绑定手机号
确认绑定









新华社北京2022年2月17日电,记者了解到,国家发展改革委、中央网信办、工业和信息化部、国家能源局近日联合印发文件,同意在京津冀、长三角、粤港澳大湾区、成渝、内蒙古、贵州、甘肃、宁夏启动建设国家算力枢纽节点,并规划了张家口集群等10个国家数据中心集群。至此,全国一体化大数据中心体系完成总体布局设计,“东数西算”工程正式全面启动。
当前,算力已成为全球战略竞争新焦点,是国民经济发展的重要引擎,全球各国的算力水平与经济发展水平呈现显著的正相关。在2020年全球算力中,美国占36%,中国占31%,欧洲和日本分别占11%及6%。近年来,美国、欧洲、日本纷纷制定行动计划,不断运用算力助推经济增长。
“数据、算法、算力”是数字经济时代核心的三个要素,其中算力是数字经济的物理承载。这里,我们通过“预见·第四代算力革命”系列文章(共四篇),从微观到宏观,详细分析跟性能和算力相关的各个因素以及主流的算力平台,尽可能地直面当前算力提升面临的诸多挑战和困难,展望面向未来的算力发展趋势。这四篇文章为:
预见·第四代算力革命(四):宏观算力建设。
本文为第四篇,欢迎关注公众号,阅读历史以及后续精彩文章。
参考文献
https://www.redhat.com/zh/topics/edge-computing,了解边缘计算,Redhat官网
https://www.intel.cn/content/www/cn/zh/edge-computing/what-is-edge-computing.html,什么是边缘计算?,Intel中国官网
https://segmentfault.com/q/1010000005032608,segmentfault,有人能通俗的解释下cdn是项什么技术?起什么作用?
https://mp.weixin.qq.com/s/vqoxYzGmYRz-yS1KwBAbCA,算力网络,前景如何?,石青山,“通信网工小兵”公众号
https://wccftech.com/nvidia-atlan-soc-unveiled-with-next-gen-arm-based-grace-cpu-ampere-next-gpu-cores/, NVIDIA Atlan SOC Unveiled With Next-Gen ARM Based Grace CPU & Ampere Next GPU Cores
https://developer.aliyun.com/article/791082,云计算MSP行业调研报告
https://wap.peopleapp.com/article/6523652/6404443,“东数西算”工程正式全面启动
我们回顾一下,在《预见·第四代算力革命》的第一篇里介绍的公式:
实际总算力 = (单个处理器的)性能 x 处理器的数量 x 利用率
简单来说,在微观算力,我们关注的是单个处理器的性能;而在宏观算力方面,我们关心两个关键因素:规模和利用率。
规模有两个方面的含义:
一个是处理器能支撑起大规模。这在《预见·第四代算力革命》的第二篇和第三篇里都有介绍,处理器只有做到足够通用、灵活、可编程,才能够被大规模采用。
第二,就是,需要更多的云、边、端计算设备。我们要建设更多的超大规模云数据中心,更多的边缘数据中心,以及更多的高性能的终端智能设备。
云计算通过资源整合和共享,用户按需购买,快速而弹性的获取计算资源,提升计算资源的利用率,进一步降低用户获取算力的成本。
云计算是集中的计算,为了减轻云计算的处理和存储压力,同时给终端更低延迟的服务,于是有了边缘计算。
云计算是集中式的,算力利用率高;边缘计算是分布式的,算力利用率相对要低一些。于是,这些年有了“超云(云MSP实现跨云和混合云模式,我们定义为超云)”、“分布式云”和“算力网络”等技术进一步整合各种异质的算力,进一步提高算力利用率。
云计算出现之前,部署一套互联网系统,一般有两种方式:小规模的时候,自己购买物理的服务器,然后租用运营商的机房;超过一定规模的时候,就需要自己建机房,租用运营商的网络,自己运维数据中心的软件和硬件。
这个时候的算力资源是一个个孤岛,整个业务的模式也非常之重,成本很高而且弹性不足。如果算力资源配置比较多,就意味着资源浪费和利用率低;如果算力资源配置比较少,就意味着无法支撑业务的发展,丢失关键的商业机会。
云计算通过互联网按需提供IT资源,并且采用按使用量付费的方式。用户可以根据需要从云服务商那里获得技术服务,例如计算能力、存储和数据库,而无需购买、拥有和维护物理数据中心及服务器。云服务使用多少支付多少,可以帮助用户降低运维成本,用户可以根据业务需求的变化快速调整服务的使用。云计算相比传统IT资源配置方式有如下优点:
费用。无需在购买硬件和软件,以及设置和运行数据中心上,进行资金投入。
速度。大多数云计算服务通过自助服务提供,通常只需点击几下鼠标,即可在数分钟内按需调配海量计算资源,企业不需要考虑容量规划。
弹性。云计算的优点包括弹性扩展能力,这意味着能够在需要时从适当的地理位置提供适量的IT资源,例如增加或减少计算能力、存储空间、网络带宽等。
工作效率。数据中心具有大量服务器,这意味着具有非常多的硬件维护、硬件设置、软件补丁和其他费时的IT管理事务。云计算完成了这些任务中的绝大部分工作量,让用户可以把时间精力用来实现更重要的业务目标。
性能。云计算服务通过全球网络运行在分布于全球各地的安全数据中心,会定期升级网络硬件,使网络时刻保持快速和高效。与单个企业数据中心相比,它能提供多项好处,包括降低应用程序的网络延迟和提高缩放的经济性。
可靠性。云计算能够以较低费用,并且非常简单地完成数据备份、灾难恢复和实现业务连续性。
安全性。许多云服务商都提供了广泛地用于提高整体安全情况的策略、技术和控件,这些有助于保护数据、应用和基础设施避免潜在的威胁。
敏捷性。在云中,用户可以轻松使用各种技术,从而可以更快地进行创新,并构建几乎任何可以想象的产品。用户可以根据需要快速启动资源,从计算、存储和数据库等基础设施服务到物联网、机器学习、数据湖和分析等。用户也可以在几分钟内部署技术服务,并且从构思到实施的速度比以前快了几个数量级。这使的用户可以自由地进行试验,测试新想法,以打造独特的用户体验。
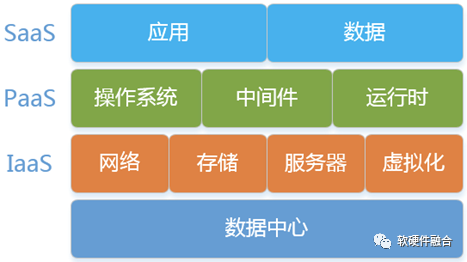
云计算服务是基于分层的结构,分为三大类:
IaaS层(Infrastructure as a Service,基础设施即服务):IaaS层包含云IT的基本构建块。它通常提供对网络功能、计算机(虚拟或专用硬件)和数据存储空间的访问。IaaS层服务为用户提供高级别的灵活性,让用户可以对IT资源进行管理控制。它与许多IT部门和开发人员熟悉的现有IT资源最为相似。
PaaS层(Platform as a Service,平台即服务):PaaS层服务让用户无需管理底层基础设施(一般是硬件和操作系统),从而可以将更多精力放在应用程序的部署和管理上面。这有助于提高效率,用户不用关心资源购置、容量规划、软件维护、补丁安装或与应用程序运行有关的各种繁重工作。
SaaS层(Software as a Service,软件即服务):SaaS层服务提供完善的产品,其运行和管理皆由服务提供商负责。在大多数情况下,人们所说的SaaS指的是最终用户应用程序。使用SaaS产品,用户无需考虑如何维护服务或管理基础设施,只需要考虑如何使用该特定软件。
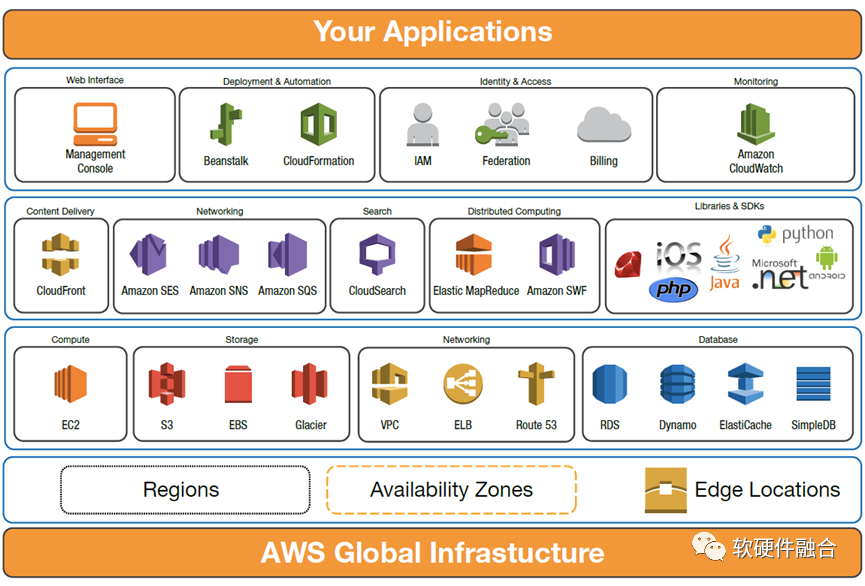
跟底层硬件最相关的是IaaS层的服务,PaaS层、SaaS层的服务都是基于IaaS层的基础服务构建的更高层的服务。亚马逊AWS是全球最大的云计算厂家,我们以AWS的服务体系为例,AWS最基础的IaaS层核心服务有:
计算类:EC2(Elastic Compute Cloud,弹性计算云主机服务)。EC2的类型包括:通用型、计算优化型、内存优化型、存储优化型、异构加速(GPU/FPGA/DSA)型。
存储类:本地存储、EBS(Elastic Block Store,弹性块存储服务)、S3(Simple Storage Service,简单对象存储服务)、Glacier(冰川,AWS的归档存储服务)。
网络类:VPC(Virtual Private Cloud,虚拟私有网络);ELB(Elastic Load Balancing,弹性负载均衡)。
数十亿物联网和移动设备产生的数据和对服务的访问呈指数级增长;与此同时,自动驾驶等场景对服务的实时性要求很高;并且,设备规模和数据量均呈几何式增长。场景的量变推动着计算模型的质变,传统集中式的云计算在向分布式的边缘计算转变。在这种模式下,部分计算和存储发生在网络边缘,也即更靠近终端的位置。
云端架构面临的挑战主要包括:
延迟。更多行业应用需要快速分析和响应,仅靠云计算无法满足要求,因为数据源的网络距离产生了延迟,导致低效、时间延迟和较差的用户体验。
带宽。增加传输带宽和处理性能可以解决延迟问题。但是,继续增加网络中的设备数量以及单个设备访问的数据量,在终端和云端数据传输的成本可能会达到不可承受的水平。
安全与隐私。在边缘侧保护私人医疗记录等敏感数据的安全,并减少通过互联网传输的数据,有助于降低数据被截获的风险,从而提高安全性。
连接性。众多的终端设备可能由于功率的原因,无法持续接入云计算,庞大的终端数量和频繁的连接请求,会给云计算服务造成非常大的压力。通过边缘计算设备把数据和访问汇聚到一起,再通过边缘设备接入云计算的集中服务。
人工智能。由于存在近乎实时的数据分析需求,需要近数据源的、高算力的人工智能推理来加快数据处理。
分布式的边缘计算可以作为集中式云计算的补充,用于以下的典型场景:
计算密集型工作负载;
数据聚合与存储;
人工智能/机器学习;
协调跨地区的运维;
传统后端处理;
自动驾驶汽车;
增强现实/虚拟现实;
智慧城市。
边缘计算还可以从数据源头近乎实时地解决问题。简而言之,凡是在减少延迟和/或进行实时处理且可以支持业务目标的地方,都有边缘计算的用武之地。
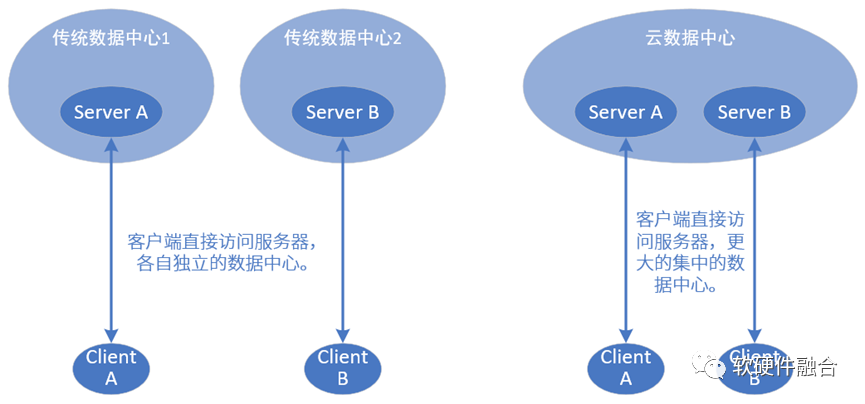
云计算之前的传统数据中心,从宏观的看,是一个个服务的孤岛。云计算把这些孤岛集中到一起,实现了规模化和资源效率的进一步提升。如今,历史轮回,边缘计算,又回到了分布式的(相对)小规模的数据中心。那么,边缘计算和云计算出现之前的自建数据中心有什么区别?
在讲区别之前,我们先了解一个非常典型的一个云服务:CDN。CDN的全称是Content Delivery Network,即内容分发网络。用户可以就近获取需要的内容,解决Internet网络拥挤的状况,提高用户访问的响应速度。

假设你有一个网站,放在自己北京的服务器上给用户浏览,而用户分散在全国甚至全世界各地,那么广州的用户访问网站会比较慢,美国的用户访问则会更慢。
然后采用了CDN技术(购买现有的CDN服务或者自己搭建),同样服务器依然在北京,但是用户访问的话并不是直接访问原始服务器,而是访问CDN服务器。广州的用户访问广州CDN服务器,美国用户访问美国CDN服务器。CDN服务器首次访问时,会缓存源服务器内容到本地。
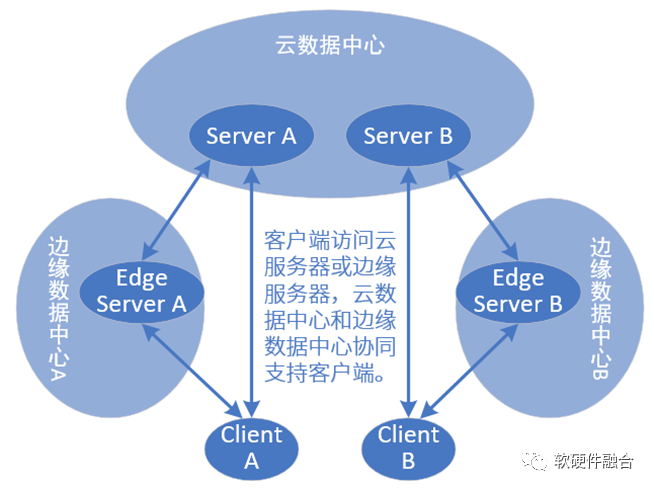
边缘计算,跟CDN是类似的原理。不过CDN通常是把一些静态的资源从服务器拉到本地,CDN服务器是中心服务器的镜像。而边缘计算的功能,要比CDN丰富地多:
边缘计算则是直接从远端接管整个服务,直接服务客户端。然后把最终的交互结果汇聚好之后定期跟云服务器同步。
客户端直接访问边缘服务器,数据送到边缘服务器处理,然后响应和一些控制信息等再传给客户端。这样,就不需要所有客户端直连云服务器,减轻云端服务器的压力。
最关键的一点,需要做到,客户端对上层的服务位置变化无感,以为自己依然访问的是云服务器,以为自己的数据依然上传到云服务器。
“历史在轮回,更是在螺旋式上升”。我们可以看到,边缘计算和传统的独立数据中心是完全不同的两个概念,其区别在于:传统数据中心完全是个孤岛,而边缘数据中心则是和云边协同服务,共同服务终端。

在自动驾驶汽车领域,从NVIDIA发布的自动驾驶芯片平台和未来发展路线图可以看出:
其在2018年发布的Parker平台算力达到1 TOPS;
2020年发布的Xavier平台算力则高达30 TOPS;
按照规划,将于2022年发布的Orin平台算力达到惊人的254 TOPS;
而预计于2014年发布的Atlan平台算力则高达1000 TOPS,其目标是能够用于L4和L5自动驾驶。

从上图中,我们也可以清晰的看到,NVIDIA 下一代自动驾驶Atlan芯片主要是由CPU+GPU+DPU三部分的算力构成,是一个算力强劲的超大“SOC”。
Gartner在2019年初发布了第一版公有云MSP的魔力象限,定义了MSP应该具有的能力:MSP应该在超大规模IaaS提供商方面拥有深厚的技术专长,拥有功能强大的云管理平台(Cloud Management Platform,CMP),尽可能利用自动化的托管服务,能够交付针对云优化的解决方案。不管客户在部署新的云原生应用程序,还是从现有的传统数据中心迁移原有的工作负载。
通俗易懂的说,MSP对接一家或者多家公有云服务厂商,为企业提供上云、开发、迁移、代管、运维等专业服务。因为,即使AWS这样的全球顶级云服务器商,也会出现大面积的网络故障。所以,MSP通常采取多云策略,多云可以满足企业的灾备和服务的完全高可用;多云还给企业带来成本上的优势;此外,多云还可以把企业自己的私有云也加入MSP管理,形成混合云。
站在算力的角度,云计算通过集中式的规模化的数据中心,以及虚拟化技术和多租户机制,在提升算力规模的同时提升算力的利用率。通过MSP,可以在更高的层次、更大的规模,实现跨云运营商的资源整合,可以更进一步地提升资源利用率。
Garnter发布的2021年顶级战略技术趋势时,将分布式云(Distributed Cloud)列为云计算的重要战略技术趋势。分布式云的定义:将公有云服务分布到不同的物理位置(即边缘),而服务的所有权、运营、治理、更新和发展仍然由原始公有云提供商负责。解决客户让云计算资源靠近数据和业务活动发生的物理位置的需求。分布式云是整合公有云、私有云和边缘云在一起,核心思想是,让公有云的全栈服务能力延伸到用户所需的地方。
算力网络目前有很多定义,联通给的定义是:算力网络,是指在计算能力不断泛在化发展的基础上,通过网络手段将计算、存储等基础资源在云-边-端之间进行有效调配的方式,以此提升业务服务质量和用户的服务体验。随着边缘计算的发展和部署,用户不再是仅仅访问中心云,有的业务需要访问边缘云,甚至可能某个业务需要多云协同计算。
网络是用户去往算力资源的必经之路,也是用户发起业务需求的入口。由网络去调配算力,是个不错的方式,可以实现跨云访问。而分布式云,本质上是一朵云,由云负责调配计算资源。虽然中间需要网络,但是网络主要是承担管道的角色。
用户的需求是确定性的:云边协同。算力网络是网络拥有者为满足这类需求,提出的方案。分布式云是云计算厂商为满足同样的需求,提出的方案。从目前的趋势看,两种方式是既合作又竞争的关系。未来发展,我们拭目以待。

我们经典的服务架构是C/S架构,在微服务器化之后,在Client的视角,需要访问不同的微服务。那么,这些微服务会运行在哪里?为了更充分地利用各种算力资源,微服务可以运行在云端,也可以运行在边缘端,甚至可以运行在终端本地。并且,微服务的运行位置也不是一成不变的,可以根据运行硬件的“健康”状况以及整个算力体系的资源消耗情况,动态的决定运行的位置,而Client则不需要太过关心这些微服务具体运行在哪里。
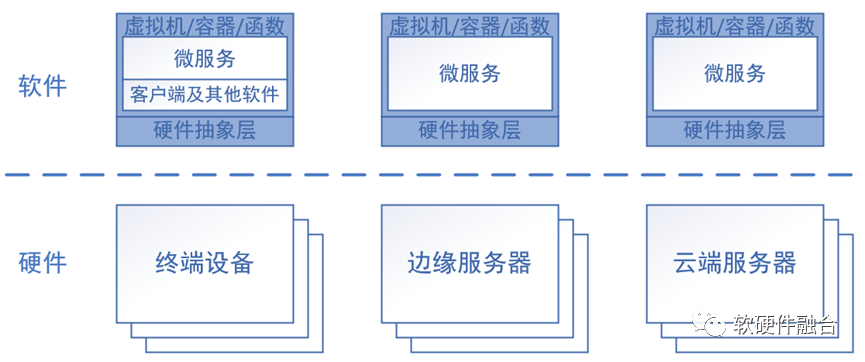
这样,就需要能够支持运行的微服务可以动态地在不同平台平滑迁移。这样,就需要云端服务器、边缘服务器甚至终端,都需要支持计算机虚拟化、容器虚拟化或者函数计算等虚拟化或Serverless系统架构和环境,确保微服务可以在不同的平台上自由迁移。
当然了,整个架构,对硬件平台的一致性要求也非常之高。如果涉及到各种硬件加速引擎,事情就会更加复杂。不仅是要求能够跨CPU的不同架构(如跨x86和ARM),还需要能够跨不同的处理器类型(比如跨CPU、GPU和DSA等),甚至跨越不同供应商的硬件。相关的内容可以见《预见·第四代算力革命》第三篇中的介绍,这里不再展开了。
数字经济时代,持续不断地增强算力,持续不断地降低算力的成本。一方面,我们可以以相同的价格,可以获得更多更丰富的算力;另一方面,是降低算力获取的门槛,实现算力普惠。

近日,国家发改委、中央网信办、工业和信息化部、国家能源局联合印发通知,同意在京津冀、长三角、粤港澳大湾区、成渝、内蒙古、贵州、甘肃、宁夏等8地启动建设国家算力枢纽节点,并规划了10个国家数据中心集群。至此,全国一体化大数据中心体系完成总体布局设计,“东数西算”工程正式全面启动。
“东数西算”通过构建数据中心、云计算、大数据一体化的新型算力网络体系,将东部算力需求有序引导到西部,优化数据中心建设布局,促进东西部协同联动。“东数西算”工程有三个总体思路:一是推动全国数据中心适度集聚、集约发展。通过在全国布局8个算力枢纽,引导大型、超大型数据中心向枢纽内集聚,形成数据中心集群。二是促进数据中心由东向西梯次布局、统筹发展。三是实现“东数西算”循序渐进、快速迭代。
随着数字经济建设的逐步深入,对算力的需求不断提高。在功耗和成本不变的情况下,通过架构创新,提升芯片的性能。如果我们能够把芯片的性能提升10倍,在同样的规模下,意味着10倍的宏观算力提升,也意味着单位算力成本和功耗均降低到1/10。这也就意味着,对用户来说,可以以同样的价格获得更多更丰富的算力资源。
芯片的一次性成本非常之高,芯片的通用性可以确保芯片的大规模复制。而大规模复制的芯片,就意味着无限摊薄芯片的研发成本。性能提升,成本降低,一里一外的优势,确保了芯片的核心竞争力。
并且,通过算力提升,以及成本和功耗降低,可以降低算力使用的门槛,使得更多的用户能够享受算力的便捷。在数字经济的世界里,大家共享技术发展带来的价值红利。









