绑定手机号
确认绑定









DeepSeek R1和DeepSeek R1-Zero的横空出世,是开源大型语言模型在推理能力上的重大突破,进而掀起了持续走高的研究热度,尤其是在青年研究人员当中,不仅激发了广泛且深入的思考,更是推动了更多优秀成果的涌现。
为此,智猩猩最新企划「AI新青年讲座DeepSeek R1与推理模型专题」,将邀请学术界和工业界的青年研究人员,分享最新洞见,讲解优秀成果。
第一讲将关注加州大学伯克利分校研究团队最新提出的开源项目DeepScaleR。该项目的一作为加州大学伯克利分校在读博士谭嗣俊。谭嗣俊博士等研究人员基于Deepseek-R1-Distilled-Qwen-1.5B模型,通过简单的强化学习微调,得到了全新的推理小模型DeepScaleR-1.5B-Preview。
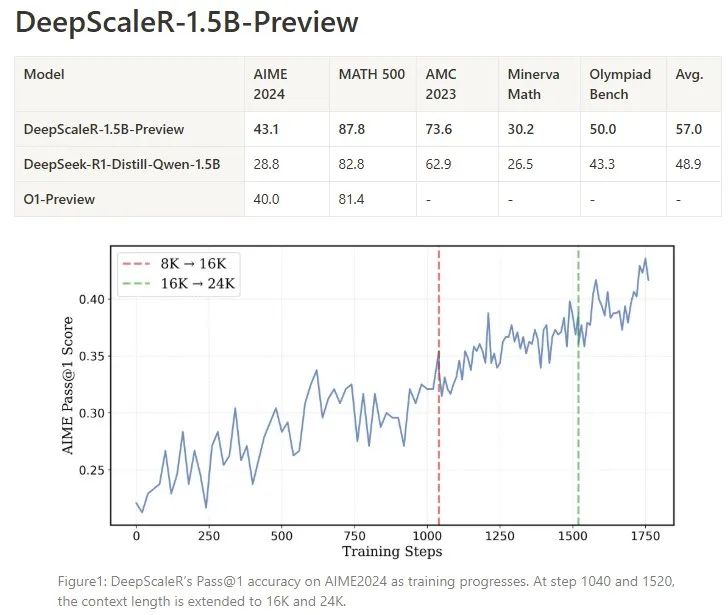
该模型在只有1.5B参数的情况下,经过4万个高质量数学问题的训练,在数学推理任务中超越了OpenAI的O1-Preview模型,展示了强化学习在小模型中的无限潜力。而完成这一复现,训练一共用了3800个A100 GPU小时,成本最终只需约4500美元。
具体而言,第一步,训练模型进行短思考。团队使用DeepSeek的GRPO强化学习算法,设定了8k的上下文长度来训练模型,以鼓励高效思考;接下来,模型被训练进行长思考。强化学习训练扩展到16K和24K token,以解决更具挑战性、此前未解决的问题。
在AIME 2024测试中,DeepScaleR-1.5B-Preview的pass@1准确率达到43.1%,相比Deepseek-R1-Distilled-Qwen-1.5B模型提升了14.3%,相比o1-preview提升了3.1%。而在MATH-500中,DeepScaleR-1.5B-Preview的性能也超过了o1-preview。
DeepScaleR-1.5B-Preview一经公开,就引起了广泛讨论。目前,研究团队已开源模型、数据、训练代码和训练日志。
北京时间2月17日15点,谭嗣俊博士受邀带来讲座,主题为《DeepScaleR: 强化学习让小模型推理超越o1-preview》。
讲者
谭嗣俊,加州大学伯克利分校在读博士
师从Raluca Ada Popa, 目前的主要研究方向是大模型后训练与大模型安全。在计算机系统(OSDI), 安全 (Oakland) 和人工智能 (NeurIPS, ICLR, EMNLP)顶会发表过多篇一作论文。
第 1 讲
主 题
《DeepScaleR: 强化学习让小模型推理超越o1-preview》
提 纲
1、Deepseek-R1带来的启示
2、强化学习在大模型训练中的难点
3、迭代长度训练:解放小模型的推理潜力
4、与其他小模型在推理能力上的对比分析
5、 DeepScaleR未来展望与计划
直 播 信 息
直播时间:2月17日15:00
项目成果
标题
《DeepScaleR: Surpassing O1-Preview with a 1.5B Model by Scaling RL》
项目地址
https://pretty-radio-b75.notion.site/DeepScaleR-Surpassing-O1-Preview-with-a-1-5B-Model-by-Scaling-RL-19681902c1468005bed8ca303013a4e2
如何报名与入群
有讲座直播观看需求的朋友,可以扫码添加小助手木瑾,发送私信“DS讲座01”进行报名,报名通过后将给到直播地址。
针对此次讲座,也有组建学习群。希望入群参与探讨的,也可以与木瑾进行申请。










