绑定手机号
确认绑定









浙江大学ReLER Lab团队投稿
智猩猩AI整理
3D Gaussian Splatting(3DGS)近年来显著提升了三维场景的重建质量与渲染效率,也让可编辑三维内容生成变得更有应用前景。但在真正的场景编辑任务中,一个核心问题始终没有被很好解决:编辑结果能否既自然,又能在多视角下保持稳定。现有方法在单视角下往往已经能生成看起来不错的结果,可一旦切换视角,就容易出现新增物体位置漂移、结构关系错位、纹理闪烁,甚至几何崩塌。与此同时,很多方法更擅长颜色、风格、材质这类外观变化,却不擅长部件替换、姿态调整、局部变形这类真正需要结构控制的编辑任务。

论文标题:TRACE: High-Fidelity 3D Scene Editing via Tangible Reconstruction and Geometry-Aligned Contextual Video Masking
论文链接:https://arxiv.org/abs/2604.01207
代码:https://github.com/little612pea/Trace
为了解决这些问题,浙江大学与哈佛大学的研究者联合提出 TRACE。它的核心思路是,不再把 3D 编辑理解为“先在一张图上改好,再传播到其他视角”,而是把显式 3D 几何先验与视频扩散生成放进同一条编辑链路:一方面用几何约束锁定物体的位置、尺度与姿态,另一方面用视频生成补足纹理、光照与上下文融合,让结果在多视角和连续轨迹下都更稳定。

图1:TRACE 支持物体添加、局部形变、部件替换与风格迁移
等多种编辑任务,体现出更强的结构编辑能力。

图2:现有 3D 场景编辑方法常见问题包括跨视角不一致、几何错位,
以及编辑区域与原场景融合不自然。
这篇工作的判断很直接:现有 3DGS 编辑大致分成两类:(i)偏外观编辑,能做风格迁移和颜色替换,但难以真正改动物体形状;(ii)偏结构编辑,能够插入或调整几何体,却往往依赖人工对齐,而且视角一变就容易暴露几何错位和边界割裂。TRACE 认为,真正缺少的不是更强的单一模型,而是一套把图像生成与几何控制统一起来的协同机制。
围绕这个判断,TRACE 设计了三阶段流程。
(1) Multi-view 3D-Anchor Synthesis,先生成多视角一致的编辑锚点。研究团队不是直接把多张图一起交给现成图像编辑模型,而是先从参考视图得到可靠结果,再把它作为视觉锚点,配合视觉语言模型提供的空间关系提示,逐步指导后续视图生成。为了让模型真正学会“3D 一致”而不是“2D 位置复制”,研究团队还构建了 MV-TRACE 数据集,对 3D 资产做空间对齐、稠密视角采样,并通过 IoU 约束强化定位能力。
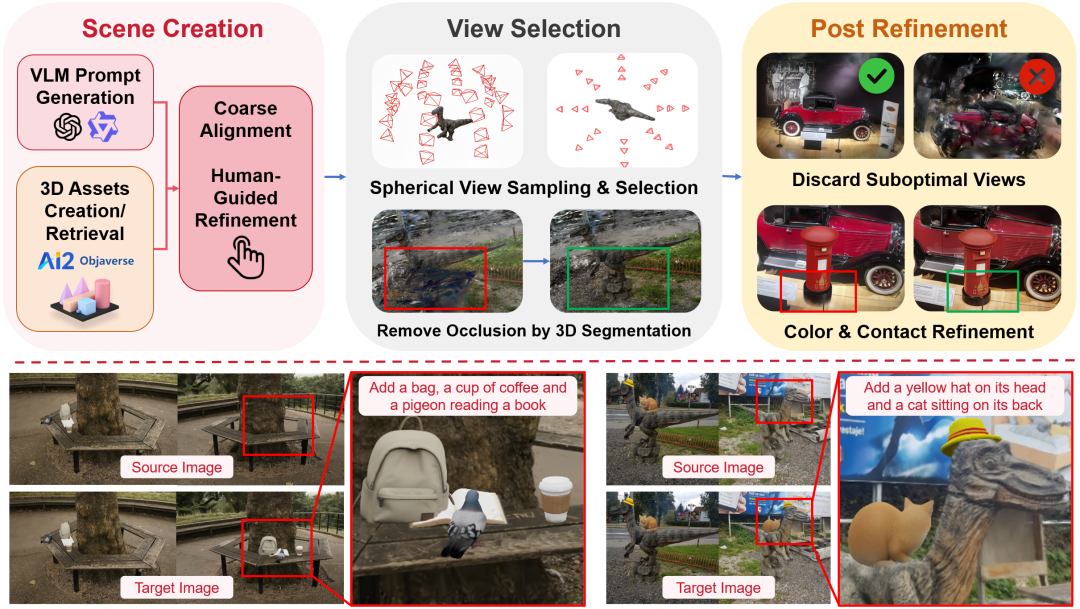
图3:MV-TRACE 数据集构造流程。研究团队先对 3D 资产
进行生成或检索与人工对齐,再做稠密多视角采样、过滤遮挡与无效视图,
最后进行颜色与接触关系修正,用于训练具备跨视角一致性的编辑模型。
(2)Tangible Geometry Alignment(TGA),负责把生成或编辑得到的 3D 几何资产真正放到原始场景里。难点在于,不同来源的 mesh 往往坐标系、朝向和尺度都不一致,直接插入通常只是“看起来放进去了”,其实并没有真正对齐。因此 TRACE 采用两阶段配准:先做全局姿态与尺度的粗对齐,再在稀疏视图几何约束下做细化优化,让物体位置、投影轮廓和场景结构逐步对上,并尽量避免穿插与漂移。
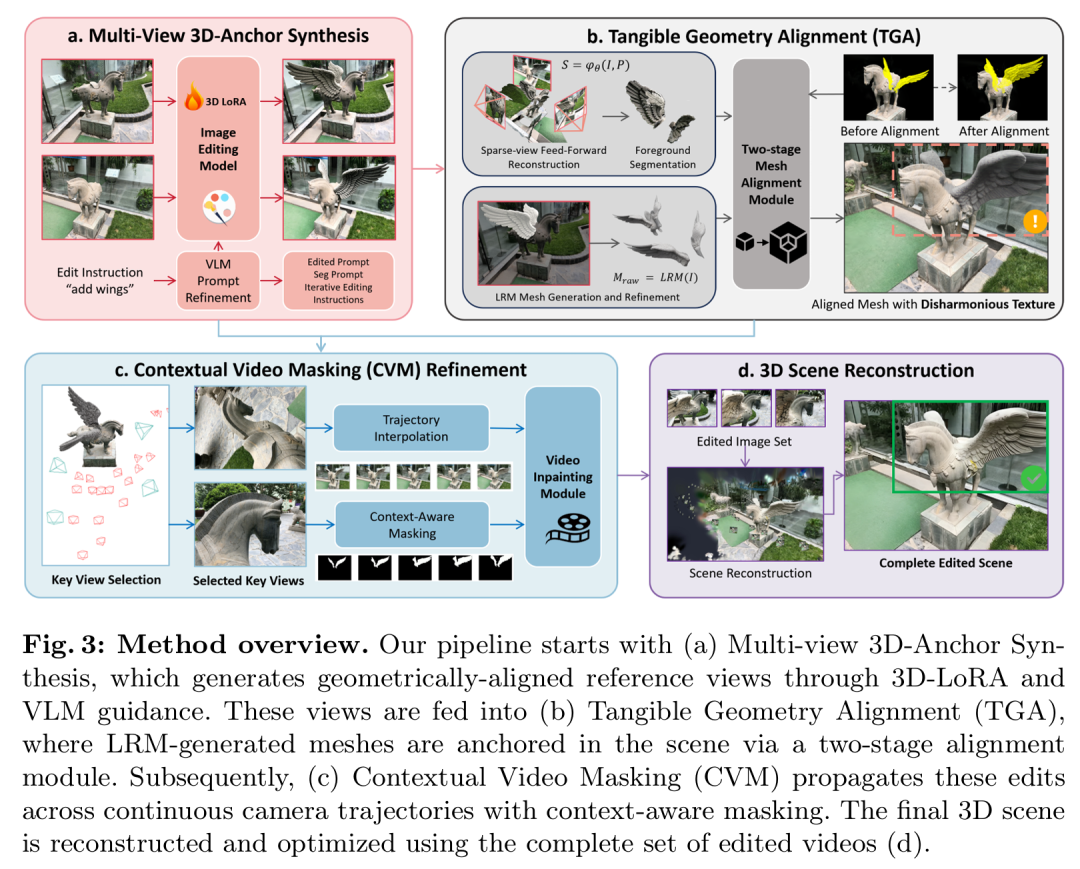
图4:TRACE 的核心流程包括多视角锚点合成、
TGA 两阶段几何对齐和 CVM 上下文视频重绘。
(3)Contextual Video Masking(CVM)。研究团队不是只重绘新增物体本身,而是把编辑区域连同阴影、反射和边界上下文一起交给视频扩散模型处理。这样做的结果是,模型不再只是把新物体“贴”到画面里,而是能够在连续视角轨迹中一起补全物体与环境之间的关系。配合自适应轨迹采样和分段式时序生成,TRACE 最终再把编辑后的视频序列回投到统一的 3DGS 表示中。整个方法真正解决的,是空间定位、几何对齐和视觉融合如何在同一条流水线上协同完成。
TRACE 的实验覆盖 8 个场景、48 个编辑案例,数据来自 IN2N、BlendedMVS 和 Mip-NeRF 360,任务既包括物体插入、结构变形,也包括风格迁移。对比方法既有 DGE、EditSplat、Vip3dedit 这类偏结构保持的方案,也有 TIP-Editor、GaussianEditor、GaussCtrl 等更复杂的编辑基线。
评价方面,研究团队主要考察四个维度:CLIP Directional Similarity 与 CLIP Similarity 衡量语义对齐,DINO Similarity 衡量多视角一致性,Aesthetic 分数衡量视觉质量,同时统计单场景运行时间。
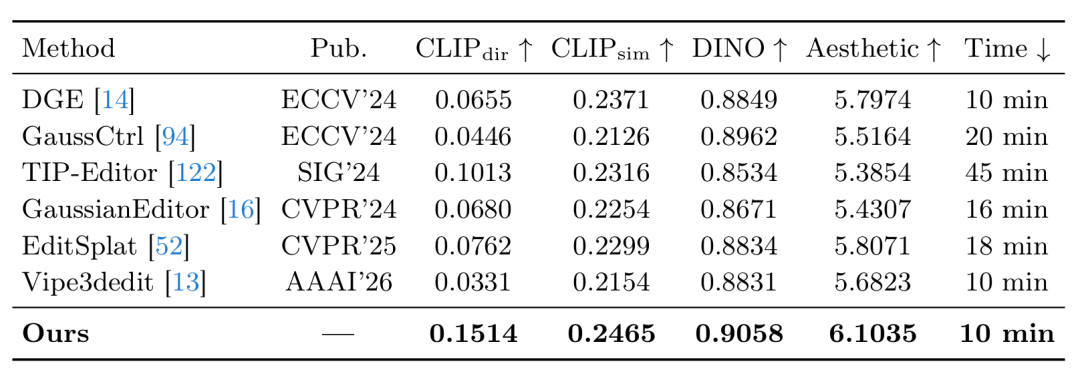
图5:定量结果显示,TRACE 在语义对齐、多视角一致性
和美学质量上整体优于现有基线。
从结果看,TRACE 的优势不是单点领先,而是几项关键能力一起提升。它在定量实验中把 CLIP_dir 做到 0.1514,明显高于次优方法的 0.1013,提升约 49.5%;CLIP_sim 达到 0.2465,DINO 达到 0.9058,Aesthetic 达到 6.1035,也都排在前列。更重要的是,这些提升并不是靠极端耗时换来的,TRACE 的完整编辑时间大约是 10 分钟每个场景,和高效基线处于同一量级,却显著好于不少需要更长优化过程的方法。

图6:定性对比中,TRACE 在物体插入、形态变化等
任务上能保持更稳定的结构和更清晰的细节。
定性结果同样说明问题。在形态变化任务里,很多基线只能做表面纹理替换,比如把“白虎”做成重新上色,而 TRACE 能把头部轮廓、尾部形态这类更深层的结构特征一起改出来;在物体插入任务里,常见失败模式是新物体在一个视角里合理,换个角度就漂移、模糊或者与背景脱节,而 TRACE 在多视角下能保持更稳定的空间关系。研究团队还专门对比了直接视频编辑方法,发现后者虽然能生成看上去合理的单段视频,但往往会引入背景过度重绘、主体形变和时序抖动,不利于回投成稳定的 3D 场景。
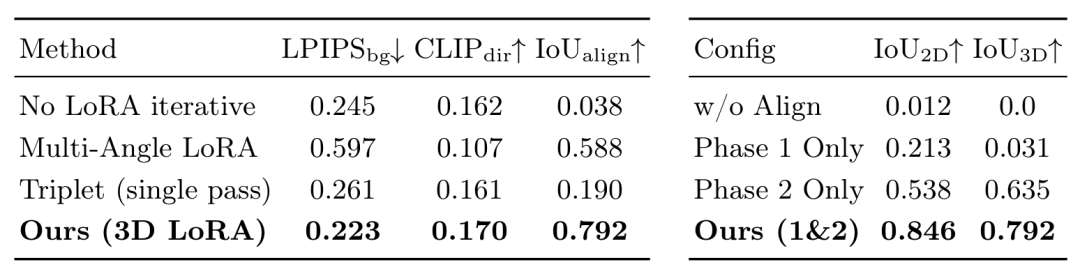
图7:消融实验表明,多视角锚点、两阶段配准
与上下文视频重绘分别对定位、对齐和视觉融合起关键作用。
消融实验进一步解释了这些提升来自哪里。多视角锚点合成模块让模型摆脱了“按 2D 位置复制目标”的倾向,在背景保持和空间 IoU 上都有明显提升;TGA 的两阶段配准证明了粗对齐和精对齐缺一不可;CVM 则主要改善边界过渡、光照一致性和长序列中的闪烁问题。换句话说,TRACE 的提升并非依赖某个单独模块,而是整条编辑链路共同作用的结果。
TRACE 的价值,在于它把 3DGS 场景编辑里最难同时满足的几件事连起来了:既要能做结构级修改,又要保持多视角几何一致;既要有明确的 3D 落点,又不能让结果看起来像“硬贴上去”;既要保留生成模型的灵活性,又不能丢掉三维场景本身的结构约束。研究团队给出的答案,是让显式几何先验负责“定位置、定关系”,让视频扩散负责“补纹理、补光照、补上下文”,再通过统一流程把两者收束到同一个可优化的 3D 表示上。
TRACE 不只是提出了一个更强的 3DGS 编辑方法,也提供了一条更清晰的方向:未来高质量三维编辑系统,未必是纯生成模型一路到底,也未必是几何方法单独主导,而更可能是显式 3D 约束与生成式建模深度协同的结果。










