绑定手机号
确认绑定









智猩猩AI整理
编辑:卜圆
强化学习(RL)在提升大语言模型(LLMs)推理能力方面至关重要,但策略优化常因token级重要性比率高方差而变得不稳定,尤其在混合专家(MoE)模型中更为严重。现有方法如GSPO和GRPO依赖硬截断,易在稳定性与学习效率之间失衡。
为此,来自阿里千问的研究者们提出软自适应策略优化(SAPO),用温度可控的平滑门控替代硬截断:近策略token梯度完整保留,离策略token梯度平滑衰减,避免信号突变;同时引入正负token不对称温度,加速抑制高方差负样本梯度。SAPO兼具序列一致性与token级自适应性,在存在异常token时仍能保留有效学习信号,提升样本效率。实验表明,SAPO在数学推理任务上训练更稳定、Pass@1性能更强,并成功应用于Qwen3-VL系列模型,在不同场景下均能带来显著提升,是一种更可靠高效的RL优化方法。

论文标题:Soft Adaptive Policy Optimization
论文链接:https://arxiv.org/pdf/2511.20347
01 方法
研究团队将SAPO引入面向大语言模型的分组式 RL 框架,并进一步扩展了两个对大语言模型训练至关重要的组件:
token 级别的软信任区域,可自然地实现序列级一致性。
不对称的温度设计,其动机源于正负 token 更新所表现出的不同行为特性。
(1)软信任区域
每个 token 的自适应门控权重如下:
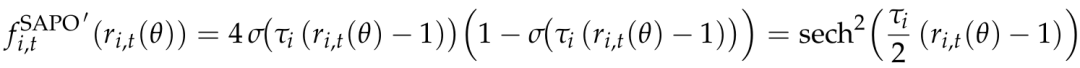
研究团队引入两个常见假设:
假设A1:小步长/同策略(Small-step/on-policy):
重要性采样比满足 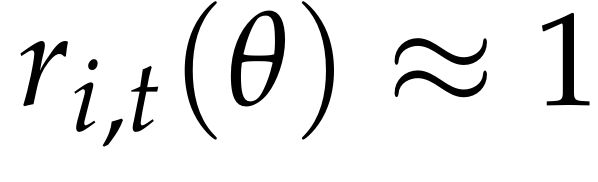 因此有,
因此有,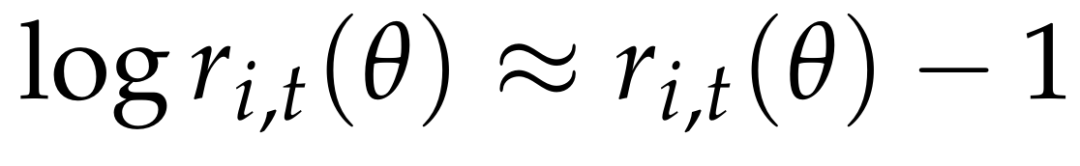 。
。
假设A2:序列内低分散度(Low intra-sequence dispersion):记 ![]() ,并定义序列均值为
,并定义序列均值为 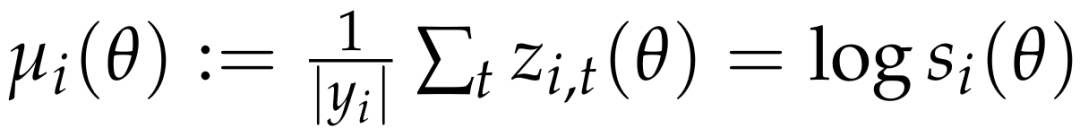 。
。
则对大多数序列而言,其序列内方差 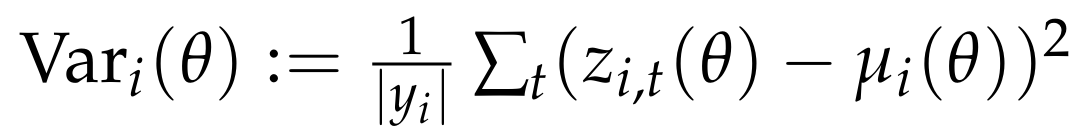 较小。
较小。
在这两个合理假设下,SAPO 进行局部线性化与序列平均近似后最终简化梯度表达式如下,
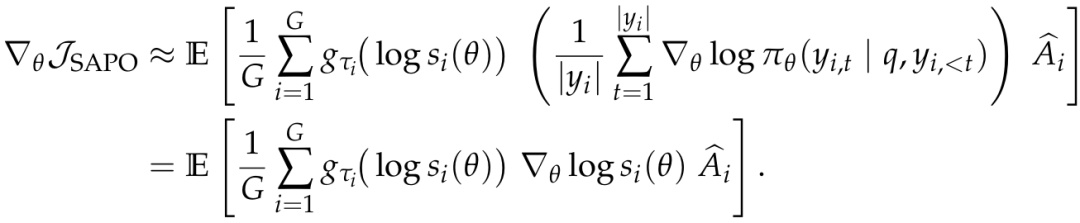
建立了 SAPO 与现有序列级策略优化方法之间的理论桥梁。
通过绘制 token 重要性比率 ri,t(θ) 与每条序列的对数比率方差 Vari(θ) 的直方图,对假设A1和假设A2在 MoE 模型与稠密模型上的有效性进行了实证检验(结果见图 2 和图 3)。
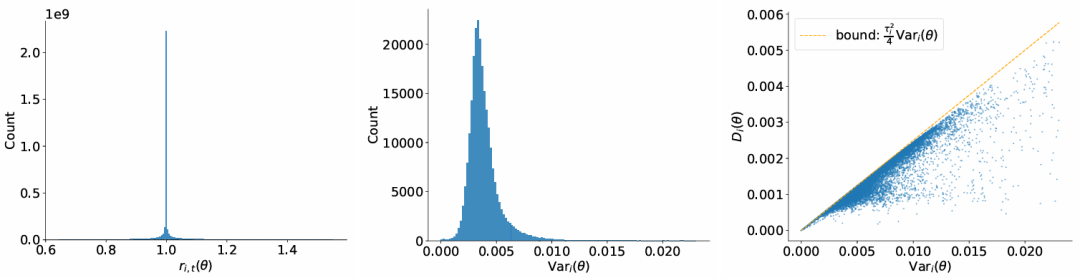
图2 在 MoE 模型(Qwen3-30B-A3B)上对假设 (A1)–(A2) 的实证验证
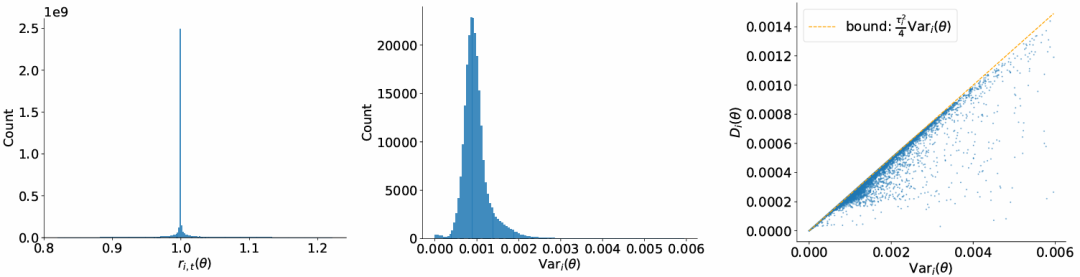
图3 在稠密模型(Qwen3-4B)上对假设 (A1)–(A2) 的实证验证
左图:token 重要性比率 ri,t(θ) 的直方图。中图:每条序列的对数比率方差 Vari(θ) 的直方图。
右图:Vari(θ) 与 Di(θ) 的散点图。
ri,t(θ) 的分布高度集中在1 附近;Vari(θ) 通常低于 0.02,其中 MoE 模型的分布略宽,而稠密模型的分布更为集中。
这些结果表明,假设A1和A2在绝大多数情况下是成立的,尤其对于稠密架构而言。此外,较小的 Di(θ) 值说明:token 级门控的平均行为可以被序列级门控良好近似,从而为理论简化提供了有力支持。
(2)不对称温度设计
SAPO的优化目标函数如下:
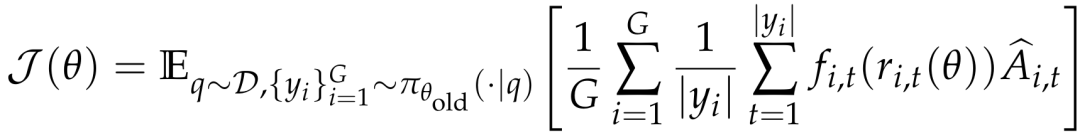
其中,
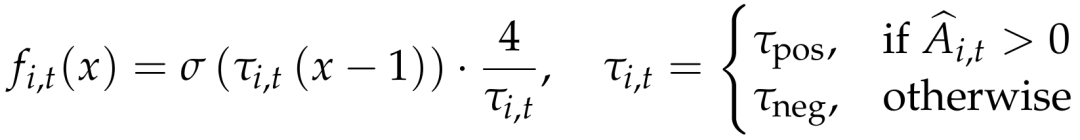
超参数 τ 控制衰减速率:τ 的值越大,衰减越快。尽管负优势对应的 token 对于探索和防止过拟合至关重要,但它们通常比正优势对应的 token 引入更大的训练不稳定性。
在大语言模型的强化学习微调中,正向优势增强采样 token 并抑制其他 token,而负向优势会抬高大量无关未采样 token 的 logit,导致梯度噪声扩散和训练不稳定。为此,对正负 token 采用不同温度,设 τneg>τpos,使负向梯度衰减更快,从而提升稳定性和性能。
02 评估
实验基于 Qwen3-30B-A3B-Base 模型,针对数学推理任务进行冷启动强化学习微调,在 AIME25、HMMT25 和 Beyond AIME 三个基准上评估训练奖励和验证性能(16 样本平均 Pass@1)。SAPO 使用 τpos=1.0、τneg=1.05,与 GSPO 和带路由重播的 GRPO-R2 在相同超参下对比。
如图4所示,SAPO 在所有基准上均表现更优,训练更稳定,最终性能更强;GSPO 和 GRPO-R2 出现早期训练崩溃,而 SAPO 无需依赖路由重播即可保持稳定,降低了系统复杂度。
不对称温度设计的实验结果如图5显示,当τneg > τpos(如 1.05 > 1.0)时训练最稳定,反之则更易发散,验证了对负优势 token 使用更高温度能有效抑制梯度噪声、提升稳定性。
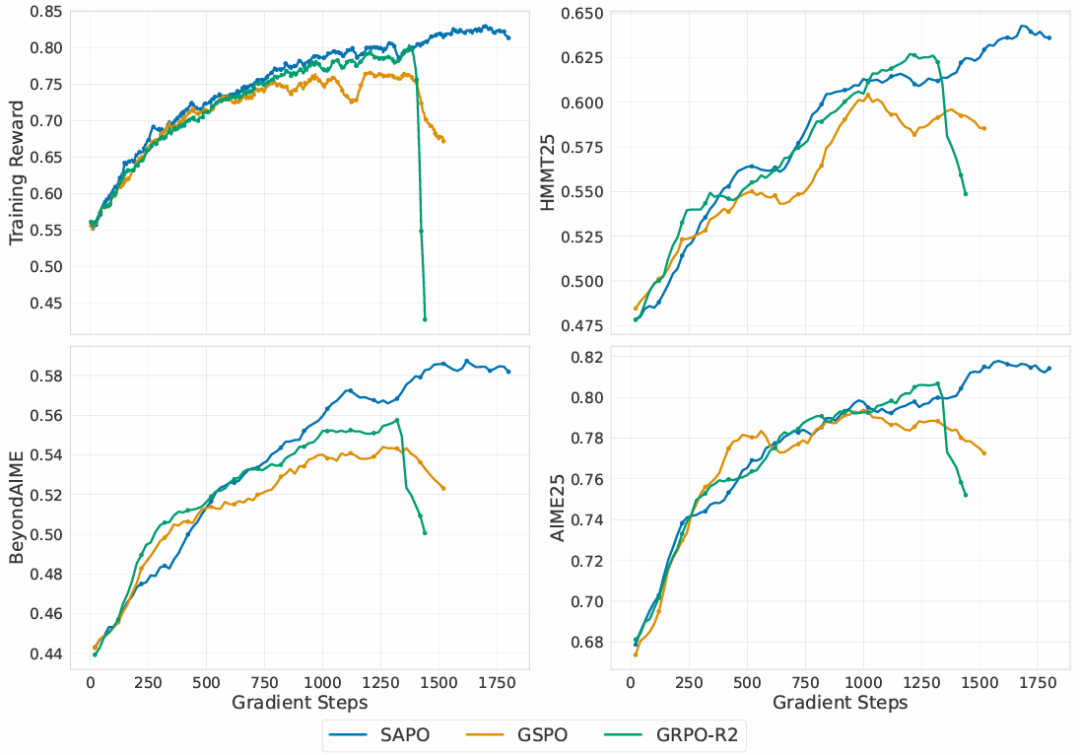
图4 在不同强化学习算法下,从 Qwen3-30B-A3B-Base 冷启动模型微调得到的训练奖励与验证性能对比
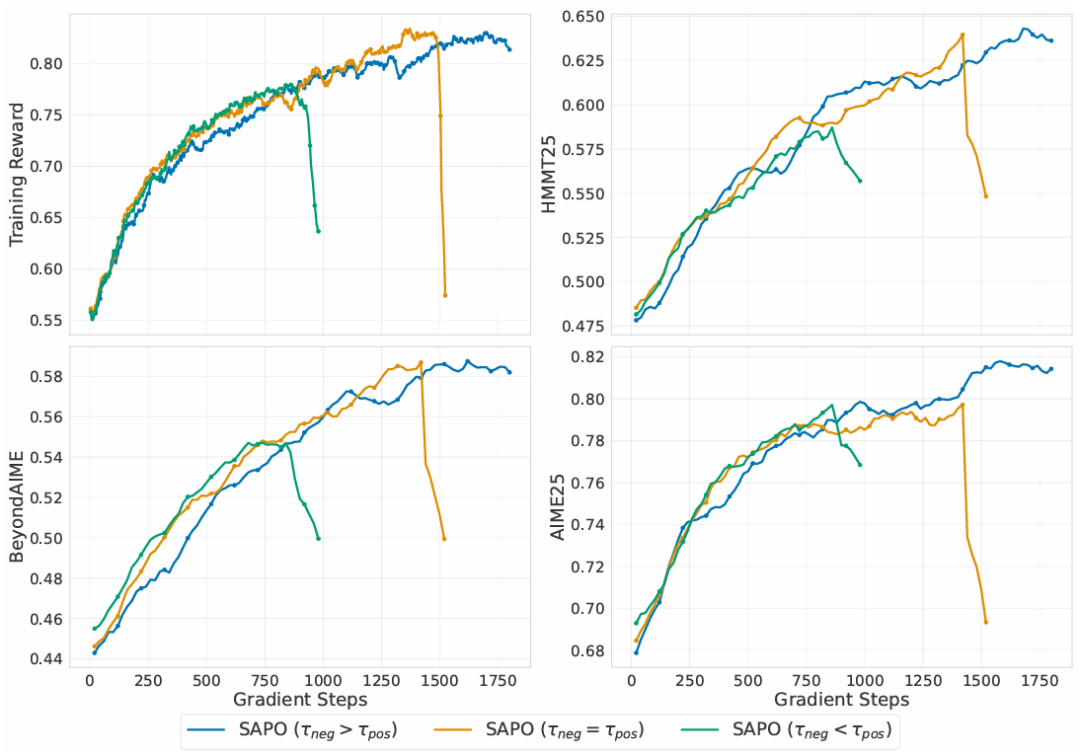
图5 SAPO 温度配置对冷启动微调性能的影响(Qwen3-30B-A3B-Base)
将 SAPO 应用于 Qwen3-VL 系列模型,在大规模多任务场景中评估其有效性。训练涵盖数学、代码、逻辑推理等文本与多模态任务,每批次按固定比例混合各任务,并采用大批次以保证学习信号充足。实验表明,SAPO 在不同规模、MoE 与稠密架构上均能稳定提升性能。如图 6 所示,在相同计算预算下,SAPO 训练更稳定,全程持续提升,并显著优于两个基线方法。
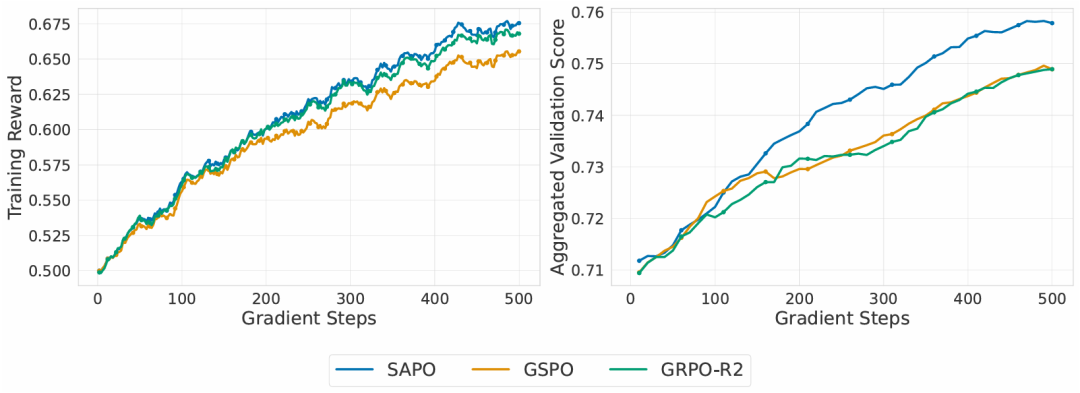
图6 Qwen3-VL-30B-A3B 冷启动训练的奖励与验证性能对比









