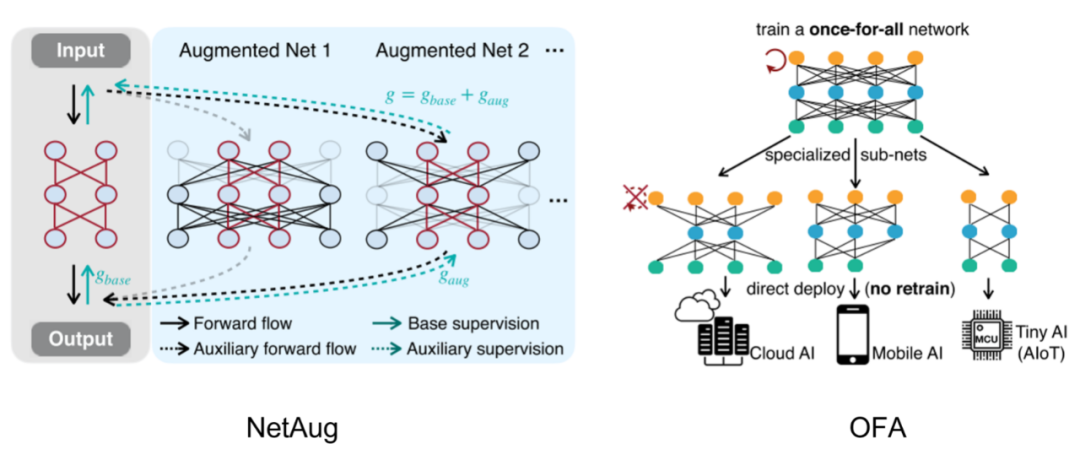
NetAug和之前的OFA非常相似,OFA先构建一个大模型,然后训练这个大模型,最后通过搜索的方式得到小模型。

从上表可以看到,在OFA搜索得到模型的基础上,NetAug还可以继续提升性能,也验证了NetAug可以进行网络增强的作用。
OFA和NetAug其实是一体两面:一个是自上而下通过supernet搜索最好的子网络,另一个是自下而上通过supernet辅助训练小网络。一个是终点未知,找最优终点(类似搜索);另一个是终点已知,增强终点性能(类似动态规划)。
OFA的问题在于,大量的时间资源花费在可能跟最终目的无关的子模型上,而NetAug的优势在于,已知想要的小模型,通过supernet来提升小模型的精度。
小模型欠拟合,需要增加而外的监督信息(NetAug、KD、multi-task learning);大模型过拟合,需要正则化。
NetAug和KD的差别在于,KD是通过outer network来辅助训练(提供信息),而NetAug是通过inner network来辅助训练(共享参数)。
正如标题所言,NetAug(网络增强)是Dropout的反面。
Reference
1.https://zhuanlan.zhihu.com/p/74985066
2.ONCE-FOR-ALL: TRAIN ONE NETWORK AND SPE- CIALIZE IT FOR EFFICIENT DEPLOYMENT
3.NETWORK AUGMENTATION FOR TINY DEEP LEARNING








