绑定手机号
确认绑定










arXiv:https://arxiv.org/pdf/2112.10175.pdf
code: https://github.com/fenglinglwb/EDT
预训练在在不同high-level CV任务中取得了大量的SOTA结果,但是,图像处理系统中的预训练的作用却鲜少得到探索与挖掘。
本文针对图像预训练进行了深入研究,首先提供了一个广义且高效Transformer用于图像处理。在有限参数与计算复杂度约束下,所提方案取得了极具竞争力的结果。基于该框架,我们设计了一整套评估工具以全面评估不同任务下的图像预训练,挖掘其关于网络内部表达的影响。
我们发现:预训练在不同low-level任务中起不同的作用。比如,在超分任务中,预训练可以为更高层引入更多局部信息,进而产生显著性能提升 ;与此同时,预训练几乎不会影响降噪网络的内部特征表达,故而产生了轻微的性能提升。更进一步,我们还探索了不同的预训练方法并证实:多任务预训练更有效且数据高效 。
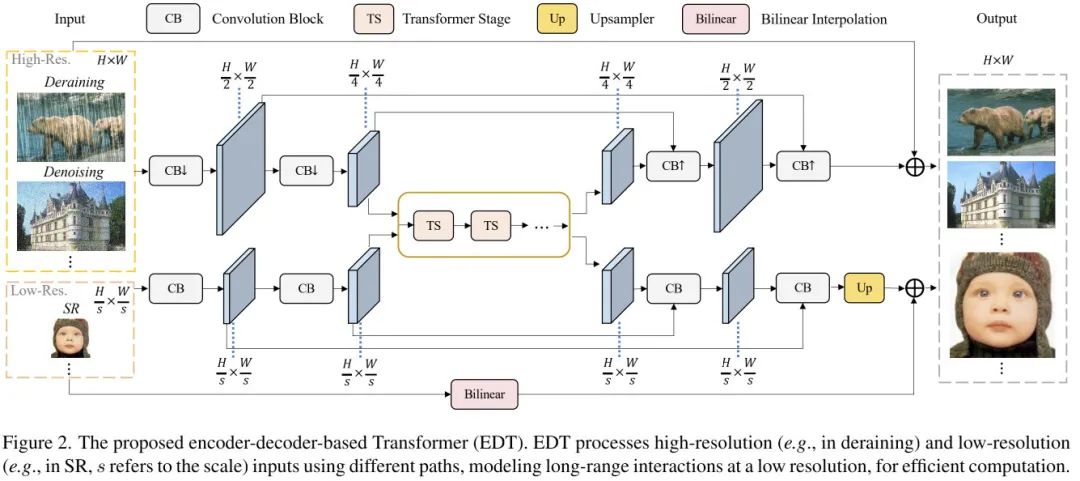
上图给出了本文所提EDT架构示意图,它由基于卷积的轻量编解码模块与基于Transformer的body模块构成。
尽管Transformer取得了极大成功,但高计算复杂度使其难以处理高分辨率输入。为提升编码效率,图像首先通过stride卷积下采样到1/4尺寸(仅限于高分辨率输入的任务,比如降噪、去雨;而对于超分则无需该预处理);在编码器的尾部后接Transformer模块以更少的计算量达成更大的感受野;最后我们对所得特征进行上采样重建。此外,我们还在编码器与解码器之间构建了跳过连接以促进更快的收敛。
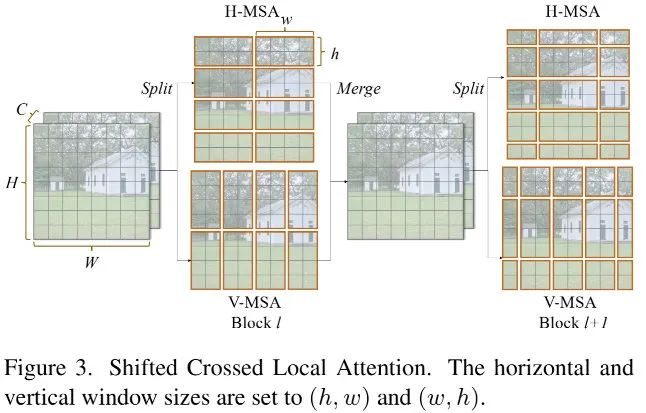
关于Transformer模块,作者在SwinT基础上改进而来。上图给出了本文所设计的Shifted Crossed Local Attention示意图,它将输入特征均匀拆分为两部分,分别沿水平/垂直方向计算MSA。可以描述如下,更详细的介绍建议查看SwinT一文。
为消除窗口划分可能导致的块效应,我们设计了一种Anti-FFN,描述如下:
注:Anti-Block是一个
的深度卷积。最后上表给出了不同复杂度EDT的网络参数信息,见下表。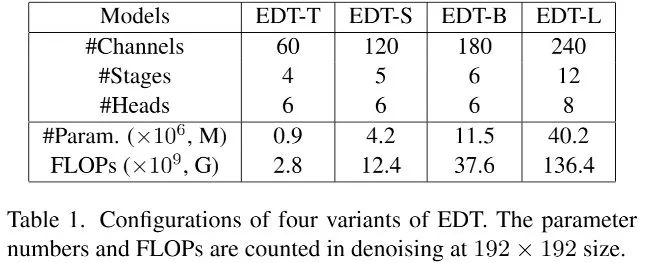
类似IPT,我们采用ImageNet数据集进行预训练;在任务方面,我们选择了超分、降噪以及去雨三个代表性任务。总而言之,x2/x3/x4三个倍率超分、15/25/50三个噪声水平的降噪以及light/heavy两种去雨。
我们探索了三种预训练方法:
单任务:对特定任务训练单个模型;
相关任务:为几个高度相关的任务训练一个模型(如x2/x3/x4超分);
不相关任务:对不相关的任务训练一个模型(如超分与降噪)
我们引入CKA对网络隐层特征相似性进行研究以支撑跨网络定量对比,定义如下:
其中HSIC表示Hilber-Schmidt Independence Criterion。CKA具有正交变换不变性、各向同性扩展不变性,因此,我们可以进行网络表达的有价值分析。
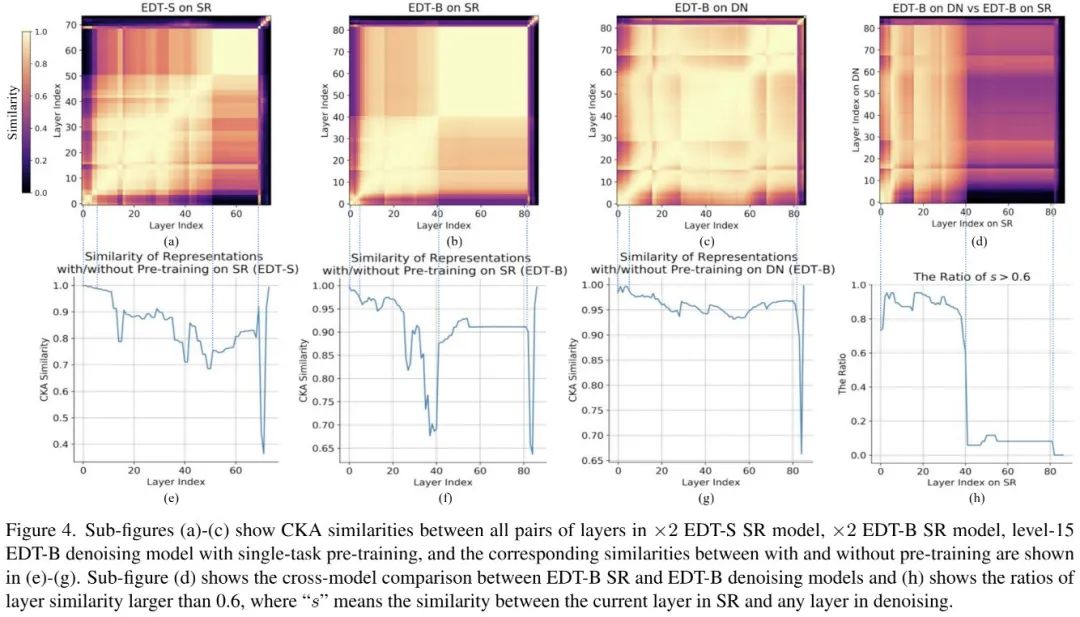
总而言之,我们可以得出以下几个发现:
SR模型呈现出清晰阶段性内部表达,且每个阶段随模型大小而变化;而降噪模型则呈现出相对均匀结构;
降噪模型与SR模型的低层具有更强相似性,包含更多的局部信息;
单任务预训练主要影响SR模型的高层特征,而对降噪模型影响有限。
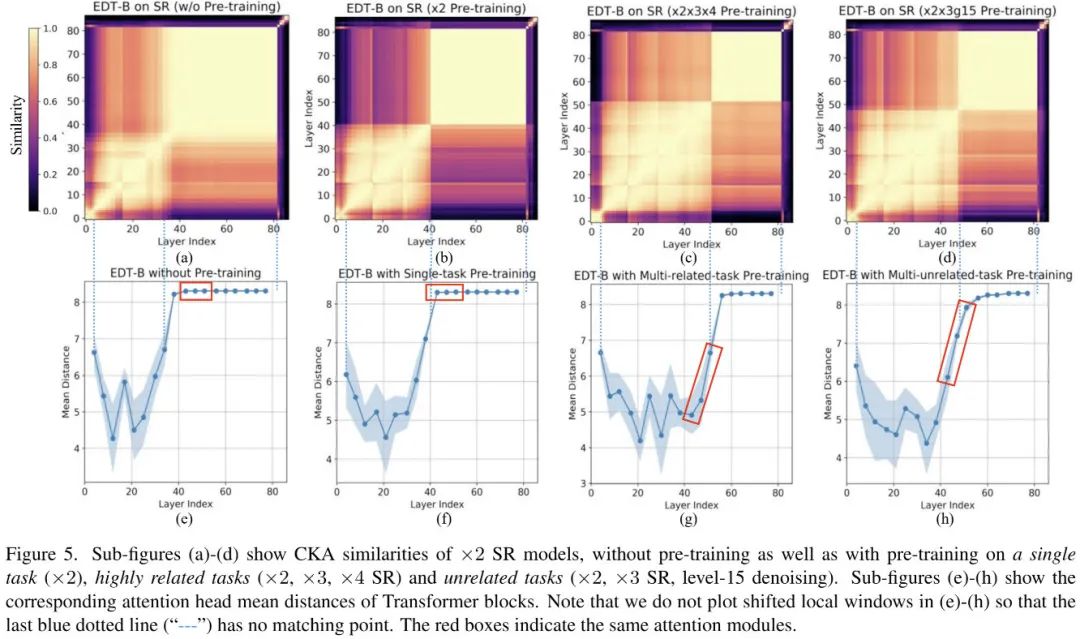
从上图可以得出如下几个关键发现:
SR模型的低层包含更多局部信息,高层包含更多全局信息;
通过引入不同程度局部信息,三种预训练方法均可大幅提升模型性能。
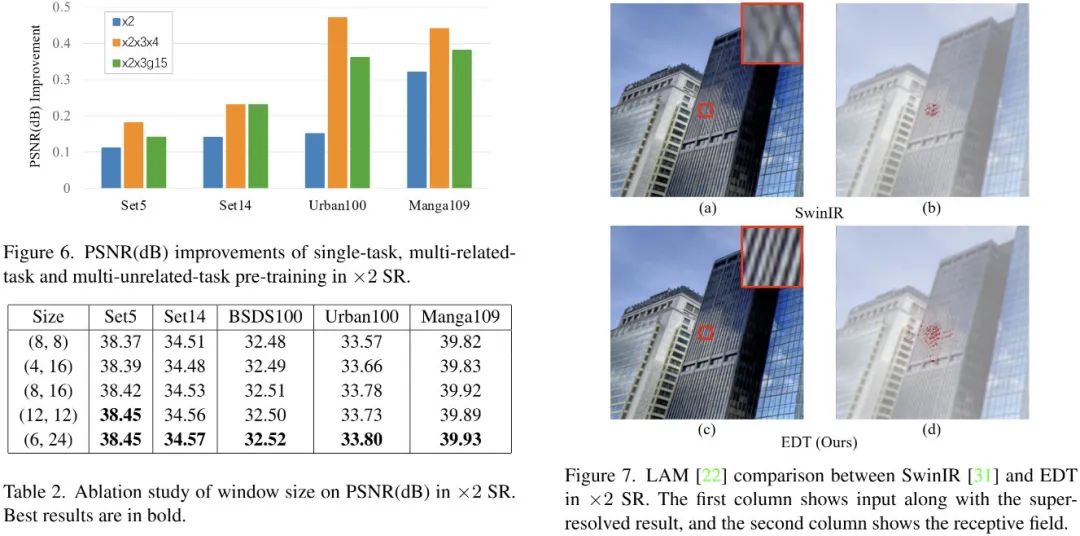
首先,我们先来看一下关于窗口尺寸的消融实验,结果见上图。从中可以看到:
当窗口尺寸到8提升到12,模型性能可以得到大幅提升,验证了大感受野的重要性;
对比(4,16)与(8,16)可以看到:更大的短边具有更优的性能;
对比(6,24)与(12,12)可以看到:相同面积下,(6,24)性能更佳。
此外,结合LAM,从上图Figure7可以看到:相比SwinIR,所提方案可以利用更宽范围的信息,复原更多细节。
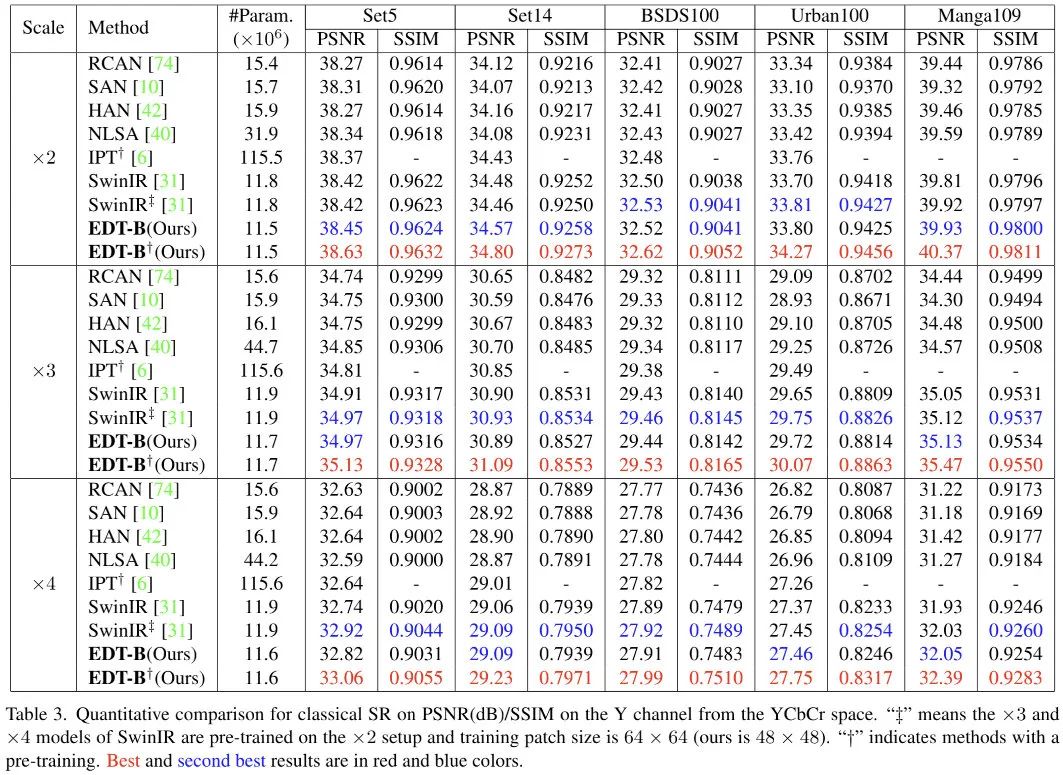
上表给出了经典超分的性能对比,从中可以看到:
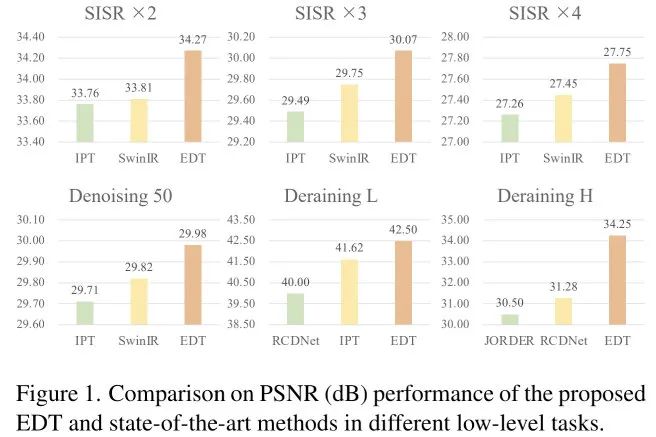
在所有尺度超分任务上,EDT均取得了SOTA指标;
在Urban100与Manga109测试集上,EDT取得了0.46dB与0.45dB指标提升;
甚至无需预训练时,EDT-B仍比SwinIR高0.1dB指标。
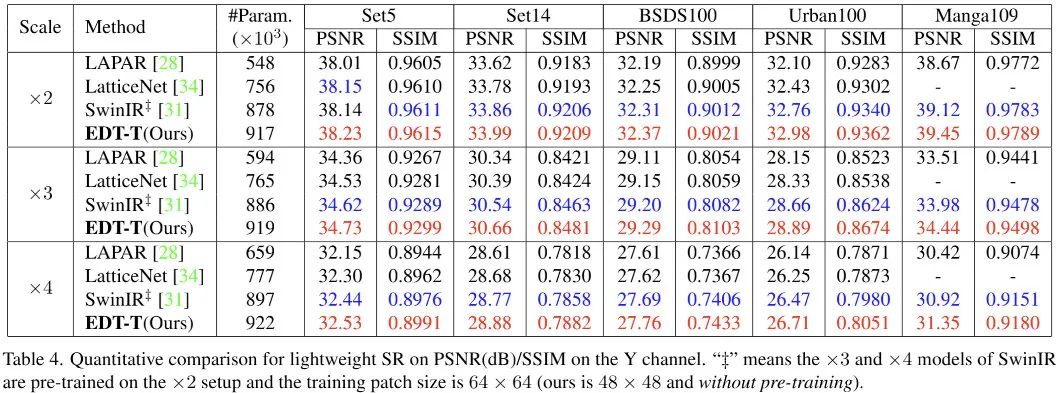
上表给出了轻量超分的性能对比,从中可以看到:
在所有基准数据集上,所提EDT均取得了最佳性能;
尽管SwinIR采用更大的块训练,EDT-T仍具有比起高0.2dB~0.4dB的性能。

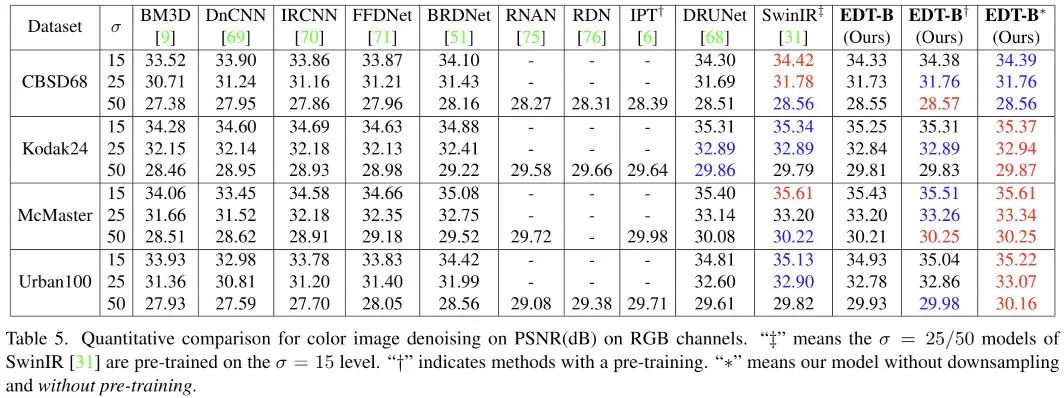
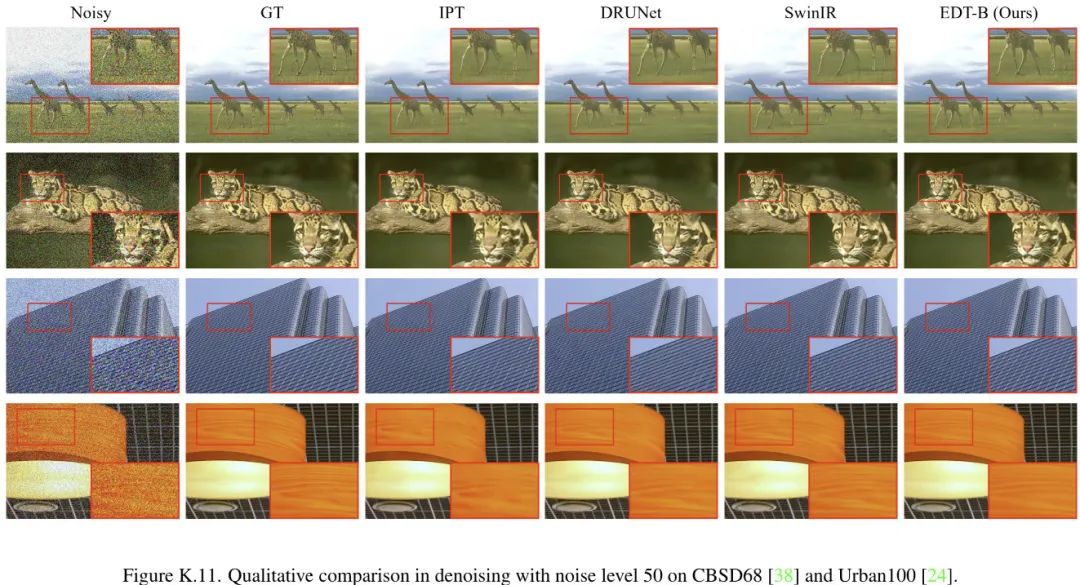
上表给出了降噪任务上的性能对比,可以看到:
不同于SR受益于预训练良多,降噪模型仅从预训练受益0.02-0.11dB;
EDT架构在高噪声水平表现更好,而在低噪声水平表现稍差;
移除Encoder部分的下采样后,在低噪声水平表现同样更佳。
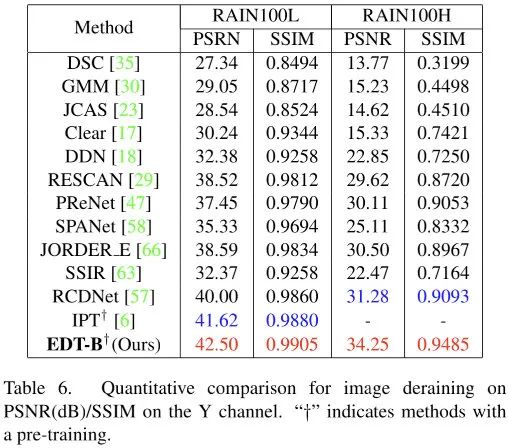
上表给出了去雨任务上的性能对比,可以看到:
相比IPT,在light rain任务上,EDT-B取得了0.9dB的指标提升,同时参数量仅需10%;
相比RCDNet,在heavy rain任务上,EDT以2.97dB绝对优势胜出。









