绑定手机号
确认绑定









前言 论文提出了一个新的框架,“prune, then distill”,该框架首先剪枝模型,使其更具可移植性,然后提取给student。并进一步从理论上证明了剪枝后的teacher在蒸馏中起到正则化器的作用,减少了泛化误差。
在此基础上,还提出了一种新的神经网络压缩方案,其中student网络是基于剪枝后的teacher,然后应用“prune, then distill”策略。

论文:https://arxiv.org/pdf/2109.14960.pdf
代码:https://github.com/ososos888/prune-then-distill
神经网络压缩技术受到越来越多的关注,如知识蒸馏和剪枝。知识蒸馏(KD)是一种模型压缩工具,它将特征从一个繁琐的网络转移到一个较小的网络。最近,一系列研究提出了专注于“student友好型”teacher的蒸馏方案,这种teacher在有限的容量下向student网络提供更多可转移的知识。
网络剪枝是另一种网络压缩技术,它可以有效地去除网络的权值或神经元,同时保持准确性。由于剪枝简化了神经网络,剪枝后的teacher提供的知识对student友好,更容易转移。但引发了一个主要问题:剪枝能够提高知识蒸馏的性能吗?
为了回答这个问题,本文提出了一个新的框架,“prune, then distill”,包括三个步骤:
1)训练teacher网络;
2)剪枝teacher网络;
3)提取剪枝后的网络到更小的student网络。
知识蒸馏可以看作是一种标签平滑正则化(LSR),它通过提供更平滑的标签来正则化训练。作者发现,经过正则化训练的teacher比原来的teacher提供了一个更平滑的标签。这意味着,正则化的teacher的蒸馏等价于标签更平滑的LSR。由于剪枝可以看作是一个正则化的模型,具有一个稀疏诱导正则化器,得出剪枝后的teacher正则化了蒸馏过程。
在此基础上,作者提出了一种新的网络压缩方案。当提供了一个麻烦的网络时,通过应用“prune, then distill”策略来压缩网络。然而,由于蒸馏将知识转移到给定的student网络,因此,作者提出了一种深度相同但神经元数量较少的student网络,使每层的权值数量与相应层中剪枝后的网络的非零权值数量匹配。
1.提出了一个新的框架,“prune, then distill”,在提取之前先剪枝teacher网络。
2.通过实验验证了teacher的非结构化剪枝可以提高知识提取的表现。
3.提供了一个理论分析,一个剪枝的teacher的蒸馏是一个有效的标签平滑正则化与更平滑的标签。
4.提出了一种新的网络压缩方法,在剪枝teacher的基础上构建student网络,然后应用“prune, then distill”策略。
prune, then distill
探索性实验
作者通过实验来验证剪枝后的teacher在KD方面的有效性。没有直接提取teacher网络(图1中蓝色点的方块),而是先(非结构化)对teacher网络进行剪枝,然后提取到student网络(图1中红色点的方块)。

图1:“prune, then distill”策略。
采用非结构化剪枝,去除更多的权值,更精确的LR 复卷,来剪枝teacher模型。
实验的目的不是获得最佳的测试精度,而是比较从剪枝过的网络中提取和从未剪枝过的网络中提取。如表1所示,经过剪枝的VGG19的VGG11始终优于未剪枝的teacher的VGG11。表1还给出了teacher网络为VGG19DBL。在这两种情况下,剪枝过的teacher表现得更好。
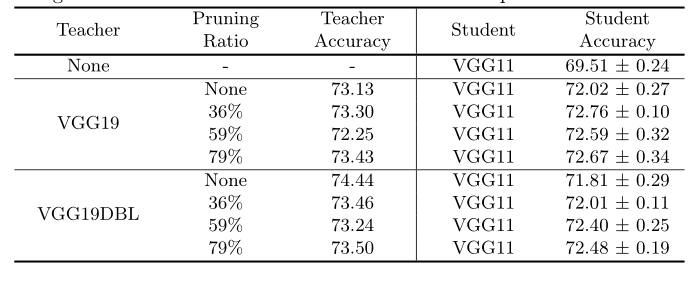
表1:CIF AR100上VGG19到VGG11的知识提取,teacher剪枝。
自我蒸馏:作者进行了自我蒸馏实验,teacher和student共享相同的模型。
表2显示了
1)没有KD的模型,
2)从未剪枝的teacher那里学习到的模型,
3)从剪枝过的teacher那里学习到的模型的测试精度。

表2:对VGG19和ResNet18进行teacher剪枝的自蒸馏。
与其他实验类似,作者也观察到与没有teacher的网络相比,从未经剪枝的网络中学习也增加了测试的准确性,然而,经过剪枝的teacher的收获更显著。
作者还研究了当student和teacher拥有不同的网络架构时,剪枝后的teacher的KD。
表3比较了
1)没有teacher的student,
2)从未经修饰的teacher那里学习的student
3)从经过修饰的teacher那里学习的student的测试准确率。
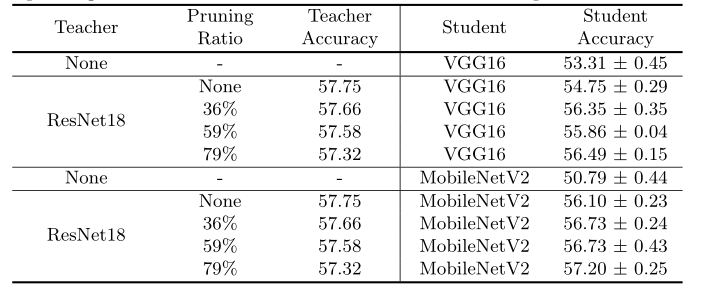
表3。从ResNet18提取到MobileNetV2和VGG16,并进行teacher剪枝。
观察到,当teacher被剪枝时,KD的表现会更好。这意味着更好的提取并不局限于teacher和student网络之间的类似架构。然而,teacher网络的精度越高,并不能保证蒸馏的结果越好。此外,即使在测试准确性低于未受过训练的teacher时,受过训练的teacher也能发挥更好的作用。这意味着,剪枝过的teacher更好,不是因为它有更高的准确性,而是因为它提供了更好的可转移知识。
另外,作者还观察到一致性和准确性表现独立。例如,在VGG19自蒸馏实验中,剪枝后的teacher提供了更高的一致性,对应的student提供了更高的准确性;而在ResNet18自我蒸馏中,尽管student的准确率更高,但经过剪枝的teacher的一致性较低。这意味着一些student模仿teacher模仿得更好,但表现得更差。这一结果说明蒸馏间接地帮助训练student模型与额外的正则化。
剪枝后的teacher作为正则化器
使用正则化器训练的teacher在蒸馏过程中提供了额外的正则化。
最小交叉熵损失为:

知识蒸馏损失为:
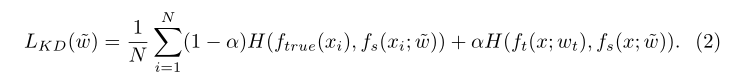
正则化teacher ft通过最小化得到:
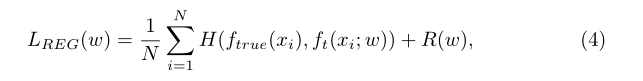
由于LCE(wt) = minw LCE(w),则有:
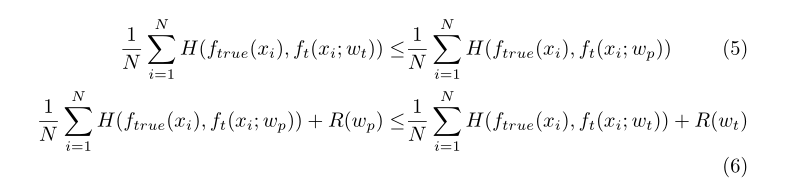
这意味着

剪枝可被视为具有稀疏性诱导正则化的经验风险最小化问题的解决方案。因此,从剪枝的teacher中提取的是具有更平滑的标签分布的标签平滑正则化,这减少了泛化误差。
传递稀疏性知识
基于剪枝teacher传递更好知识的观察,本文提出了一种新的网络压缩框架,该框架从(非结构化)剪枝网络中学习。关键的挑战是student网络体系结构设计,以有效地从剪枝过的teacher网络那学习。
student网络设计的关键思想是,经过剪枝的teacher也可以提供稀疏的知识。作者构造了一个较窄的student,其中每一层都与剪枝后的teacher的相应层相匹配。student网络具有相同的深度,但每层的通道数量减少,使得权重的数量(近似)等于剪枝后的teacher中剩余参数的数量(如图2所示)。

图2:student网络设计。
所提出的压缩算法有四个步骤:
1.训练原始网络并获得ft。
2.应用非结构化剪枝,得到剪枝后的网络ft。
3.基于剪枝网络ft的每层稀疏性构造fs。
4.将剪枝后的网络ft提取到studentfs。
该方案将知识从稀疏网络(非结构化剪枝)转移到具有较少信道的网络,以进一步减少信道数量。这类似于残余蒸馏,其去除残余网络的不需要部分。在本文的设置中,通过KD将稀疏滤波器合并到更少的滤波器中,来移除非结构化剪枝的不需要部分。

表4:所提出的压缩算法在具有CIF AR100的VGG19上的性能
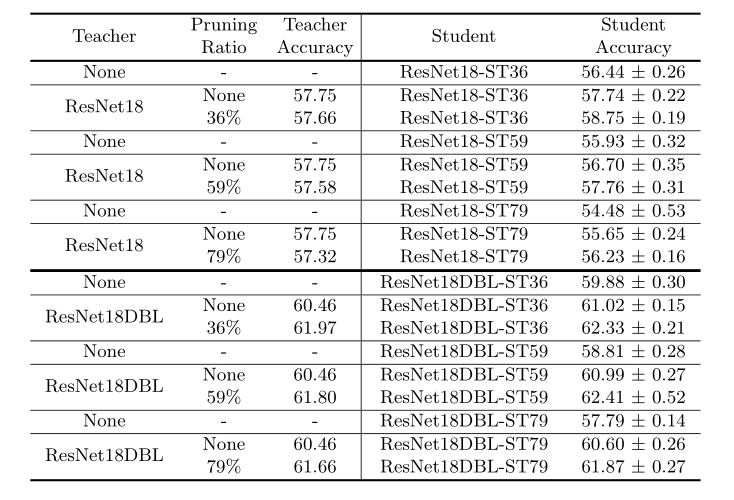
表5:使用TinyImageNet在ResNet18上提出的压缩算法的性能。
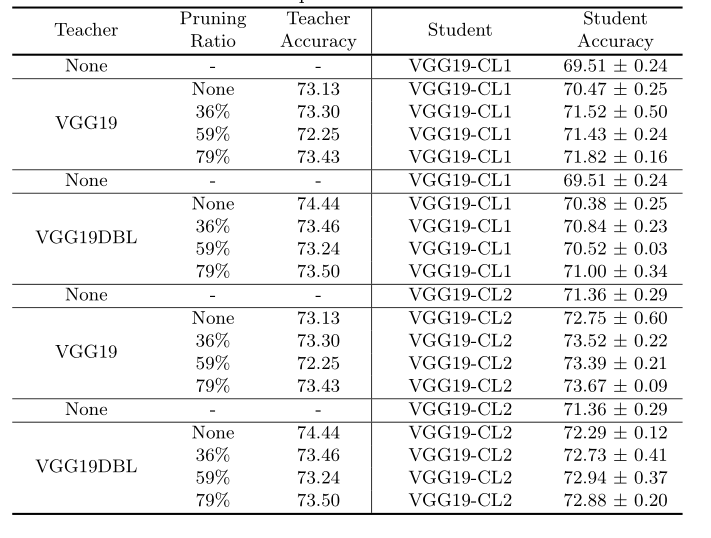
表6:人为设计的student网络的知识提取
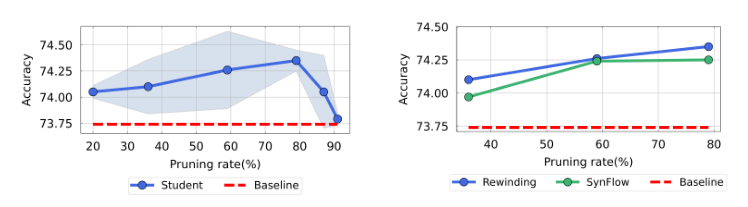
图3:剪枝比率和算法的影响。
本文的实验表明,在KD中,剪枝后的teacher可以比原始teacher更有效。作者进一步从理论上证明,经过剪枝的teacher在蒸馏中提供了额外的正则化。
基于这一观察,提出了一种新的网络压缩方案,将经过剪枝的teacher网络提取为student网络,student网络的体系结构基于(非结构化)剪枝网络。所提出的网络压缩是一种有效的结构化剪枝算法,它利用了非结构化剪枝的稀疏性知识。







