绑定手机号
确认绑定









arXiv论文“BEVDepth: Acquisition of Reliable Depth for Multi-view 3D Object Detection“,上传于2022年6月21日,作者来自旷视科技、华中理工和西安交大。

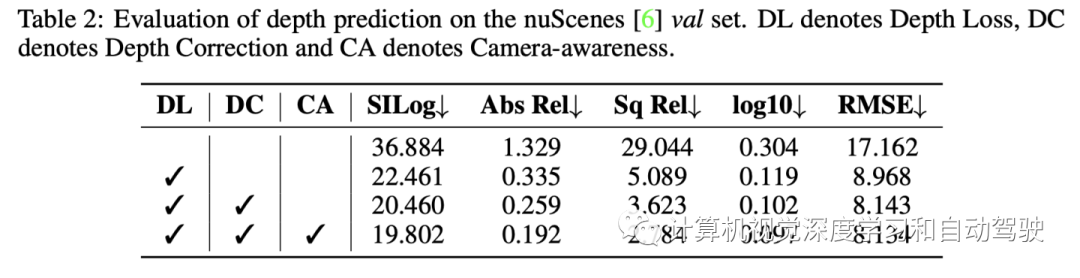
本文提出一种有可靠深度估计的3D目标检测器,称为BEVDepth,用于基于摄像头的BEV 3D目标检测。分析发现深度估计是在没有摄像头信息的情况下隐含学习的,实际上是创建伪点云的伪深度。BEVDepth利用编码的内外参获得显式深度监督信号。进一步引入深度校正子网络,可以抵消深度真值中投影导致的干扰。
为了减少采用估计深度将特征从图像视图投影到BEV的速度瓶颈,文章提出一种快速视图变换操作。此外,BEVDepth可以通过多帧输入轻松扩展。BEVDepth在具有挑战性的nuScenes测试集上实现最新的60.0%NDS指标,同时保持较高的效率。摄像头和激光雷达之间的性能差距首次大幅缩小到10%NDS以内。
基于摄像头的3D目标检测,尤其是在自动驾驶领域以其高效性和丰富的语义信息而备受关注。最近基于视觉的技术主要依赖于给定多个摄像头图像的像素级深度估计。然后添加一个视图变换子网络,将特征从图像视图投影到BEV中,同时显示内外参信息。尽管这些基于深度的3D检测器很受欢迎,但人们自然会问:这些检测器内深度估计的质量和效率如何?它是否满足精确有效的3D目标检测的要求?
回顾基于深度的3D检测方法,有以下经验认识:
最终检测损失,鼓励网络的中间层输出正确的深度,建立隐式深度监督作用。然而,深层神经网络通常具有复杂的表示形式。如果没有明确的深度监督,网络很难准确输出深度-觉察特征。
深度子网络,理论上应了解摄像头信息,以便从图像中正确推断深度。然而,现有方法对摄像头参数视而不见,导致较差的结果。
当用相同的图像分辨率和主干网时,基于深度的3D检测器速度,在经验上比FCOS3D等无深度的检测器速度慢,因为深度估计后的视图变换子网络效率极低。
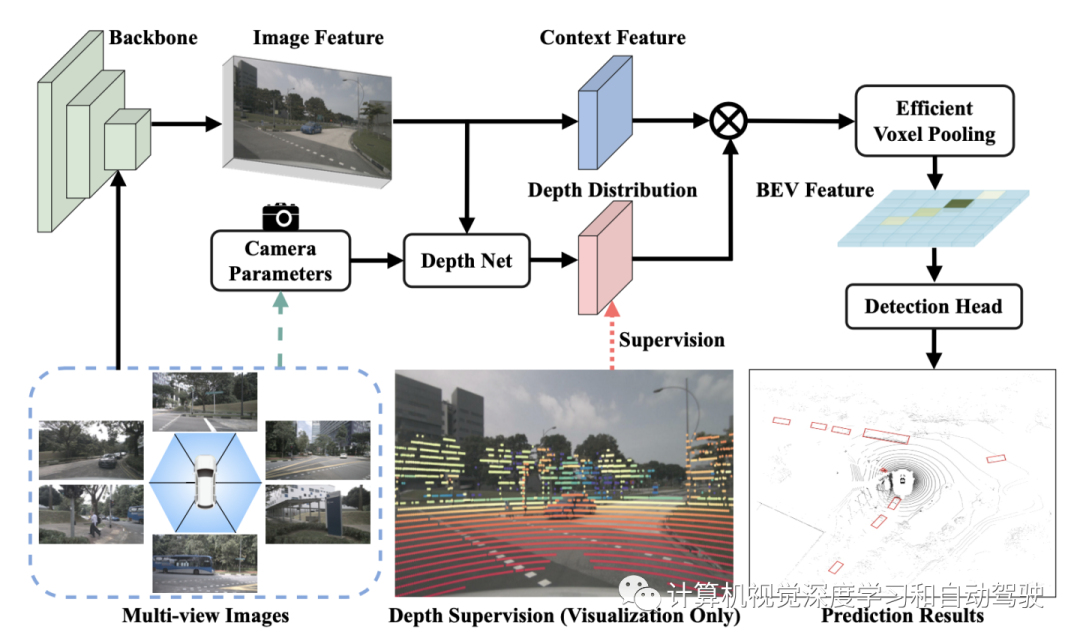
如图所示,从一个普通的BEVDepth开始,简单地将LSS中的分割头替换为用于3D检测的CenterPoint头,由四个主要组件组成:1) 一种图像编码器(如ResNet),用于从N个视图输入图像I提取2D特征F2d;2) 一个DepthNet根据图像特征F2d估计图像深度;3) 一个视图Transformer,按照如下公式将F2d投影到3D表示F3D,然后将其池化到BEV集成表示Fbev;4)3D检测头预测类别、3D框偏移和其他属性。
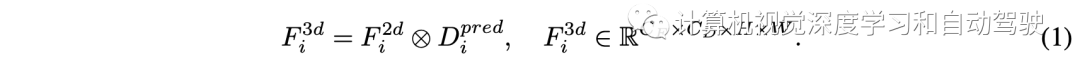
在普通BEVDepth中,对深度模块的唯一监督来自检测损失。然而,由于单目深度估计的困难,单一的检测损失远远不足以监督深度模块。
因此,建议从点云数据P导出的真值深度Dgt来监督中间深度预测值Dpred。Ri和ti是自车坐标系到第i个视图摄像头坐标系的旋转和平移,Ki是第i个摄像头内参。为获得Dgt,首先计算:
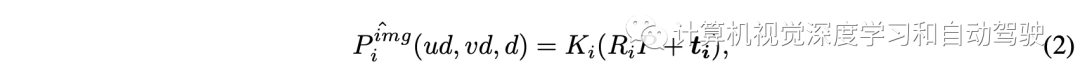
为了投影点云和预测深度之间形状对齐,Pimg上采用最小池化和one-hot操作。将这两个运算联合定义为φ,由此产生的Dgt可以写成如下公式:
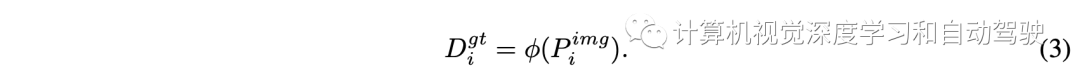
对于深度损失Ldepth,只采用二元交叉熵(BCE)。
在深度监督的帮助下,DepthNet应该能够生成可靠的Dpred。由于自车的剧烈运动,校准的摄像头参数R和t有时可能不精确,导致F2d和Dgt之间的空间偏离。当DepthNet的感受野受到限制时,偏离问题变得更加严重。
因此,提出了一个深度校正模块来缓解这个问题。另一方面,深度校正模块增加DepthNet的感受野,以解决偏离问题,而不是根据自车干扰来调整Dgt。
具体而言,在DepthNet中堆叠多个残差块,然后是可变形块,如图depthnet架构所示:上下文特征直接由图像特征生成,而设计的SE(Squeeze-and-Excitation)类层变型与图像特征聚合,更好地估计深度。
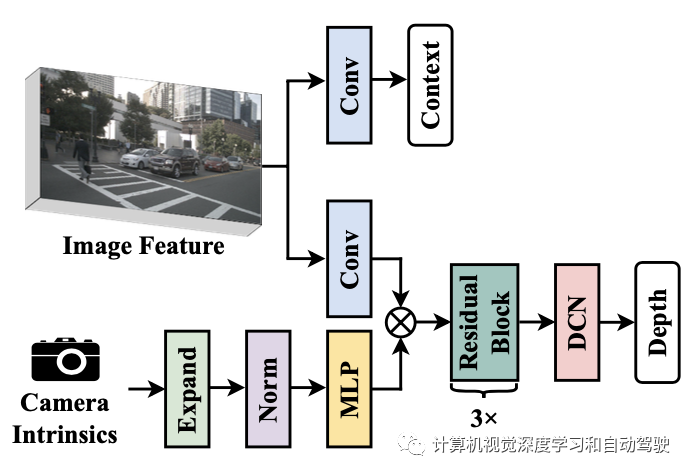
得益于感受野的改善,偏移的深度gt能够在正确的位置处理好这些特征F2d。
上述设计提高模型的深度预测能力。然而,根据经典的摄像头模型,估计像素深度与摄像头内参相关,这意味着为DepthNet对摄像头内参建模是非常重要的。在多视图3D数据集中,这尤其重要,因为摄像头可能具有不同的FOV(例如,nuScenes数据集)。
因此,为提高估计深度Dpred的质量,建议使用摄像头内参作为DepthNet的输入之一。具体来说,首先用MLP层将摄像头内参的尺度放大到特征的尺度。然后,用Squeeze-and-Excitation模块重新加权图像特征F2d。最后,将摄像头外参和其内参连接在一起,帮助DepthNet了解F2d在自车坐标系中的空间位置。将ψ表示为原始深度网,整体摄像头-觉察的深度预测可写为:

已有方法也利用摄像头-觉察。其根据摄像头的内参来尺度化回归目标,造成他们方法很难适应具有复杂摄像头设置的自动化系统。另一方面,本文方法在DepthNet内对摄像机参数进行建模,旨在提高中间深度的质量。得益于LSS的解耦特性,摄像头-觉察的深度预测模块与检测头脱离开,因此在这种情况下,回归目标无需更改,获得更大的可扩展性。
体素池化(Voxel Pooling)是BEV检测器的关键,其目的是将3D多视图特征聚合为一个完整的BEV特征。一般来说,它将自车空间划分为几个均匀分布的网格,然后将落入同一网格的截锥(frustum)特征汇总,形成相应的BEV特征。
为此,LSS利用了一种“累计求和技巧(cumsum trick)”,即根据相应的BEV网格ID对所有截头特征进行排序,对所有特征进行累积求和,然后减去bin部件边界的累积和。这样的实现会带来大量额外计算,因为需要对大量的BEV坐标进行排序。此外,该技巧采用的顺序运行前缀和(Prefix Sum),效率不高。
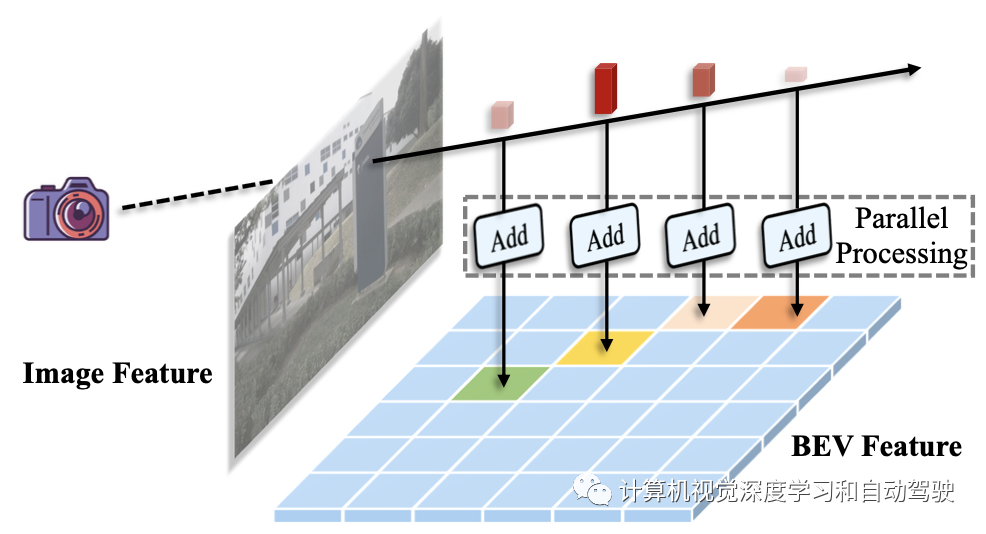
这两个缺陷都会影响检测器的整体运行速度。人们可以选择提高并行性来加速前缀和,这项工作中,我们介绍一种更好但更简单的解决方案,该解决方案充分利用了GPU资源的高度并行性,称为高效体素池化(Efficient Voxel Pooling)。
如图所示:主要想法是为每个截锥特征分配一个CUDA线程,该线程用于将该特征添加到相应的BEV网格中;用改进的高效体素化替换原来的体素池化操作可以将BEVDepth加速到3倍。
3D 检测任务, 采用以下测度 nuScenes Detection Score (NDS), mean Average Precision (mAP), 还有5个 True Positive (TP) metrics,包括mean Average Translation Error (mATE), mean Average Scale Error (mASE), mean Average Orientation Error (mAOE), mean Average Velocity Error (mAVE), mean Average Attribute Error (mAAE)等。
对深度估计任务,按照标准评估策略来操作, 即scale invariant logarithmic error (SILog), mean absolute relative error (Abs Rel), mean squared relative error (Sq Rel), mean log10 error (log10) 和 root mean squared error (RMSE) 等。
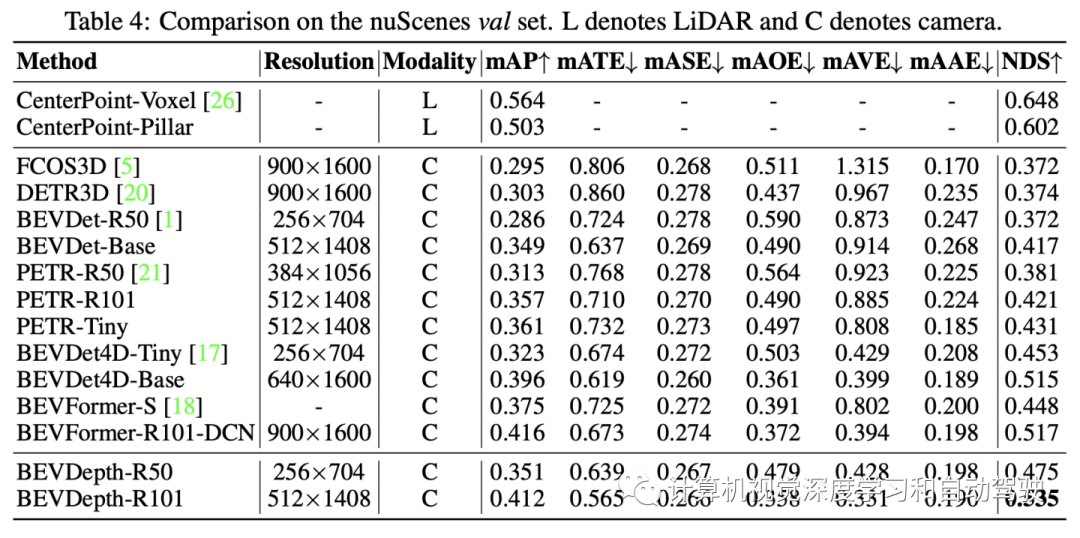
实验结果如下:

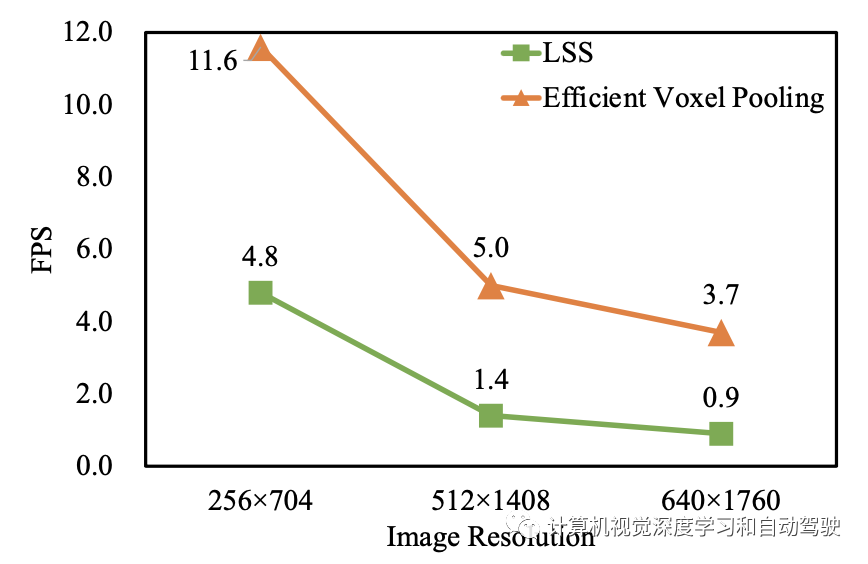
FPS比较
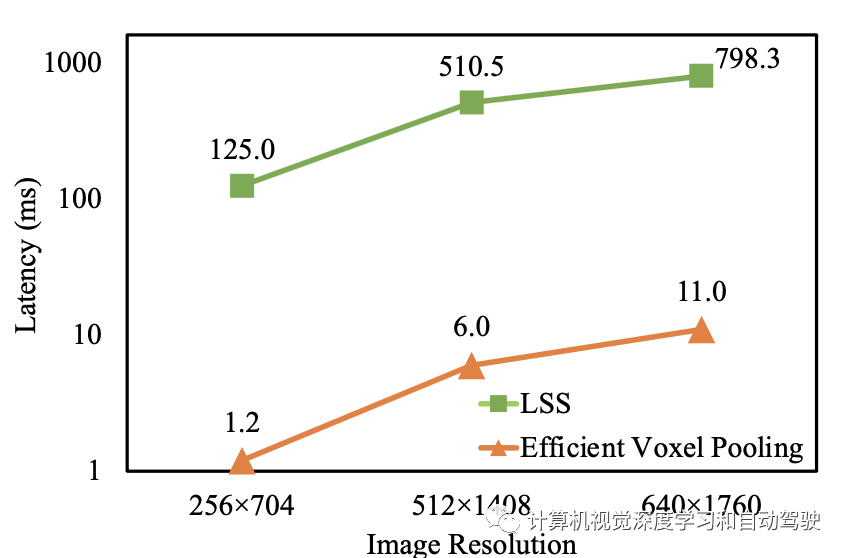 延迟比较
延迟比较
多帧融合主要针对激光雷达点云,如图是其序列建模方法:
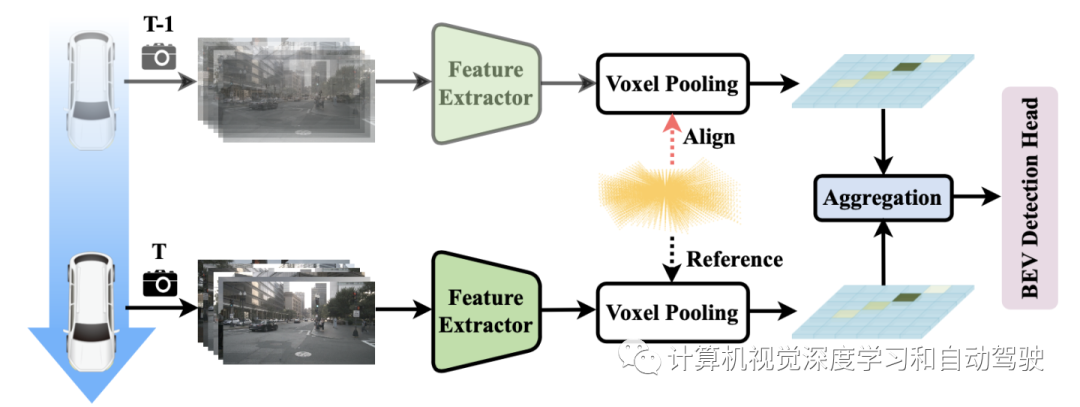
在做高效体素池化前,连续帧对齐即
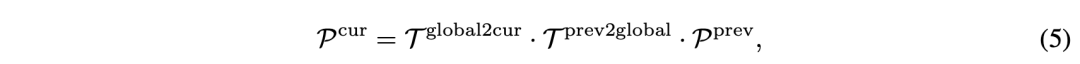
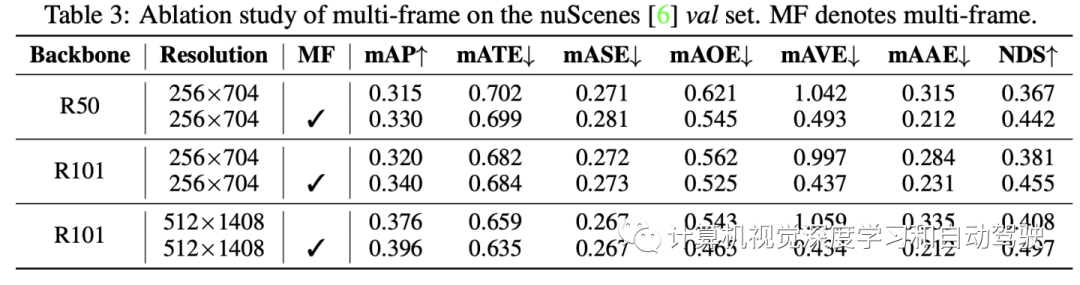
和各种方法比较结果:

基准方法和BEVDepth比较








