绑定手机号
确认绑定










空间卷积被大量应用于当前的视频模型中,它的基本假设是卷积核由所有的时空位置共享。本文作者提出时序自适应卷积(TAdaConv),自适应地对卷积核沿着时间维度进行调整,从而使空间卷积能够进行时序推理,在几乎没有额外计算量的情况下有效提升模型的时序推理能力。相比早期的时序推理方法而言,TAdaConv更为高效,同时还能大大提升模型容量。
实验证明,TAdaConv可以有效地提升已有视频模型在视频分类和时序动作定位上的能力。在Kinetics-400,Something-Something-V2以及Epic-Kitchens-100视频分类任务上,基于TAdaConv构建的TAda2D和TAdaConvNeXt模型均达到了极具竞争力的性能。
此外,作为一种高效引入时序上下文的方式,该文提出的时序自适应卷积TAdaConv也在视频分类意外的任务得以应用。在CVPR 2022 TCTrack: Temporal Contexts for Aerial Tracking中,TAdaConv被拓展为Online-TAdaConv,并被展示可以被用于目标跟踪网络来提取带有时空上下文的特征,从而提升目标跟踪器的性能。
卷积是当前深度视觉模型中至关重要的一个操作,它助力了许多卷积模型在大量视觉任务上取得SOTA的性能。在视频分类模型中,相比于直接对时空信息进行建模的3D卷积而言,2D空间卷积和1D时序卷积的组合由于他们的高效性而更为广泛使用。尽管如此,1D时序卷积仍然在2D空间卷积的基础上带来了不可忽视的额外计算开销。因此,本文尝试直接为空间卷积赋予时序推理的能力。
由于卷积的局部连接和权重共享机制,卷积具有平移不变性。近期关于动态卷积核的研究发现,这种严格的权重共享可能对于复杂空间内容的建模是不利的。
本文提出假设,放松时序上的时序不变性(temporal invariance)可以增强卷积的时序建模能力。基于该假设,作者提出时序自适应卷积(TAdaConv)来代替传统视频模型中的卷积,并分别基于ResNet和ConvNeXt构建高效的视频模型TAda2D以及TAdaConvNeXt。
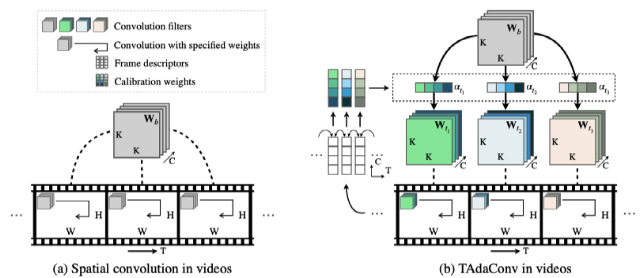
对于空间卷积而言,时序不变性体现在空间卷积的权重在视频的每一帧中是共享的。因此,要放松时序上的不变性,TAdaConv在不同的视频帧中使用不同的卷积权重(如下图所示)。
|
图注:标准的空间卷积与TAdaConv的对比
具体地,TAdaConv将每一帧的卷积核 分解为一个基权重(base weight)和一个校准权重(calibration weight)的组合:
分解为一个基权重(base weight)和一个校准权重(calibration weight)的组合:
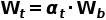
其中基权重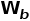 由所有视频帧共享,而校准权重
由所有视频帧共享,而校准权重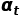 则根据输入自适应地生成。
则根据输入自适应地生成。
这么做有三点好处:
第一,TAdaConv可以是即插即用的,并且模型的预训练权重可以仍然被保留和利用;
第二,由于校准权重的存在,卷积的时序推理能力得以增强,空间卷积被赋予时序推理能力;
第三,相较时序卷积而言,由于时序卷积是在特征图上的操作,而TAdaConv是在卷积核上的操作,TAdaConv更加高效。
为了使模型能够更好地对复杂的时序关系进行建模,关键的点在于校准权重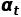 的生成过程。TAdaConv使用的校准权重生成过程可以参考下图。
的生成过程。TAdaConv使用的校准权重生成过程可以参考下图。
作者认为,校准权重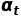 的生成不仅需要考虑到当前帧
的生成不仅需要考虑到当前帧 ,还需要考虑到它的时序上下文
,还需要考虑到它的时序上下文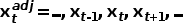 。其中,时序上下文可以被分文局部的时序上下文和全局的时序上下文。为了这个生成过程的高效性,校准权重基于帧描述子(frame descriptor)
。其中,时序上下文可以被分文局部的时序上下文和全局的时序上下文。为了这个生成过程的高效性,校准权重基于帧描述子(frame descriptor) 而不是帧特征来进行生成。在帧描述子的基础上,局部的时序上下文通过两个1D卷积进行完成:
而不是帧特征来进行生成。在帧描述子的基础上,局部的时序上下文通过两个1D卷积进行完成:
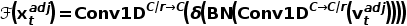
全局的上下文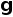 则是通过一个线性映射(FC)叠加到帧描述子上:
则是通过一个线性映射(FC)叠加到帧描述子上:

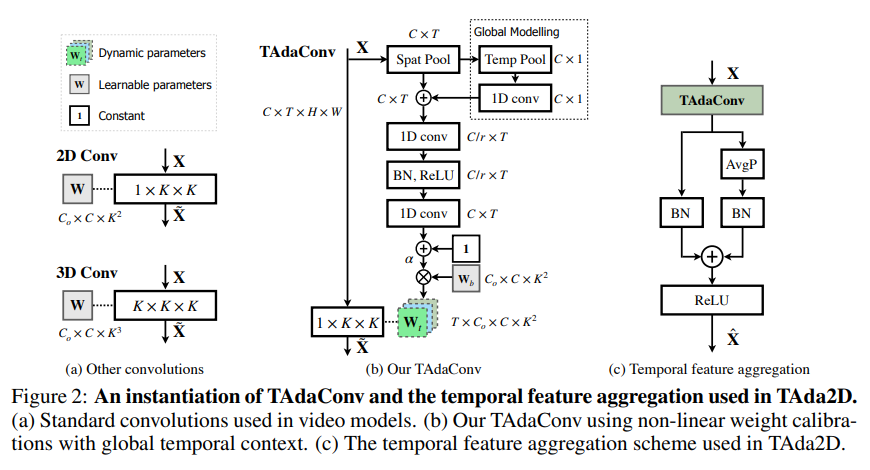
相对于已有的动态卷积方法,为了能更好地利用预训练的权重,作者精心设计了TAdaConv校准权重的初始化,以保证在初始状态下,TAdaConv完全保留预训练的权重。具体地,在校准权重生成函数初始化的时候,最后一层1D卷积的权重被初始化为全零,并且加上了一个1以保证全1的输出:

这样在初始状态下,动态卷积的权重 与预训练的载入的权重
与预训练的载入的权重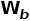 相同。
相同。

对比(2+1)D Conv,TAdaConv在操作层面和模型层面均有明显的计算量和参数优势。
此外,作者还基于平均池化提出了一种时序信息聚合的方式:
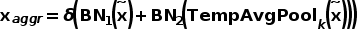
4.1 假设验证
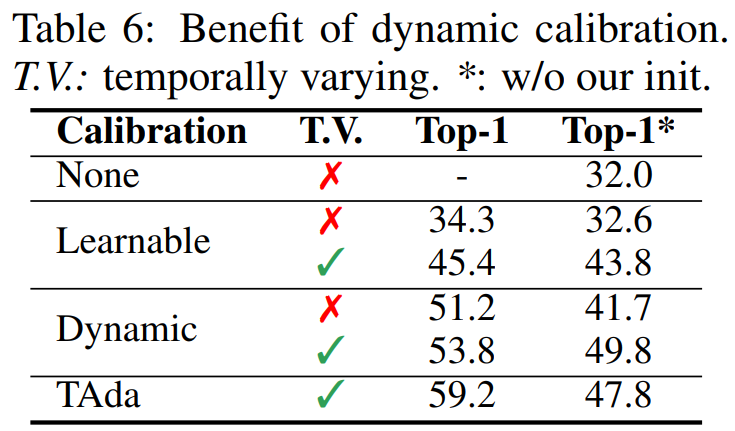
对比不同的校准权重,作者验证放松时序不变性有益于时序建模,动态校准权重比可学习校准权重更好,以及TAdaConv的校准方式性能最优。
4.2 Plug-in evaluation

将TAdaConv插入已有的视频分类模型中,可以在Kinetics-400上提升约1.3%,在Something-Something-V2上提升约2.8%。
4.3 消融实验

校准权重的生成中,同时考虑局部和全局的时空上下文的校准方式性能最佳,在此基础上加入时序信息的聚集,可以在基线TSN的基础上达到31.8%的提升。
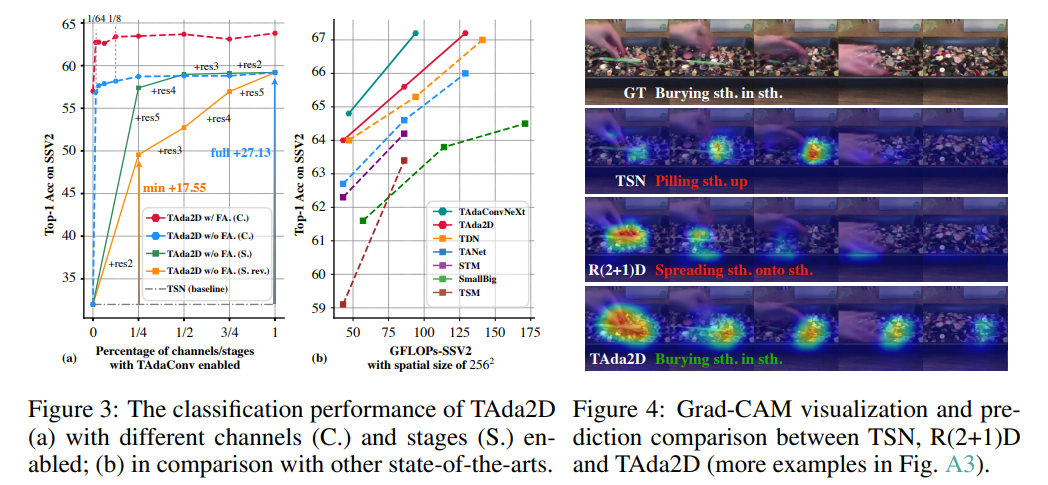
相比已有的视频模型,TAda2D和TAdaConvNeXt达到了最优的性能和计算量的tradeoff。
4.4 Action classification

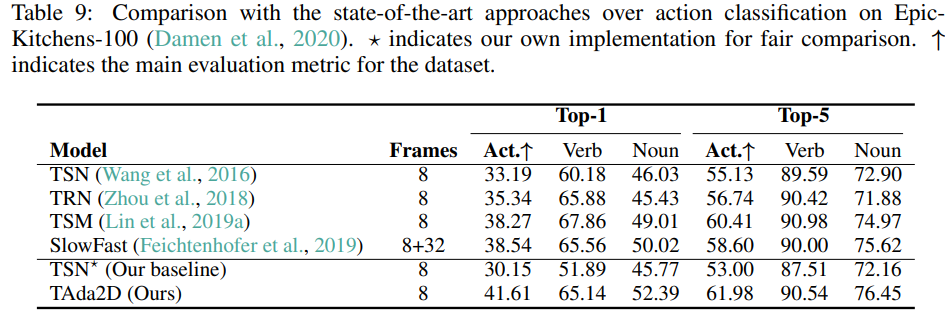
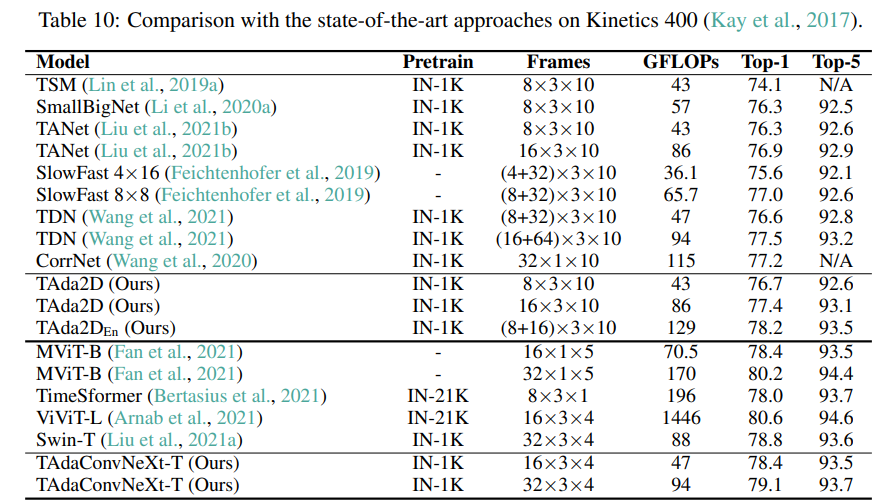
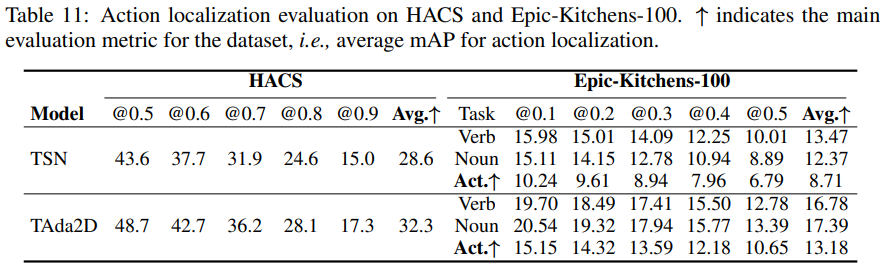
4.5 Action localization
总结
本文作者提出了时序自适应卷积(TAdaConv),基于局部和全局时序上下文动态地为每一帧的卷积权重进行调整。TAdaConv均可以独立构建网络,也可以作为即插即用的操作来提升网络时序建模的能力。在动作识别和定位任务上,TAda2D和TAdaConvNeXt展现了优越的时序推理性能。