绑定手机号
确认绑定









CVPR‘22论文“MonoDTR: Monocular 3D Object Detection with Depth-Aware Transformer“,作者是台大和自动驾驶公司富智捷(属于鸿海集团spin-off,教授在里面任CTO)。

单目3D目标检测是自主驾驶中一项重要而富有挑战性的任务。现有的一些方法利用现成的深度图估计器提供的深度信息来辅助3D检测,但额外计算负担是个包袱,而且由于深度先验不准确,系统性能有限。为了缓解这一问题,这里提出一种端到端深度-觉察的Transformer网络MonoDTR。
它主要由两部分组成:(1)深度-觉察特征增强(DFE)模块,该模块通过辅助监督,隐式学习深度-觉察特征,而无需额外计算;(2)深度-觉察Transformer(DTR)模块,该模块全局集成上下文和深度-觉察特征。此外,与传统的像素位置编码不同,作者引入一种深度位置编码(DPE),将深度位置提示注入到Transformer中。所提出的深度-觉察模型,可以很容易地插入现有纯图像单目3-D目标检测器中,以提高性能。
代码位于https://github.com/Kuanchihuang/MonoDTR。
3D目标检测是一个基本问题,可以实现各种应用,如自动驾驶。以前方法基于来自多个传感器的精确深度信息,如激光雷达信号或立体匹配,实现了卓越性能。为了降低传感器成本,已经提出了一些单目3D目标检测方法,并且依靠2D和3D之间的几何约束取得了令人瞩目的进展。然而,如果没有深度线索的帮助,性能仍然远远不能令人满意。
最近,有几项工作试图从预先训练的深度估计模型生成估计深度,以辅助单目3D目标检测。基于伪激光雷达的方法将估计的深度图转换为3D点云,以模拟激光雷达信号,然后使用现有的基于激光雷达的检测器进行3D目标检测。一些基于融合的方法采用多种融合策略,将深度和图像提取的特征结合起来,以检测目标。这些方法虽然可以借助估计的深度更好地定位目标,但可能存在从不准确深度图学习3D检测的风险。此外,深度估计的额外计算成本在应用中不切实际。
为了解决上述问题,作者提出MonoDTR,一种用于单目3D目标检测的端到端深度-觉察Transformer网络。如图所示:引入深度-觉察特征增强(DFE)模块,利用辅助深度学习深度-觉察特征,避免从预训练的深度估计中获取不准确的深度先验信息;(a)为伪激光雷达方法,(b)为多传感器融合方法,(c)为本文MonoDTR方法。
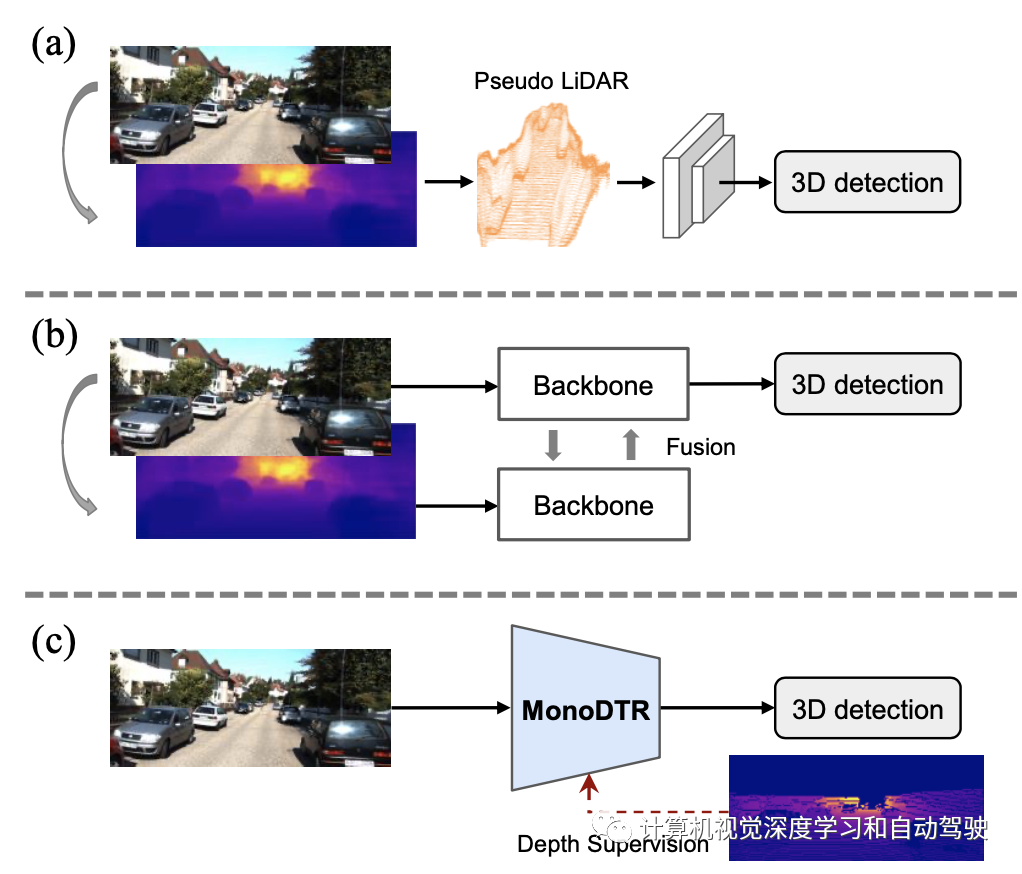
此外,DFE模型重量轻,但在辅助3D目标检测方面非常有效,无需构建复杂的体系结构来从现成的深度图中提取特征。与之前的深度辅助方法相比,它显著减少了计算时间。
此外,与之前的基于融合的方法(如D4LCN和DDMP-3D)不同,该方法开发了第一个基于Transformer的融合模型,用于全局集成图像和深度信息,这些方法将仔细设计的卷积核应用于上下文特征和深度-觉察特征。这种transformer编码器-解码器结构,已被证明能够有效捕获长距离依赖关系。
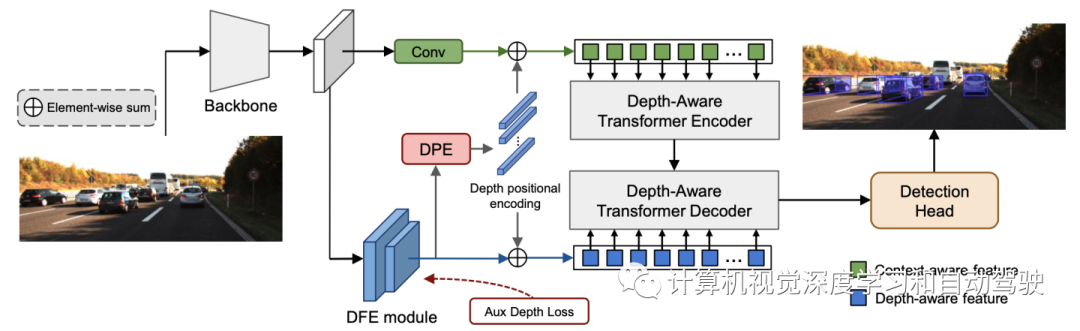
如图是MonoDTR的总体框架:输入图像首先发送到主干提取特征,深度-觉察特征增强(DFE)模块通过辅助监督学习深度-觉察特征,并通过卷积层并行提取上下文-觉察特征。深度-觉察Transformer(DTR)模块集成了两种特征,而深度位置编码(DPE)模块将深度位置提示注入Transformer。最后,使用检测头预测3D边框。请注意,辅助深度监督仅在训练阶段使用。
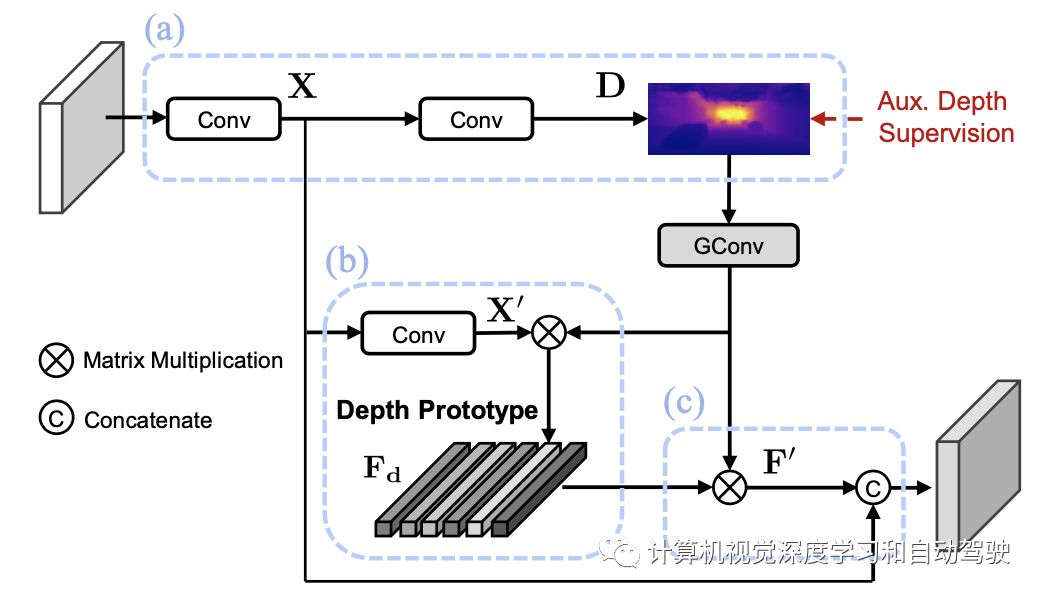
为了进一步增强深度表示的能力,引入相应深度类别(bin)的中心表征来增强每个像素的特征。通过聚合属于指定类别的每个像素深度-觉察特征,可以计算每个深度类别(视为深度原型)的特征中心。在实践中,首先对预测的深度图D应用组卷积(group convolution),合并相邻的深度类别(BIN),将类别数从D减少到D′=D/r,其中尺度标量为r。这个措施,有助于共享相似的深度线索并减少计算。深度原型Fd的表征通过收集所有像素X′的特征来生成,该特征根据其概率加权到深度类别d:
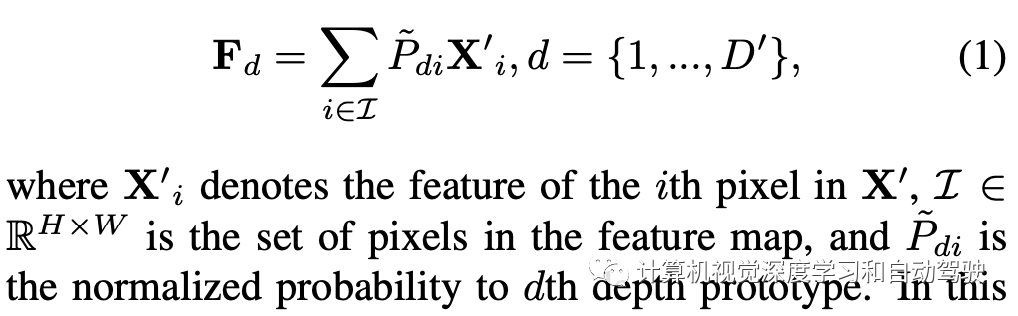
然后可以基于深度原型表征重建新的深度-觉察特征,其允许每个像素从全局视图理解去深度类别的表征。重构特征F′计算如下:
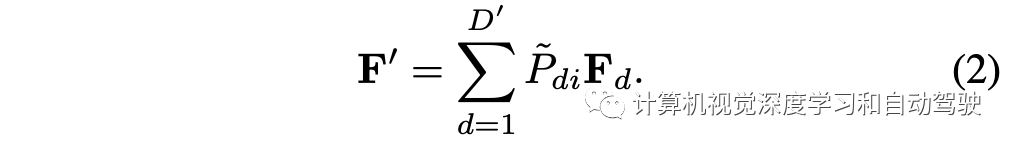
如图所示是深度-觉察特征增强(DFE)模块的体系结构:DFE模块旨在通过辅助监督隐式学习深度-觉察特征,(a) 生成初始深度-觉察特征X并预测深度分布D;(b)估计深度原型的特征表征Fd;(c) 制作深度原型增强特征F′,并与初始深度-觉察特征X融合。
transformer编码器旨在改进上下文-觉察特征,给定输入:查询Q,键K和值V,序列长度为N,单头自注意层可以简单地表示为:
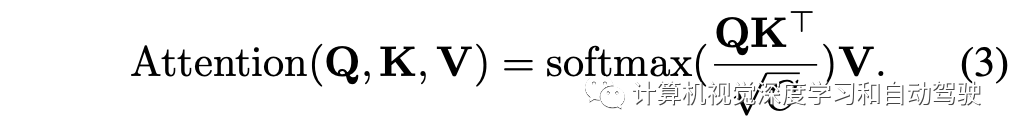
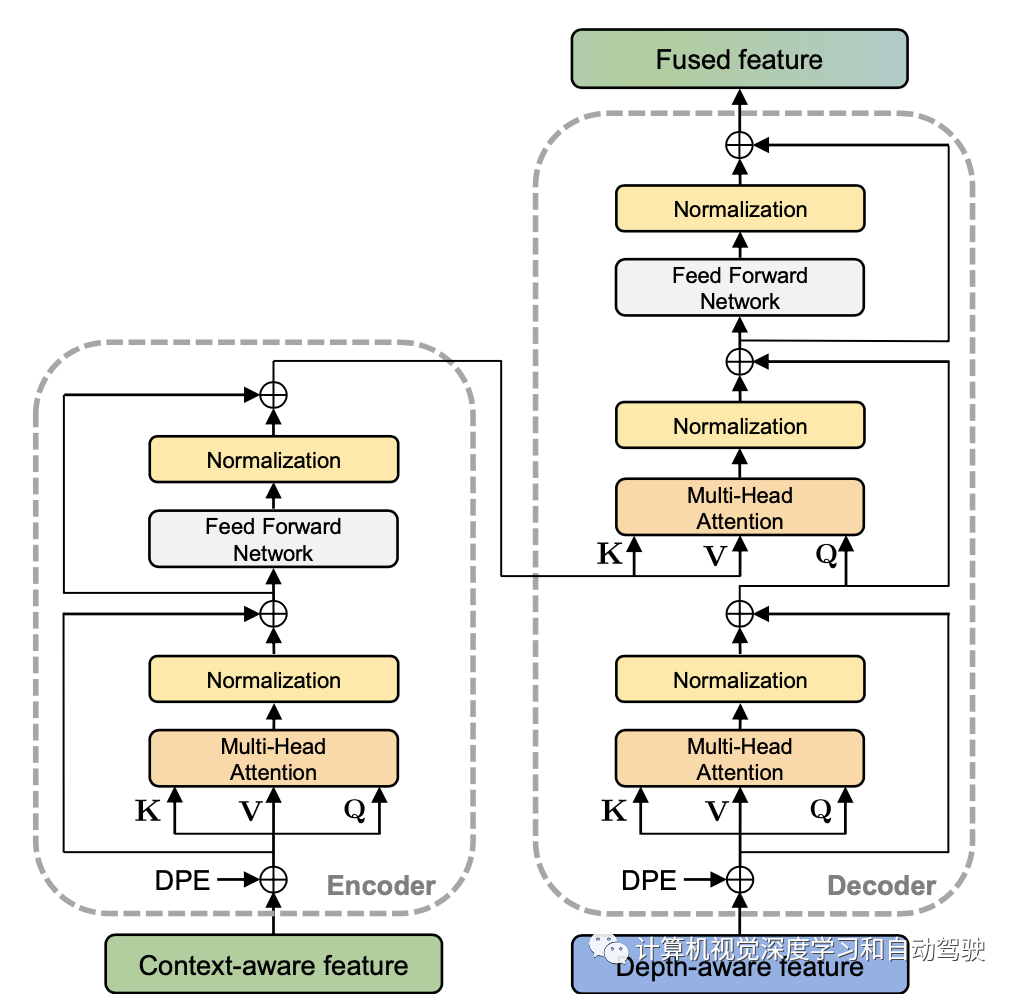
采用扁平化上下文-觉察特征Xc,作为输入馈入Transformer编码器。编码后的上下文-觉察特征可以通过多头自注意操作和前馈网络(FFN)获得。
解码器也构建在标准Transformer架构上。建议使用深度-觉察特征作为解码器的输入,而不是可学习的嵌入(目标查询),这与之前编码器-解码器视觉transformer工作中的常见用法不同。主要原因是,在单目3D目标检测任务中,由于透视投影,近距离和远距离的摄像头视图通常会导致目标大小发生显著变化。它使得简单的可学习嵌入难以充分表示目标的属性以及处理复杂的尺度变化情况。相反,在深度-觉察特征中隐藏了大量的距离-觉察线索。
因此,建议采用深度-觉察特征作为Transformer解码器的输入。为此,解码器可以利用Transformer交叉注意模块的特征,有效地建模上下文特征和深度-觉察特征之间的关系,从而获得更好的性能。
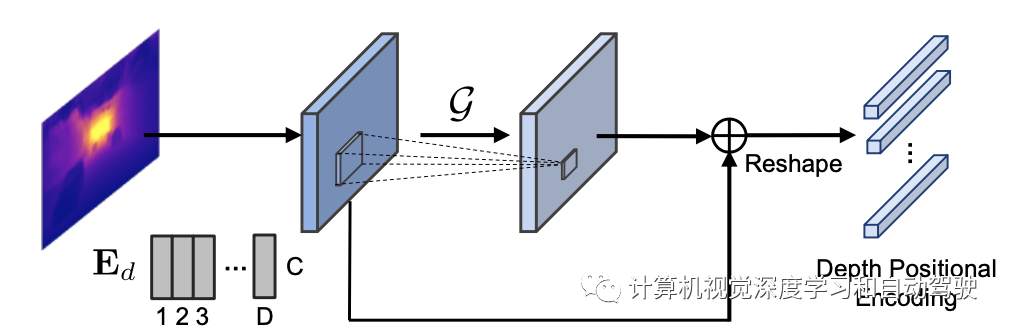
位置编码对于transformer引入位置信息起着重要作用,通常使用正弦函数生成,或根据视觉任务中图像的像素位置以可学习的方式生成。观察到深度信息比像素级关系更便于机器理解3D世界,这里提出一个通用的深度位置编码(DPE)模块,将每个像素的深度位置提示嵌入到Transformer中。
如图所示:深度bin编码Ed=[e1,…,ed]对每个深度间隔由可学习的嵌入构成;初始深度位置编码P,根据每个像素预测深度类别D的argmax,从Ed中查找;为了进一步表示来自局部邻域的位置线索,应用核大小为3×3的卷积层G并将其添加到P以获得最终编码,称为深度位置编码(DPE)。
在transformer实现中,应用线性注意来取代普通的自注意,获得更高的推理速度。
深度-觉察转换器(DTR)的详细架构如图所示:编码器旨在生成编码的上下文-觉察特征,而解码器通过多个自注意层从上下文-觉察特征和深度-觉察特征生成融合特征。此外,在将两个特征传递给transformer之前,用建议的深度位置编码(DPE)来补充这两个特征,从而实现更好的3D推理。
带有预定义2D-3D锚点的单步检测器,用于回归目标边框。每个预定义的锚点由2D边框[x2d、y2d、w2d、h2d]和3D边框[xp、yp、z、w3d、h3d、l3d、θ]的参数组成。[x2d,y2d]和[xp,yp]表示投影到图像平面的2D长方体中心和3D目标中心。
[w2d、h2d]和[w3d、h3d、l3d]分别表示2D和3D边框的物理尺寸。z表示3D目标中心的深度。θ是观测角。在训练期间,将所有真值投影到2D空间,计算与所有2D锚点的IoU。选择IoU大于0.5的锚点与相应的3D框一起分配,进行优化。
按照Yolov3预测每个锚点的2D参数【tx、ty、tw、th】和3D参数【tx、ty、tw、th、tl、tz、tθ】,旨在参数化2d和3d边框的残差值,并预测分类分数cls。可以根据锚点和网络预测恢复输出边框,如下所示:
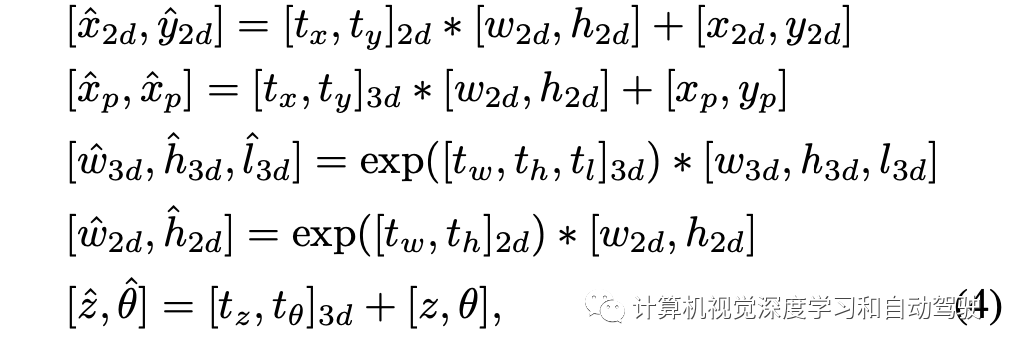
损失函数定义:
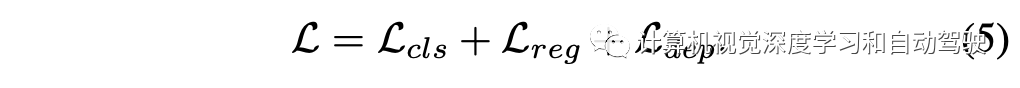
其中类别项采用focal loss,回归项采取smooth- L1 loss,而深度项定义为focal loss
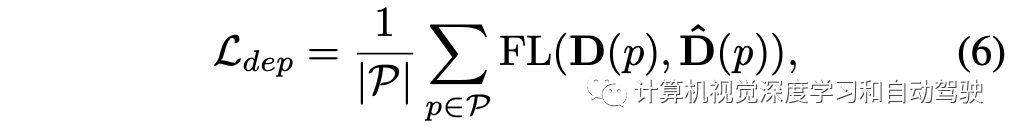
实验结果如下:
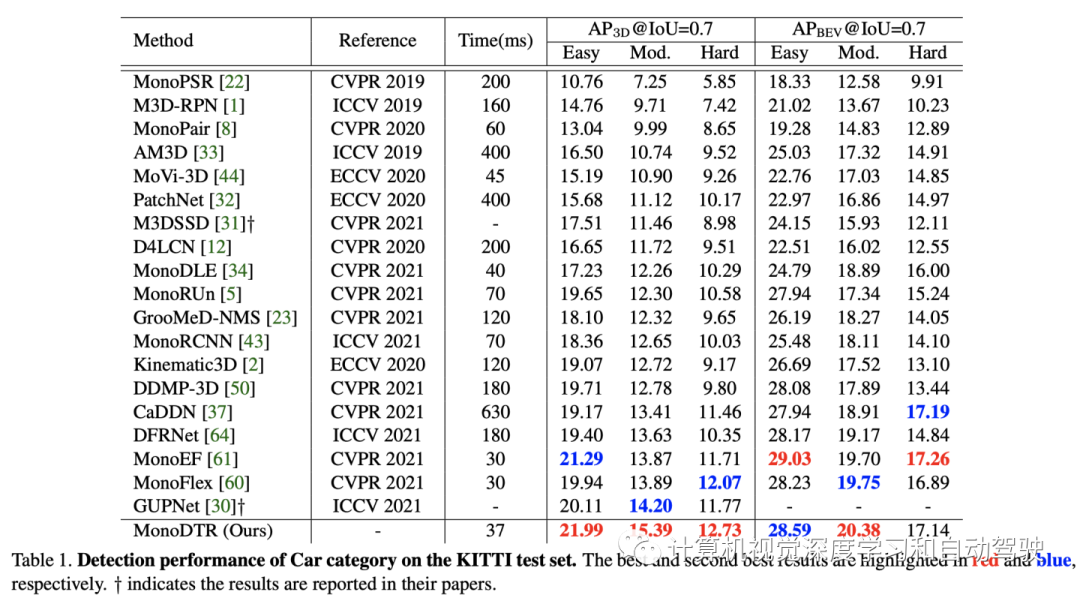
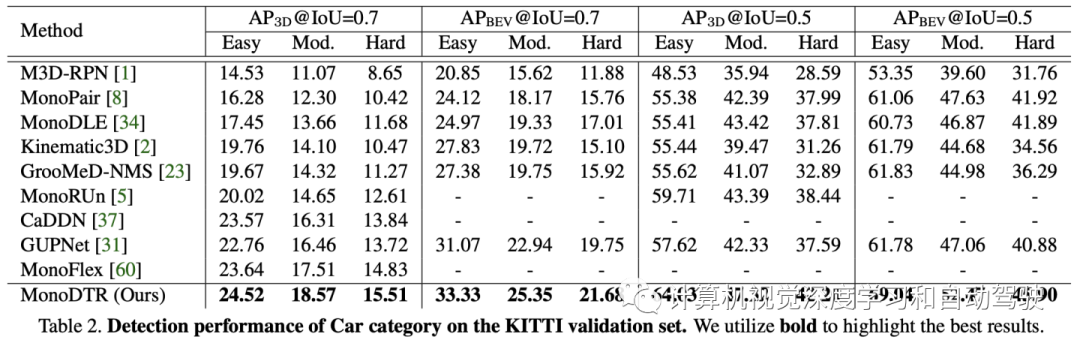
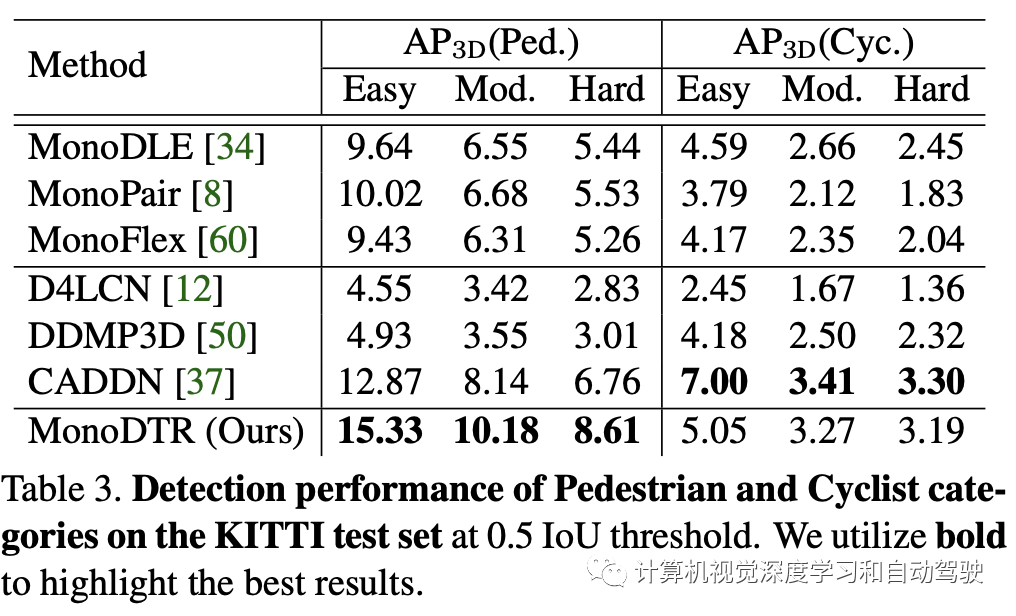

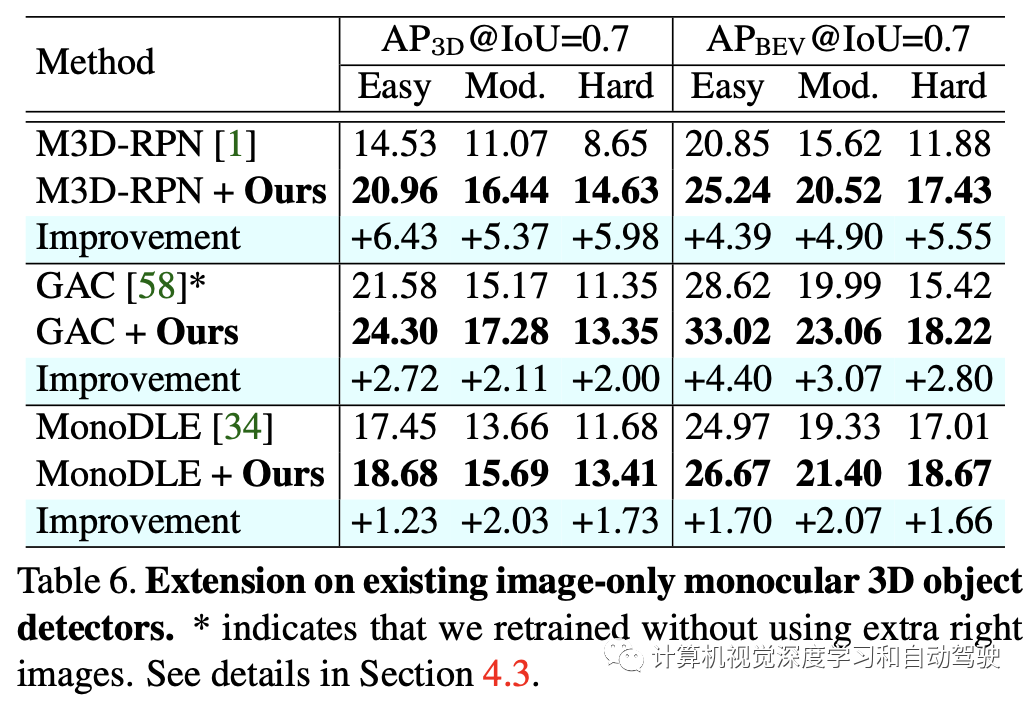
注:表中几个比较方法的开源代码
https://github.com/garrickbrazil/M3D-RPN
https://github.com/Owen-Liuyuxuan/visualDet3D
https://github.com/xinzhuma/monodle








