绑定手机号
确认绑定









近年来,3D视觉定位(3DVG)技术在增强现实和机器人领域取得了重要进展,但现有方法普遍依赖大规模3D标注数据,难以在零样本、开放词汇场景下实现泛化。




为此,香港科技大学(广州)、新加坡A*STAR研究院和新加坡国立大学的研究团队提出了一种全新的零样本3DVG框架SeeGround。该框架通过2D视觉语言模型(VLM)完成3D物体定位,无需任何3D标注数据即可在复杂场景中实现精确定位。

4月23日上午19点,智猩猩邀请到论文一作、香港科技大学 (广州) 人工智能学域博士生李蓉,新加坡科技研究局研究科学家李仕杰,以及新加坡国立大学计算机系在读博士孔令东参与「智猩猩AI新青年讲座具身智能专题」第26讲,主讲《具身场景零样本3D视觉定位方法SeeGround》。
主 要 创 新
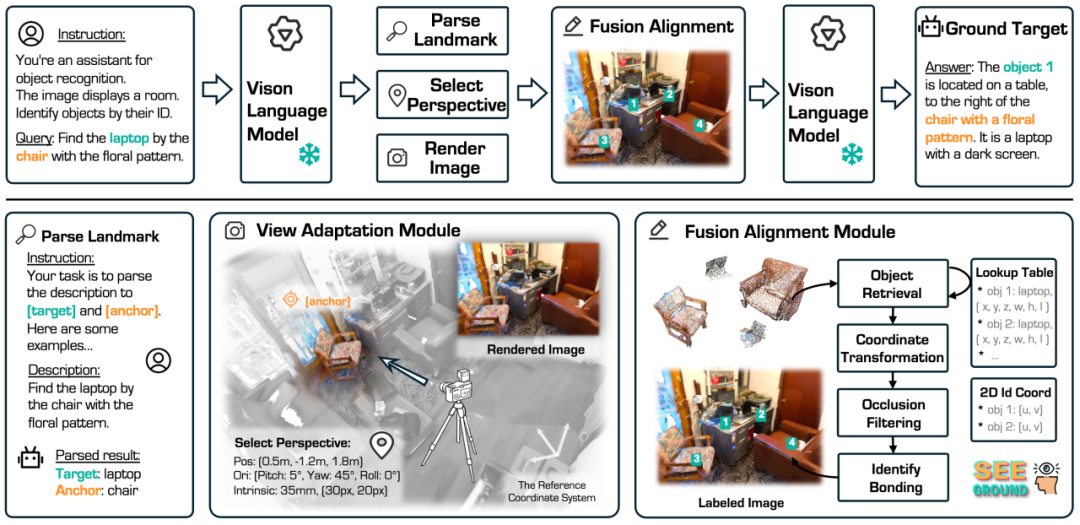
SeeGround 通过两个关键模块解决了现有方法在空间理解上的不足:
● 透视自适应模块(Perspective Adaptation Module, PAM)
○ PAM通过动态视角选择生成2D渲染图,帮助VLM更好地理解物体间的空间关系。
○ 解析文本输入,识别锚定物体(Anchor Object),根据其位置计算最佳观察角度,调整虚拟摄像机的角度,生成符合空间描述的2D图像。
○ 该动态视角选择策略使VLM在涉及相对空间位置(如“桌子右边的椅子”)的定位任务中表现更为精准。
● 融合对齐模块(Fusion Alignment Module, FAM)
○ FAM通过视觉提示增强(Visual Prompting)技术,将2D视觉特征与3D坐标信息对齐,提升定位精度。
○ 利用对象查找表(Object Lookup Table, OLT)提取所有物体的3D坐标,通过投影技术在2D图像上生成对应位置标注。
○ 在VLM推理阶段,结合2D视觉特征和3D空间信息,显著提升多目标定位的准确率和鲁棒性。
实 验 结 果
SeeGround 在 ScanRefer 和 Nr3D 数据集上进行了广泛的实验验证:
● 在ScanRefer数据集上的定位准确率达到62.3%,比现有零样本方法提升了9.2%。
● 在Nr3D数据集上的定位准确率为60.8%,显著超过其他方法。
● 在未见类别和未见场景的任务中,SeeGround 的性能接近甚至超越部分弱监督和全监督方法。
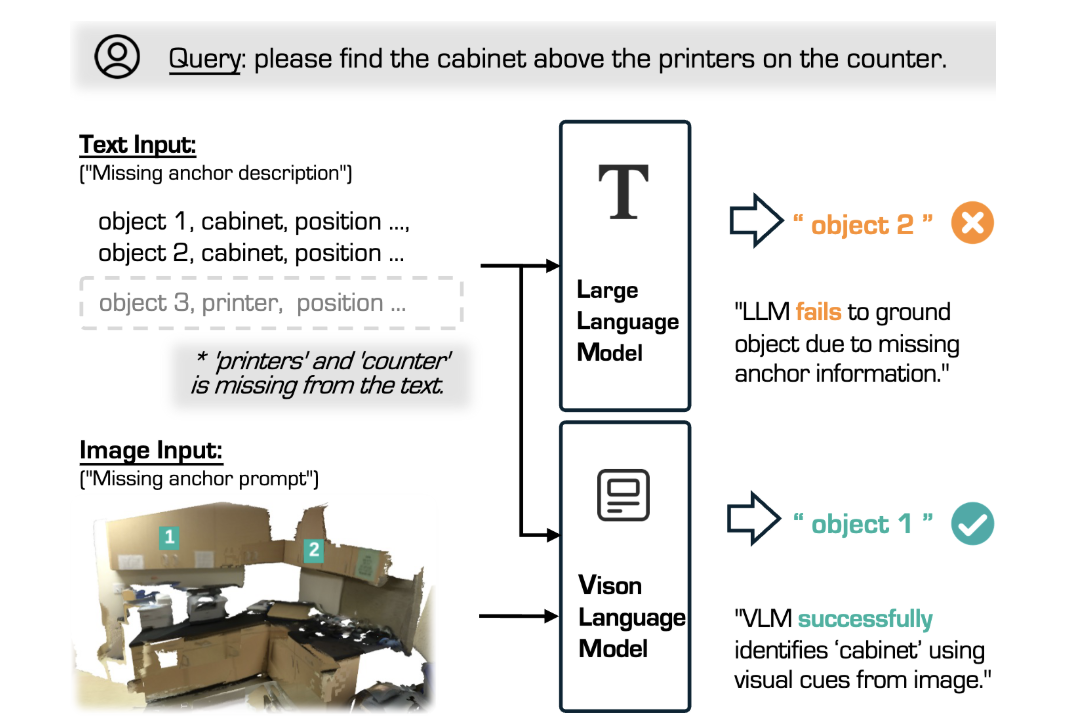
● 在消融实验中,去除部分文本信息(例如移除空间锚定描述)后,SeeGround 仍然能够基于视觉提示进行准确定位,展现出卓越的泛化能力。

此外,SeeGround 在多个复杂场景下均展示出稳健性和强大的跨模态理解能力:
● 在包含遮挡和复杂背景的场景中,定位准确率显著优于现有方法。
● 在涉及长文本描述和复杂空间指令的任务中,SeeGround 能够准确理解目标位置并生成精确的3D坐标。
应 用 场 景
● 增强现实(AR):在AR设备中实现自然语言与3D物体的交互。
● 机器人导航:帮助机器人在复杂环境中自主定位与操作。
● 智能家居:根据语音或文本指令,快速定位房间内的目标物体。
● 3D建模与可视化:在复杂3D场景中进行高效建模和精细可视化。
讲 者
李蓉,香港科技大学 (广州) 人工智能学域博士生
香港科技大学 (广州) 人工智能学域二年级博士生,导师是梁俊卫教授。曾于法国国家信息与自动化研究所 (Inria) 实习。研究方向为三维场景理解与具身智能。相关研究成果发表于TPAMI、CVPR、ICCV等国际期刊和会议中。
李仕杰,新加坡科技研究局研究科学家
新加坡科技研究局研究科学家,于2024年在德国波恩大学取得博士学位。曾在阿里巴巴达摩研究院,英特尔研究院和高通研究院实习。研究兴趣是自动驾驶以及机器人视觉,在TPAMI、TNNLS、ICCV、ICRA等会议和期刊上发表文章。
孔令东,新加坡国立大学计算机系在读博士
新加坡国立大学计算机系博士三年级在读,于上海人工智能实验室、英伟达研究院、字节跳动AI Lab等机构进行科研实习。主要研究方向为三维场景感知、理解与生成。相关研究成果发表于TPAMI、CVPR、ICCV、ECCV、NeurIPS、ICLR、ICRA等国际期刊和会议中,并多次入选Oral、Highlight、Spotlight展示。
第 26 讲
主 题
《具身场景零样本3D视觉定位方法SeeGround》
提 纲
1、3D视觉定位相关工作概述
2、SeeGround方法介绍
3、SeeGround提升VLM空间理解能力
4、实验结果评估与分析
5、3D视觉定位前景与应用
直 播 信 息
直播时间:4月23日19:00
成 果
论文标题
《SeeGround: See and Ground for Zero-Shot Open-Vocabulary 3D Visual Grounding》
论文链接
https://arxiv.org/pdf/2412.04383
项目主页
https://seeground.github.io
开源代码
https://github.com/iris0329/SeeGround
收录情况
CVPR 2025
如 何 报 名
有讲座直播观看需求的朋友,可以扫码添加小助手期期,发送私信“具身智能26”进行报名,报名通过后将给到直播地址。
针对此次讲座,也有组建学习群。希望入群参与探讨的,也可以与期期进行申请。










