绑定手机号
确认绑定









人工智能/机器学习(AI/ML)在全球范围内的迅速兴起,正推动着制造业、交通、医疗、教育和金融等各个领域的惊人发展。从2012年到2019年,人工智能训练能力增长30万倍,平均每3.43个月翻一番,就是最好的例证。而IDC《2021年全球数据圈(Global Datasphere 2021)》报告则显示,2018-2024年,全球数据总量将从36泽字节增长至146泽字节。因此,支持这一发展速度需要的远不止摩尔定律,人工智能硬件和软件的各个方面都需要不断的快速改进,内存带宽就是其中之一。

图1:2012-2019年,人工智能训练能力增长30万倍(图片来源:openai.com)
以先进的驾驶员辅助系统(ADAS)为例,L3级及更高级别系统的复杂数据处理需要超过200GB/s的内存带宽。这些高带宽是复杂AI/ML算法的基本需求,自动驾驶过程中需要这些算法快速执行大量计算并安全地执行实时决策。而在L5级,如果车辆要能够独立地对交通标志和信号的动态环境做出反应,以便准确地预测汽车、卡车、自行车和行人的移动,将需要超过500GB/s的内存带宽。
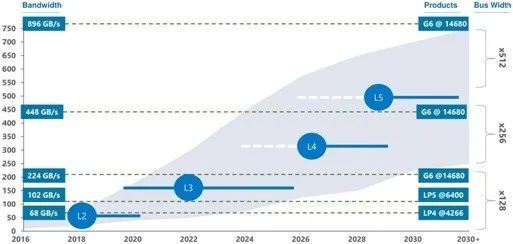
图2:不同ADAS级别对存储带宽的要求(图片来源:anandtech.com)
数据中心是另一个需要应用架构师尽快找到高带宽方案的领域。按照美光全球显存业务主管Bill Randolph的说法,随着数据密集型工作负载和应用程序的增长,以及不断演变的应用场景和新兴业务机会的出现,“我们很难想象将一个拥有超过13亿个参数的AI模型放入单个GPU(即使是拥有32GB内存)中进行处理。”
于是,人们改变了传统数据中心“CPU+内存(如DDR4)+存储(如SSD)”的数据处理方式,转而走进“异构数据中心”时代,即通过部署CPU、GPU、DPU、FPGA和ASIC等各种组件,分别侧重于提供特定功能或者处理不同类型和格式的数据,从而显著提高整个系统的速度和性能。
这就是以高带宽内存(HBM、HBM2、HBM2E、HBM3)为代表的超带宽解决方案开始逐渐显露头角的原因——通过增加带宽,扩展内存容量,让更大的模型/更多的参数留在离核心计算更近的地方,从而减少内存和存储解决方案带来的延迟。

图3:高性能应用驱动着高带宽内存的发展
HBM的演进
高带宽内存(HBM)于2013年推出,是一种高性能3D堆栈SDRAM构架,数据传输速率大概可以达到1Gbps左右。
与前一代产品一样,2016年推出的HBM2为每个堆栈包含最多8个内存芯片,同时将管脚传输速率翻倍,达到了2Gbps。HBM2实现每个封装256GB/s的内存带宽(DRAM堆栈),采用HBM2规格,每个封装支持高达8GB的容量。
2018年末,JEDEC宣布推出HBM2E规范,以支持增加的带宽和容量。当传输速率上升到每管脚3.6Gbps时,HBM2E可以实现每堆栈461GB/s的内存带宽。此外,HBM2E支持最多12个DRAM的堆栈,内存容量高达每堆栈24GB。
HBM2E提供了达成巨大内存带宽的能力。连接到一个处理器的四块HBM2E内存堆栈就将提供超过1.8TB/s的带宽。通过3D堆叠内存,可以以极小的空间实现高带宽和高容量需求。
在NVIDIA最新一代的SXM4 A100 GPU上,就使用了HBM2E内存。从芯片内部结构图上可以看到,A100计算核心的两侧总共有6个HBM内存的放置空间。在SXM4 A100 GPU发布的时候,NVIDIA实际只使用了这6个HBM内存放置空间中的5个,提供40GB HBM2E内存容量,这意味着单个HBM2E内存上有8个1GB DRAM Die进行堆叠。对于升级版的80GB SXM4 A100 GPU,单个HBM2E内存上则采用了8个2GB DRAM Die进行堆叠。

图4:NVIDIA A100 80GB GPU
而到了2021年,尽管JEDEC尚未发布HBM3相关标准,但SK海力士和Rambus已先后发布最高数据传输速率5.2Gbps和8.4Gbps的HBM3产品,每个堆栈将提供超过665GB/s和1075GB/s的传输速率,这无疑是极为惊人的。(相关信息可参见本刊《4Gbps!HBM2E内存接口再现性能标杆》、《HBM2E:超带宽解决方案中的明星》、《HBM3:没有最快,只有更快!》等报道)

图5:HBM性能演进(图片来源:Rambus)
硅堆叠的奇迹
众所周知,HBM技术与其他技术最大的不同,就是采用了3D堆叠技术。对比HBM2E/HBM3、DDR、GDDR就会发现,它们的基本单元都是基于DRAM,但不同之处在于其他产品采用了平铺的做法,而HBM选择了3D堆叠,其直接结果就是接口变得更宽。比如DDR的接口位宽只有64位,而HBM2E通过DRAM堆叠的方式就将位宽提升到了1024位,这就是HBM与其他竞争技术相比最大的差异。
图6、图7分别展示了美光HBM2E和Rambus HBM3内存子系统产品的主要架构。通过硅通孔(TSV)堆叠方式叠加在一起的DRAM内存条、SoC、中介层和封装,它们共同组成了整个3D的系统架构。
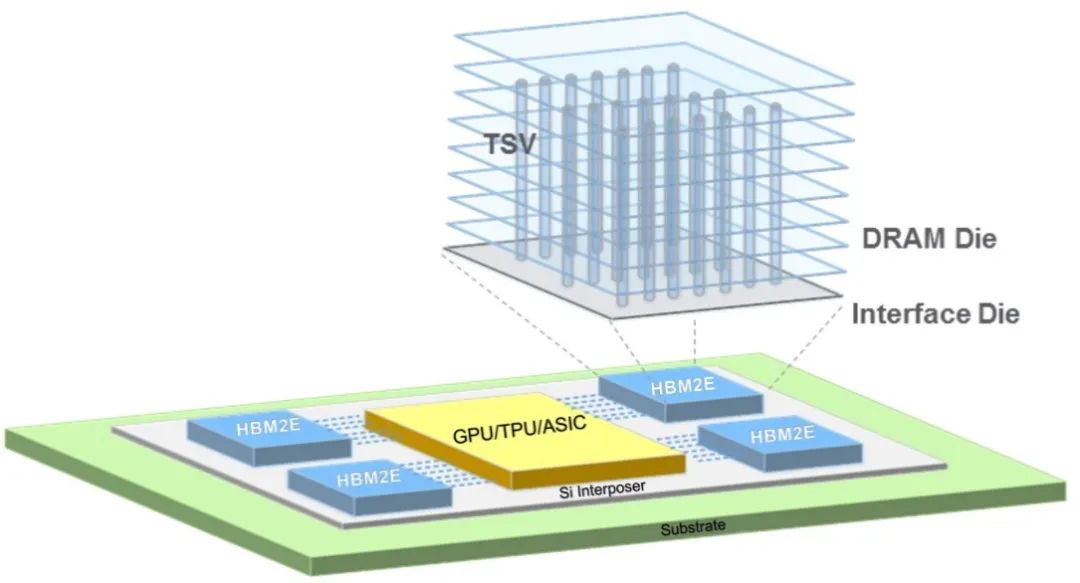
图6:美光用于HBM2E的垂直堆叠DRAM,并通过TSV通道连接各层(图片来源:美光)
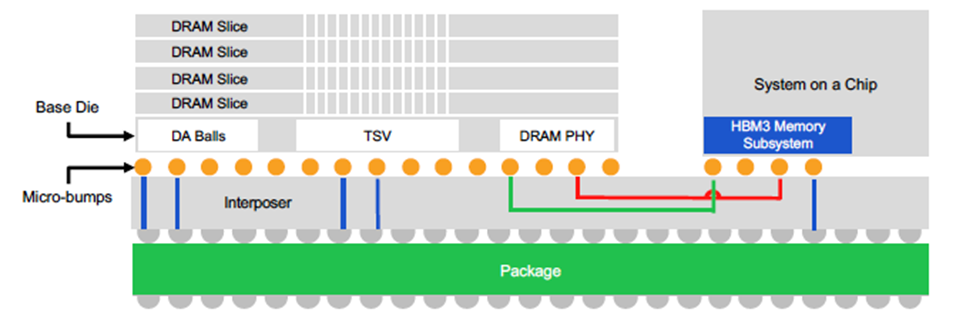
图7:Rambus HBM3-Ready内存子系统产品主要架构(图片来源:Rambus)
“目前来看,HBM的发展可能不会遇到障碍。但对比GDDR DRAM动辄16/18Gbps的速率,HBM3的速率即便达到8.4Gbps,也仍然存在差距,而限制HBM发展的原因则主要来自两方面:一是中介层,二是3D堆叠带来的制造成本。”Rambus IP核产品营销高级总监Frank Ferro说。
对中介层进行完整的设计和表征化处理,以确保信号完整性,即为挑战之一。因为HBM作为高速内存接口,在与中介层互联的过程中包括至少上千条不同的数据链路,必须要确保所有链路的物理空间得到良好的控制,整个信号的完整性也必须得到验证。因此,从表征化层面来讲,不但需要对整个中介层的材料做出非常精细的选择,还要考虑渐进层的厚度以及整个电磁反射相关的物理参数,并在此基础上进行完整的分析和仿真,以实现信号一致性的处理。
然而,如前文所述,在人工智能训练领域和数据中心应用中,HBM2E/HBM3的优点使其成为一个更好的选择。尽管在过去几年内,HBM、HMC、PAM4等标准在市场上展开了激烈的竞争,但从目前的发展态势来看,还是HBM占据了更多的市场份额。
HBM的性能非常出色,这点毋庸置疑,所增加的采用和制造成本可以透过节省的电路板空间和电力相互的缓解。在物理空间日益受限的数据中心环境中,HBM紧凑的体系结构提供了切实的好处。它的低功率意味着它的热负荷较低,在这种环境中,冷却成本通常是几个最大的运营成本之一。
数据中心采取分布式内存的方法会给HBM2E、HBM3和GDDR长期的发展带来影响吗?答案可能是不会。原因在于尽管SRAM的速度和延迟性都高于DRAM,但在固定的芯片面积上能安装的SRAM数量却非常少,很多情况下为了满足人工智能训练的需求,一部分SRAM设备不得不装在芯片之外,这就是问题所在。但总体来说,这两种方案属于从不同角度出发解决同一个问题,两者之间是互补而非相互阻碍。
不过,坦率的说,至少在人工智能推理和汽车行业中,HBM技术还是不合适的。例如在汽车中,除了复杂性和成本因素,由于汽车安全等级要求很高,考虑到HBM本身采用的是复杂的2.5D/3D架构,再结合DRAM设备,所以目前为止在汽车市场上并没有得到突破性的应用,相比之下,GDDR反而会是比较好的解决方案。
一点点“疯狂”的小想法
既然在HBM2E阶段就实现了达成巨大内存带宽的能力,那么是否有可能进一步,使内存靠近处理器,让总体系统功耗得以维持在较低水平?
三星电子是这么想的,也是这么做的。据报道,他们的HBM2E不但保持每个堆栈8个裸片和3.2Gb/s的信号传输速率,达到每个堆栈16GB和每个堆栈410GB/s,而且还直接在HBM2E内存堆栈内部嵌入处理,因此数据不必总是传输到CPU或连接到CPU的加速器进行处理和重新存储。
三星表示,自研的HBM-PIM(存内计算,Process In Memory)设备在存储器和TSV之间添加了1.2 Teraflops可编程计算单元,与在其加速器上使用HBM内存的系统相比,HBM-PIM内存将使AI工作负载的整体系统性能提高2倍,并将功耗降低了70%。
既然这样,那我们如果再“疯狂”一点,会如何?比如,有没有设想过拥有一台具备若干GB HBM3内存的笔记本电脑?CPU和GPU可以共享相同的内存?把数据处理放在HBM3-PIM中进行?价格/性能曲线像我们预期的那样下降?……这些想法现在看起来多少有些“天方夜谭”的感觉,但万一实现了呢。








