绑定手机号
确认绑定









类脑计算是近些年来崛起的新兴研究领域,与人工智能、机器学习等领域类似,很难对其进行准确定义,目前业内尚没有普遍认可的类脑计算概念定义。
李国齐指出,类脑计算的描述性定义为“指受人脑信息处理方式启发,以更通用的人工智能和高效智能边缘端/云端为目标构建信息系统的技术总称”。类脑计算希望融合脑科学、计算神经科学、认知科学甚至统计物理等学科的知识来解决现有传统计算技术的一些问题,进而构建更加通用、高效、智能的新颖信息系统。

狭义类脑计算是指神经形态计算,主要是研制神经形态芯片以支持源自计算神经科学的脉冲神经网络(Spiking Neural Networks, SNN);广义类脑计算也包括存内计算、忆阻器芯片甚至研制AI 芯片以支持传统的人工神经网络(Artificial Neural Networks ,ANN)。因此,类脑计算的研究与发展与人工智能一样也需要从模型算法、软件、芯片和数据等各个方向协同展开。
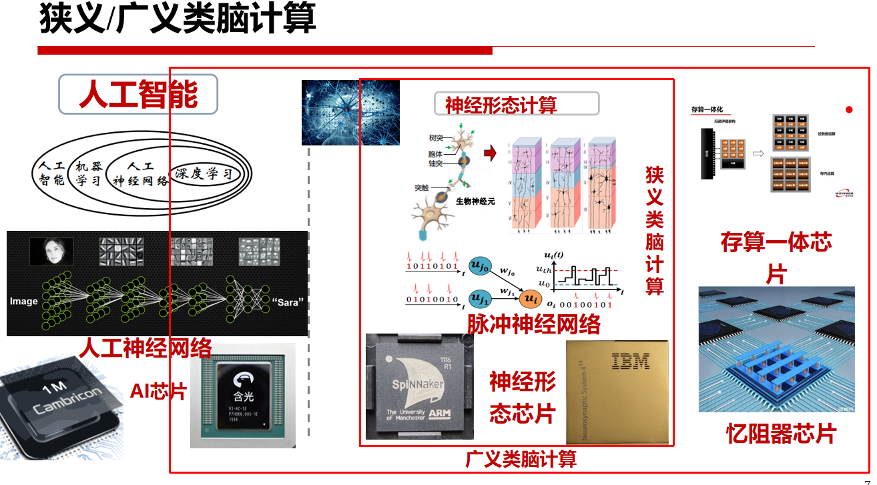
当前,神经科学与人工智能之间存在着巨大鸿沟,神经科学侧重于重构大脑内部的精细结构和生理细节,人工智能则侧重于通过对神经结构进行数学抽象以实现计算的高效性。
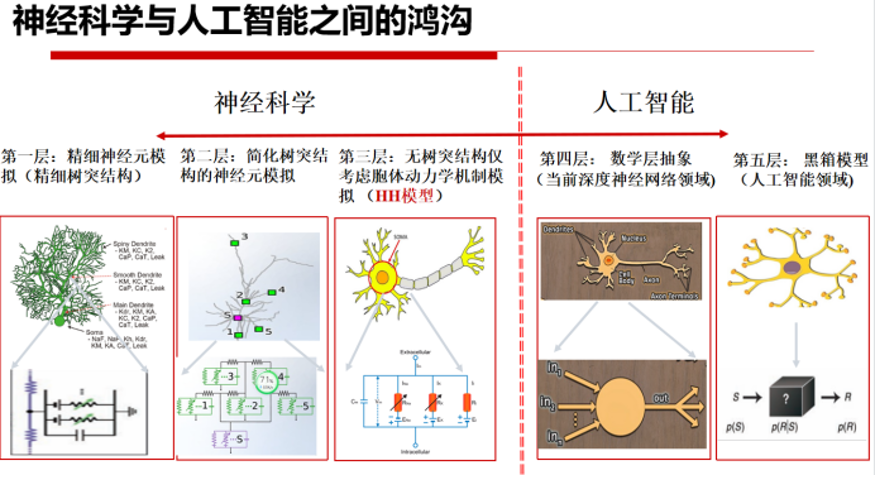
因此,人工智能和神经科学如何交叉融合成为一个艰巨挑战。类脑计算中,脉冲神经网络兼具了生物合理性和计算高效性,或可以为人工智能提供新范式。简单地,可以认为SNN = ANN + Neuronal Dynamics。如何寻找兼具生物合理性与计算高效性的脉冲神经元模型,以及如何建立脉冲神经元模型与AI任务之间的关系是类脑计算领域的核心问题。
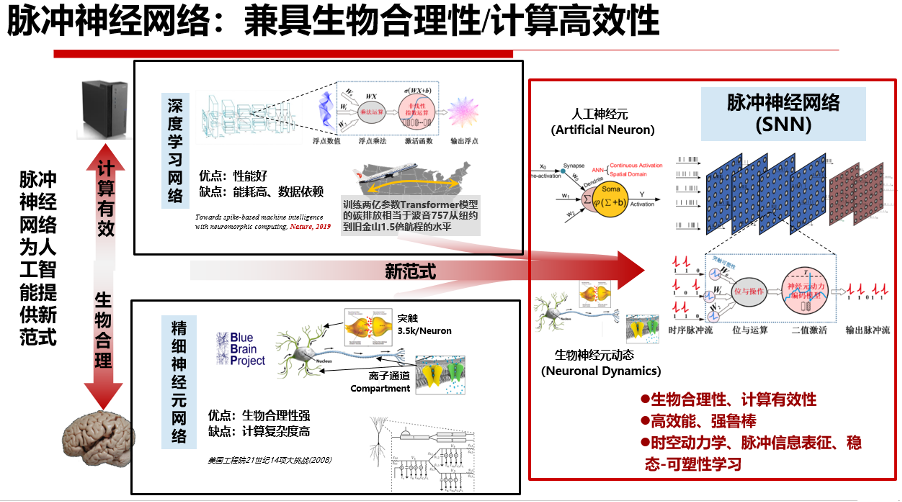
当前,SNN普遍采用LIF神经元作为构建神经网络的基础单元。原因在于,LIF神经元是一种典型的综合模型,既具备IF模型的简单易用性,又能像H-H神经元模型那样模拟生物神经元丰富的生理学特性。
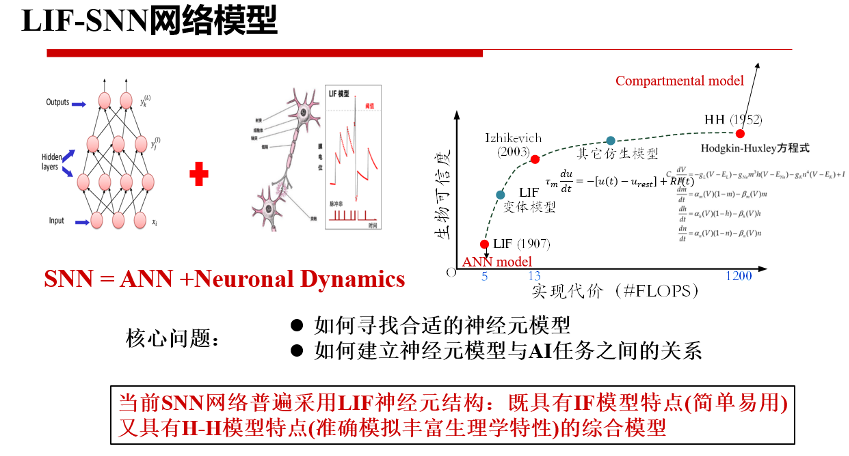
众所周知,ANN和SNN各具特点,互有所长。ANN能够充分利用现有计算机的计算特性,以神经元状态表示信息,在空间域传递信息,主要操作为密集矩阵向量乘法,相比之下,SNN采用脉冲序列表示信息,在空间域和时间域两个维度传递信息,主要操作为事件驱动的稀疏加法,兼具计算高效性和生物可信性。

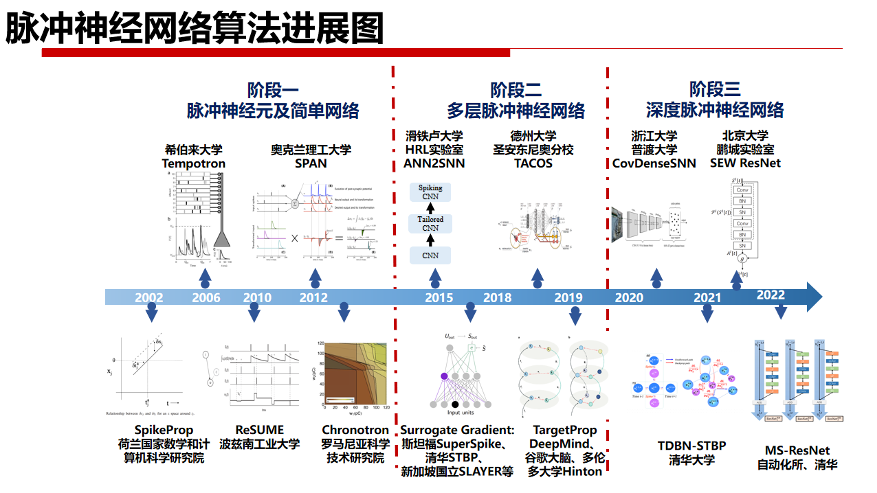
与ANN训练相比,SNN的高效训练面临着诸多问题与挑战,例如脉冲神经元中复杂的时空动力过程、脉冲神经元之间传递的脉冲信息不可导、脉冲退化和训练精度损失等。当前,SNN训练方法主要包括无监督学习、间接有监督学习和直接有监督学习三类。这些训练方法尝试从不同的角度解决上述问题和挑战。
1.基于STDP的无监督学习
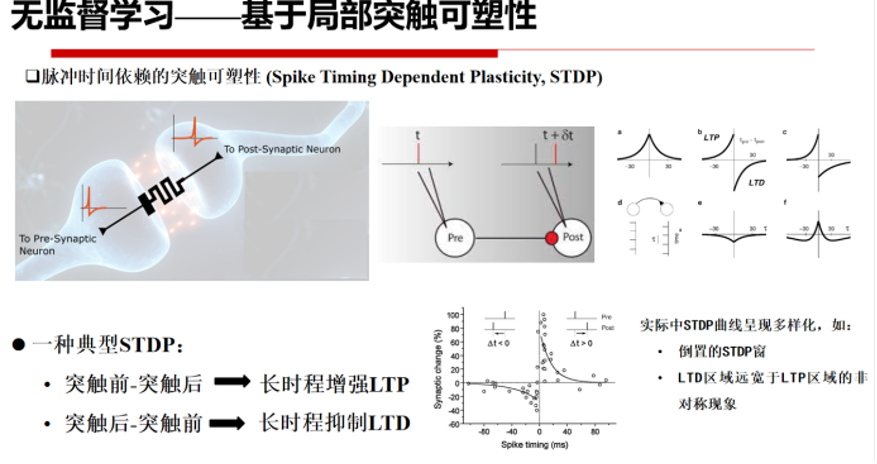
基于脉冲时间依赖的突触可塑性 (Spike Timing Dependent Plasticity, STDP)能够控制大脑神经元之间权重连接更新,是一种典型的无监督学习方法。通俗的说,两个神经元的发放时间越近,他们之间的绑定关系就越紧密。如上图所示,当两个神经元先后激活时,具备紧密先后关系的双方会加强联系,而具备相反关系的双方就会削弱联系,因此神经元之间往往建立单向加强联系。
如果两个神经元同时激活,则他们与共同的下游神经元之间形成了更加紧密的联系,这样两者为同级神经元,且相互之间具备间接关系。例如,通过STDP规则结合Winner-Take-All(WTA)构成的学习模型是一种简单有效的无监督学习方式。
具体地,在输入层将图片转换为脉冲序列(脉冲发放率正比于像素值),神经元以全连接形式前向连接,接受兴奋性输入,并采用STDP规则更新,并与抑制性神经元后向一对一连接,对其产生侧向抑制 (即soft WTA),并通过自适应阈值平衡脉冲发放率。
STDP模型通过局部调整规则进行学习,在神经形态芯片上容易进行分布式实现并具备在线学习能力。但是,局部突触可塑性不足以解释突触个体的改变如何协调神经系统的整体目标的实现。同时,李国齐也指出,这种无监督学习训练方法存在着难以获得高性能网络,无法在大规模深度神经网络中使用等问题。
2.基于ANN转SNN的间接有监督学习

ANN-converted SNN方法是指训练一个ANN模型,而后将学习完成后的ANN权重迁移到具有相同结构的SNN中。其基本思想是,利用SNN平均脉冲发放率来近似表示ANN中的 ReLU激活值。
因此,ANN-converted SNN方法存在着模型精度与模型仿真步长T之间的tradeoff问题。该方法利用有监督信号在原始ANN模型中进行梯度反向传播训练,然后将其转换成SNN模型,因此是一种间接有监督学习。
ANN-converted SNN方法可扩展性强,容易将新出现的或大规模的ANN网络结构转换为相应的SNN版本。一般地,仿真时间步数T越大,SNN平均脉冲发放率越接近ANN中的激活值,两种模型之间的误差也就越小,从而实现ANN-SNN几乎“无损”转换。但过长的时间步数T会导致训练和推理效率下降,SNN的功耗优势也随之降低。此外,李国齐指出,由于这种方法本质上是利用SNN去逼近ANN,在转换的过程中会丢失SNN中可利用的时间依赖信号,因此可能会导致其应用场景相对受限。
3.SNN直接有监督学习的发展
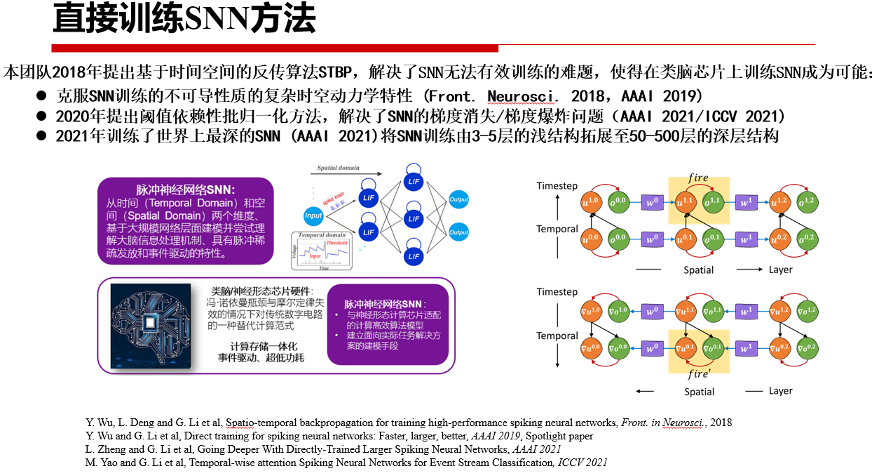
为避免上述两种训练方法的局限性,解决SNN无法有效训练的难题,李国齐及其团队较早的提出STBP(Spatio-Temporal Backpropagation)等SNN直接训练方法。
直接训练算法难点在于SNN复杂的时空动力学特性及脉冲发放不可微分问题。李国齐团队提出的解决思路是,将脉冲神经元的微分方程形式转换为便于计算机仿真的差分方程形式,将信息沿时间、空间空维度同时展开,并采用脉冲梯度逼近方法。由于近似替代函数保留了脉冲发放的“非线性特征”,其梯度逼近曲线具有一定的鲁棒性。

STBP虽然解决了SNN网络中进行反向传播训练的梯度替代问题,但其仍然只能训练不超过10层的小规模网络。其中主要问题在于,一旦网络加深,先比较于ANN,脉冲神经元的二进制激活方式及其复杂的时空动态更容易带来网络的梯度消失或爆炸问题。
通过进一步分析SNN中的时空动态特性可知,建立神经元膜电势和阈值之间的平衡,以获得一个合适的网络脉冲发放率对网络的性能至关重要。过低的发放率可能会导致有效信息不足,而过高的发放率则会降低SNN网络对输入的区分度。
因此,李国齐团队进一步提出了结合脉冲神经元阈值的BN算法,即Threshold-dependent BN方法(TDBN),缓解了制约SNN的规模瓶颈问题,首次将SNN的网络规模提升至50层,在ImageNet等大规模数据集上取得具有竞争性的性能,并证明了该方法可缓解深度SNN的梯度消失与爆炸问题。
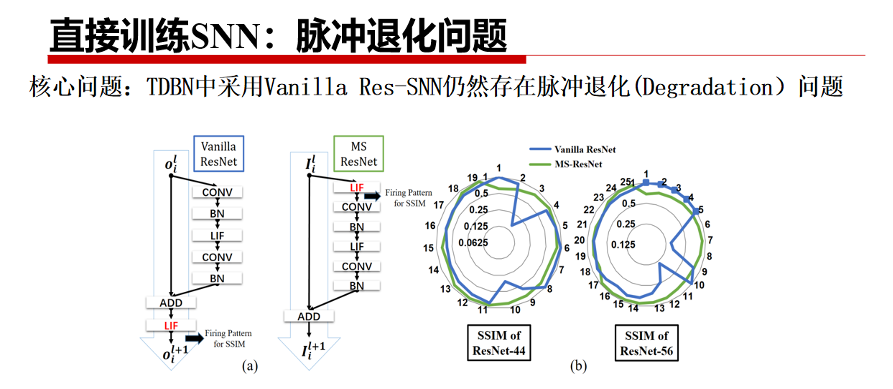
尽管TDBN提升了SNN的规模,但相对于传统ANN中动辄数百层的深度网络,性能仍然捉襟见肘,不足以在大规模数据集上与ANN进行竞争。为了进一步提升SNN的网络表达能力,扩大网络规模从而提升任务性能,借鉴经典的ResNet结构是似乎一种可行的方法。
但是,直接复制ResNet结构到SNN中(Vanilla Res-SNN)存在着脉冲退化问题,即网络越深,精度越低。因此,李国齐团队提出了一种将LIF神经元放置在残差块中,并在不同层神经元的膜电势之间建立shortcut的新颖Ms-Rse-SNN结构。并利用dynamical isometry理论证明了所提出的结构不存在脉冲退化问题。在相对广泛的范围内解决了大规模SNN直接训练问题(482层 CIFAR-10,104层 ImageNet),后者取得Top-1 76%分类准确率的SOTA结果。
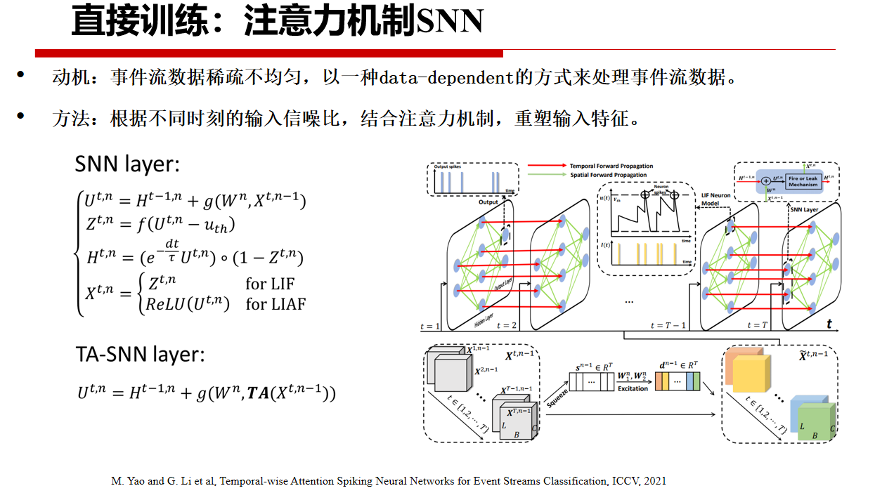
此外,根据SNN处理数据的不同,采用data-dependent的处理方式,可以为直接训练SNN在一些任务中带来额外的性能增益。例如,在神经形态视觉任务中,事件流数据往往具有稀疏、不均匀特性。
根据这一观察,李国齐团队提出了一种时间注意力脉冲神经网络,根据事件流在不同时刻的输入信噪比,结合时间注意力机制,使用SNN以数据驱动的方式来进行任务处理,可以在进一步降低网络能耗的基础上带来性能提升。实验结果表明,即使去掉一半的输入,SNN的性能基本能够维持不变或略有提升。总而言之,当前SNN已经进入大规模深层模型和算法的发展阶段,并将在传统人工智能领域中多种下游任务得到进一步的应用。
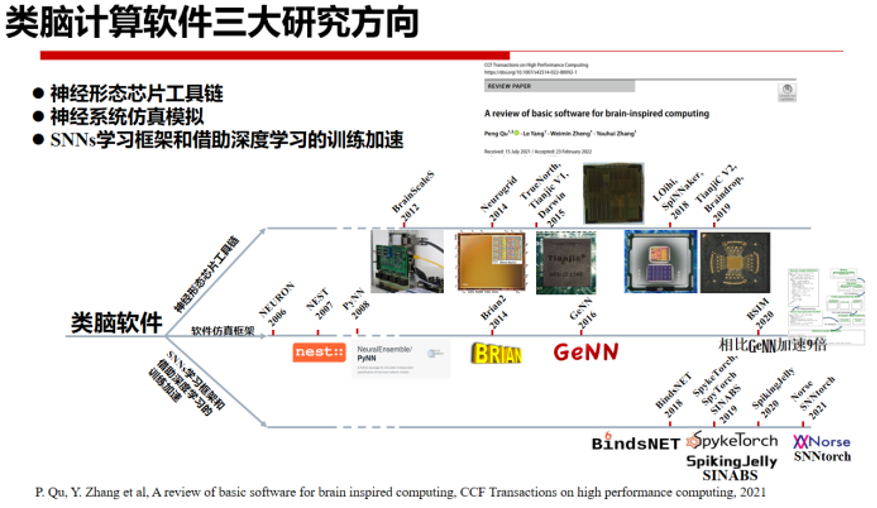
类脑计算软件框架与工具通常包括神经形态芯片工具链、神经系统仿真模拟和SNN学习框架等三个方面的内容,具体可参考清华大学张悠慧教授在IEEE Transactions on High Performance Computing的综述论文观点。
神经形态芯片工具链目前尚处于早期阶段,存在软件与硬件紧密耦合,通用性、自动化程度不高,使用便捷性差等许多问题。神经系统软件仿真框架能够详细模拟生物神经网络,但要求用户具有一定的计算神经科学基础。
现有的仿真工具软件框架通常用C语言开发,缺乏跨平台能力,也缺乏对各种后端硬件的深度优化的支持。并且,这些软件通常为CPU和GPU等商业硬件而设计,并不支持不同类型的神经形态芯片。SNN学习框架的目标是,将深度学习框架开发的便利性与SNN的特点相结合,充分利用深度学习领域的各种资源,对SNN网络训练进行加速,相关工作基本处于前期并且不够稳定,更无法适应不同的软件和硬件接口,即使基于GPU架构开发也难以充分利用SNN本身的特性进行加速。

从功能角度看,类脑芯片主要分为四类:
主要支持人工神经网络(TPU、寒武纪、华为昇腾等)的深度学习加速器;
主要支持脉冲神经网络(TrueNorth、Loihi、达尔文等芯片)的神经形态芯片;
支持人工/脉冲神经网络的异构融合芯片(Tianjinc芯片);
以及支持神经元编程的脑仿真模拟芯片(SpiNNaker、 ROLLS、 Loihi等芯片 )和具备低时延、高动态的神经形态相机为代表的感知芯片。
类脑芯片的体系架构包括主流深度学习加速器采用的存算分离架构,主流众核去中心化架构芯片的近存计算架构,以及存内计算芯片、忆阻器芯片等所采用的存算一体架构。从芯片设计的角度来看,采用路由器连接的多核架构的芯片的可扩展性更好,多个功能核独立工作,核间周期性地同步和共享数据。因此可支持的网络规模更大,应用范围更广的SNN。
采用单纯数字信号的小规模单核芯片可以采用存内计算进行矩阵向量乘,具备同步、异步设计流程,往往具备较高的能效和较低的静态功耗,且更便于技术迁移,但神经元与突触的规模受限。数模混合小规模单核芯片采用数字异步脉冲路由,利用存内数字计算方法进行矩阵向量乘法,采用模拟膜电位进行激活与更新,因此能效最高,但也存在神经元与突触数量少和设计不方便等问题。

众所周知,深度学习发展四要素为算法、算力、开发工具以及大规模的数据。在深度学习领域,成百上千个开源数据集覆盖分类、检测、跟踪、自然语言等,极大地促进了深度学习的繁荣。
相比之下,类脑数据集十分匮乏,现有的数据集主要包括四类:
第一类是通过转换算法将ANN数据集转变为事件信号数据集,典型数据集包括基于ImageNet转换而来的ES-ImageNet,基于UCF101转化的事件信号数据集ES-UCF101,基于BDD100K转化的事件信号数据集BDD100K-DVS等;
第二类是利用神经形态相机DVS将图像或视频数据库转化为事件数据集,比如N-MNIST、CIFA10-DVS等数据集;
第三类是通过神经形态相机DVS直接拍摄获取的数据集,比如DVS-Gesture、PKU-DDD17-CAR、Gen1 Detection、1Mpx Detection、PKU-DAVIS-SOD等;最后一类是其它类型的类脑数据集,比如EEG数据集、脑机接口(BCI)相关的数据集、帧数据和事件的混合数据等。
最后,李国齐结合自己的思考总结了类脑计算的未来发展趋势,并对类脑系统框架进行了总结。
在模型算法方面,不仅可以通过增加模型参数、网络深度或宽度使得SNN模型变大变强,更重要的提供向内增加神经元复杂程度的能力支撑,缩减神经科学与人工智能之间存在的鸿沟。因此,构造包含更丰富动力学的神经元模型、神经网络及对应的算法是未来的重要方向。
在类脑软件方面,如何提升SNN的研究生态是未来发展的必经之路,重要的方向包括神经形态工具链的软硬件去耦合、SNN训练加速框架、及高效的神经系统仿真和模拟等。在类脑数据方面,如何构建具备稀疏事件特征、具备丰富的时间尺度/空间尺度特征的大规模多模态混合数据集十分重要。
在类脑芯片方面,主要关注神经形态芯片如何进行更高效的感知、存储和计算,如何构建融合感存算一体化的计算系统。研究更高效的芯片架构、研制更具有类脑元素的芯片功能也是未来发展的重要方向。芯片架构上可以探索类脑芯片的分层存储体系、高效在线学习架构及其与其它硬件平台的高效兼容能力;芯片功能上可以探索如何融入更多的算子支持比如微分方程、线性方程求解,以及如何在算子层面上支持更类脑的神经元模型和网络结构等。
李国齐认为,类脑系统的总体框架包括类脑的模型、算法、软件以及芯片,并结合丰富类脑数据构造的计算系统,在人工智能领域可以朝着高效云端/边缘端类脑计算系统的构造方向发展,在脑科学领域可利用现有的超算服务器集群进行神经动力学的仿真和模拟,构建更为复杂的脑仿真和神经模拟系统。

作者简介 :李国齐,中国科学院自动化所研究员,博士生导师,北京智源人工智能研究院青年科学家。李国齐在Nature、Nature Communications、Proceedings of the IEEE、IEEE TPAMI等期刊和ICLR、NeurIPS、AAAI、CVPR等会议上发表论文 150余篇;出版国内类脑计算领域早期学术专著1部;论文在 Google 学术上被引用 4500余次。2017 年入选北京市自然科学基金优秀青年人才,2018 年获得中国指挥与控制学会科学技术一等奖,2019 年入选北京智源人工智能研究院“智源学者”,2021年获得福建省科技进步二等奖,2021 年获得北京市杰出青年基金资助,2022年入选中科院“百人计划”;其参与的类脑芯片理论、架构和工具链的工作曾入选2019年中国科学十大进展和2020年世界人工智能十大进展。








