绑定手机号
确认绑定









智猩猩AI整理
编辑:发发
大语言模型(LLM)智能体在长周期推理任务中面临根本性限制,这主要源于有限的上下文窗口,使得有效的记忆管理变得至关重要。现有方法通常将长期记忆(LTM)和短期记忆(STM)作为独立组件处理,依赖于启发式规则或辅助控制器,这严重限制了自适应性和端到端优化能力。
现有架构的局限性主要体现在将LTM和STM视为分离且松散耦合的模块。传统架构通常遵循两种模式:具有基于触发器的LTM的静态STM,或具有基于智能体的LTM的静态STM。在这两种设置中,两个记忆系统被独立优化,然后以临时方式组合,导致记忆构建碎片化和性能次优。
同时,实现统一记忆管理面临三大基本挑战:
(1)功能异构性协调:LTM和STM服务于不同但互补的目的;
(2)训练范式不匹配:现有强化学习(RL)框架对两种记忆类型采用显著不同的训练策略;
(3)实际部署约束:许多智能体系统依赖辅助专家LLM进行记忆控制,显著增加推理成本和训练复杂性。
为此,阿里巴巴集团与武汉大学联合提出了Agentic Memory(AgeMem),这是一个统一框架,将LTM和STM联合管理。与先前将记忆视为外部组件的设计不同,AgeMem通过基于工具的统一接口将两种记忆类型直接集成到智能体的决策过程。研究团队还开发了一种配备逐步式GRPO机制(step-wise GRPO)的三阶段渐进式强化学习策略,有效促进端到端的统一记忆管理行为学习。在多个模型与长期任务基准上进行了全面评估,验证了AgeMem在复杂智能体任务中的稳健性与有效性。

论文标题:Agentic Memory: Learning Uniffed Long-Term and Short-Term MemoryManagement for Large Language Model Agents
论文链接:https://arxiv.org/pdf/2601.01885
01 方法
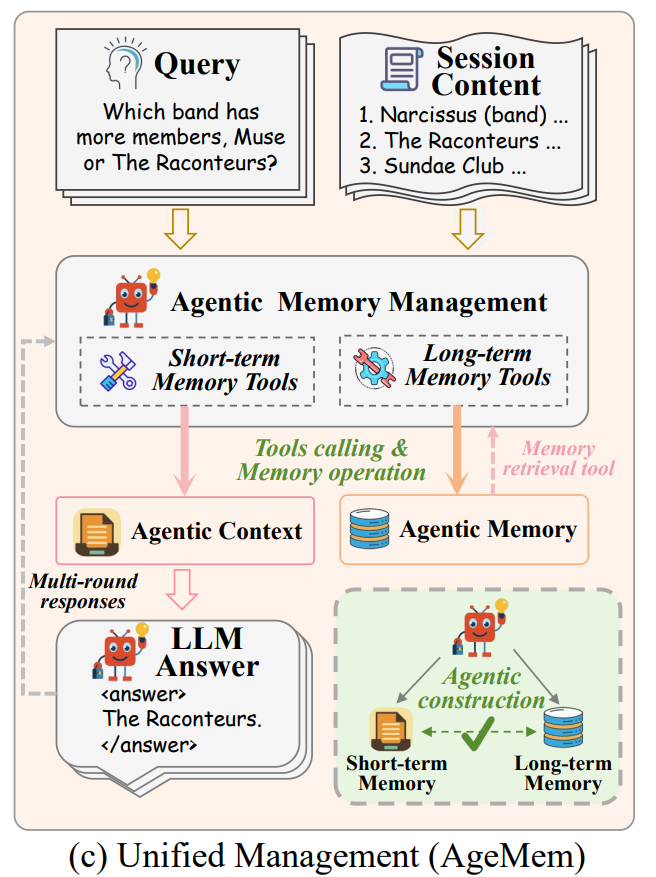
图1:AgeMem框架
(1)统一记忆管理工具接口
如图2所示,AgeMem通过工具接口将记忆操作暴露给LLM智能体。智能体可使用ADD、UPDATE、DELETE修改持久性LTM,并通过RETRIEVE、SUMMARY、FILTER对STM进行细粒度控制。

图2:AgeMem中用于操作长期记忆(LTM)和短期记忆(STM)的记忆管理工具
(2)三阶段渐进式RL策略
为学习统一且稳定的记忆行为,研究团队设计了渐进式三阶段训练策略。每个任务实例生成完整轨迹:
阶段1(LTM构建):智能体在随意对话环境中接触上下文信息,识别关键信息并存储至LTM。
阶段2(含干扰的STM控制):短期上下文重置,LTM保留。智能体学习通过工具操作抑制噪声、保留有用信息。
阶段3(集成推理与记忆协调):智能体接收正式查询,需从LTM检索知识、管理上下文并生成最终答案。
(3)逐步式GRPO优化机制
采用逐步式GRPO变体连接长周期任务奖励与跨阶段记忆决策。对每组并行轨迹计算终端奖励,归一化优势后广播至同轨迹所有时间步,使最终任务结果监督每个中间记忆决策,实现跨异构阶段的长范围信用分配。
优化目标函数:
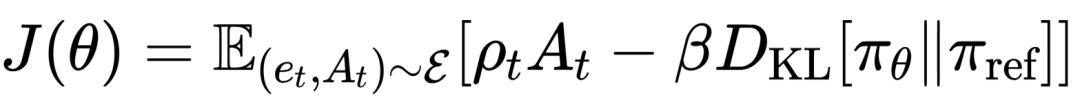
其中,ρt为新旧策略概率比,DKL为KL散度惩罚项。
(4)复合奖励函数设计
总轨迹级奖励包含任务完成奖励Rtask、上下文管理奖励Rcontext和记忆管理奖励Rmemory,辅以违规惩罚项Ppenalty:
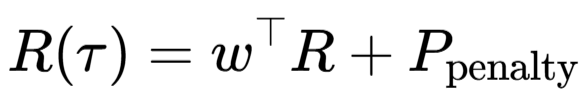
其中,权重w=[wtask,wcontext,wmemory]⊤,各组件归一化至[0,1]区间。
02 评估
(1)多基准性能对比
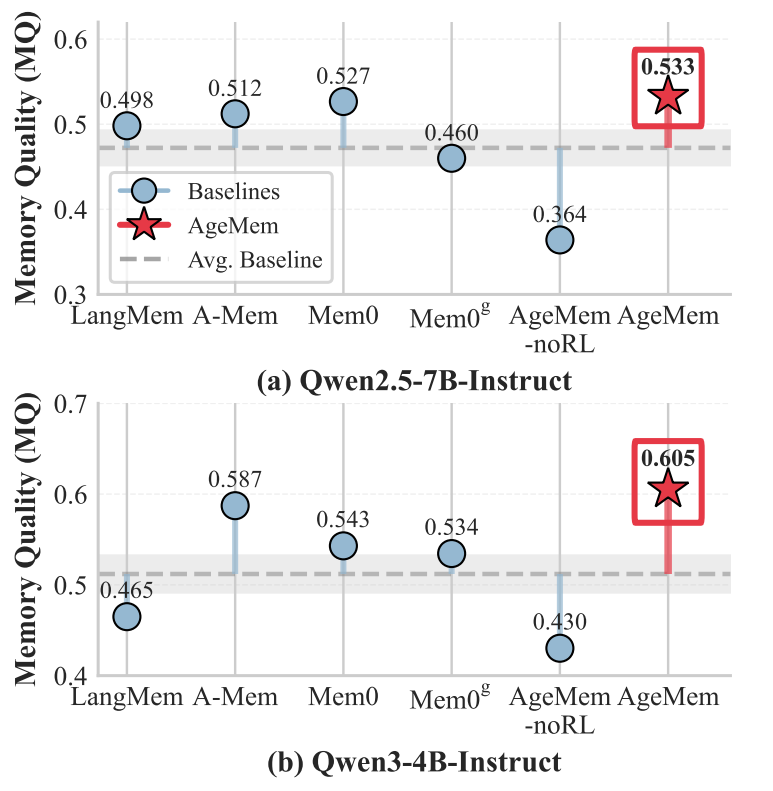
图3:五个基准测试上的性能对比(最佳与次佳结果已标注)
在ALFWorld、SciWorld、PDDL、BabyAI和HotpotQA五个基准上,AgeMem在Qwen2.5-7B和Qwen3-4B模型上均取得最高平均性能41.96%和54.31%,相对无记忆基线分别提升49.59%和23.52%。相比最佳基线Mem0和A-Mem,AgeMem平均提升4.82和8.57个百分点。RL训练带来8.53和8.72个百分点的提升。
(2)记忆质量评估
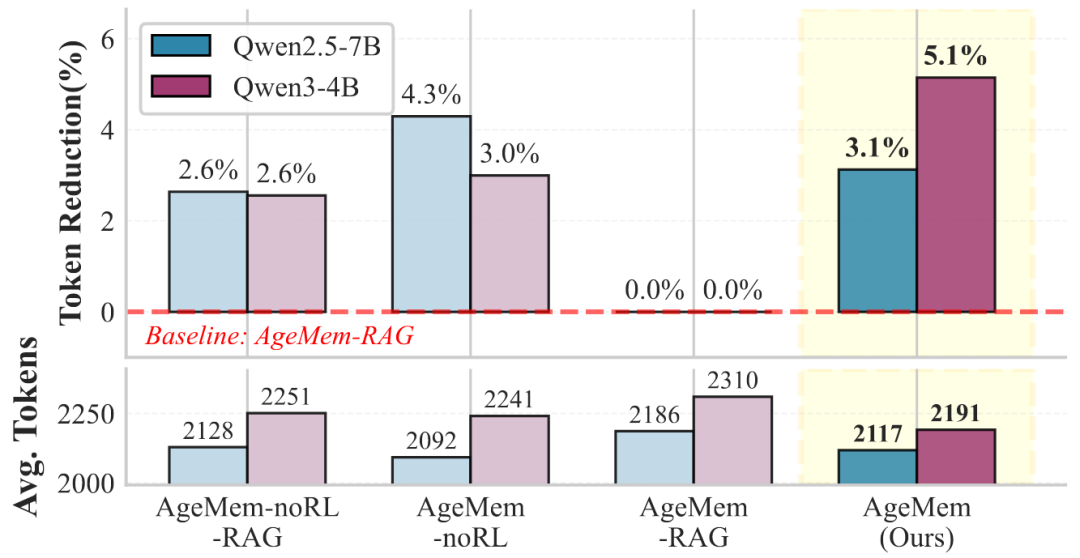
图4:HotpotQA上不同方法的记忆质量(MQ)分数
AgeMem在两个模型骨干上均取得最高记忆质量(MQ分数0.533和0.605),表明统一记忆管理框架不仅提升任务性能,还促进存储高质量、可复用知识。
(3)STM管理有效性
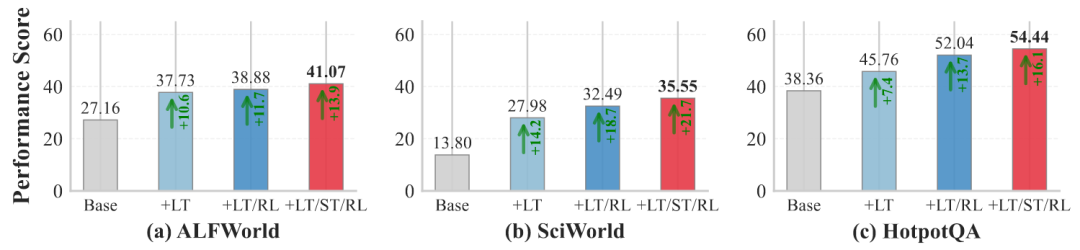
图5:HotpotQA上不同STM配置的平均提示token数
AgeMem成功减少提示token使用量:在Qwen2.5-7B上平均使用2117 token,较无STM工具版本(2186 token)减少3.1%;在Qwen3-4B上从2310 token降至2191 token,降幅5.1%。
(4)工具使用分析
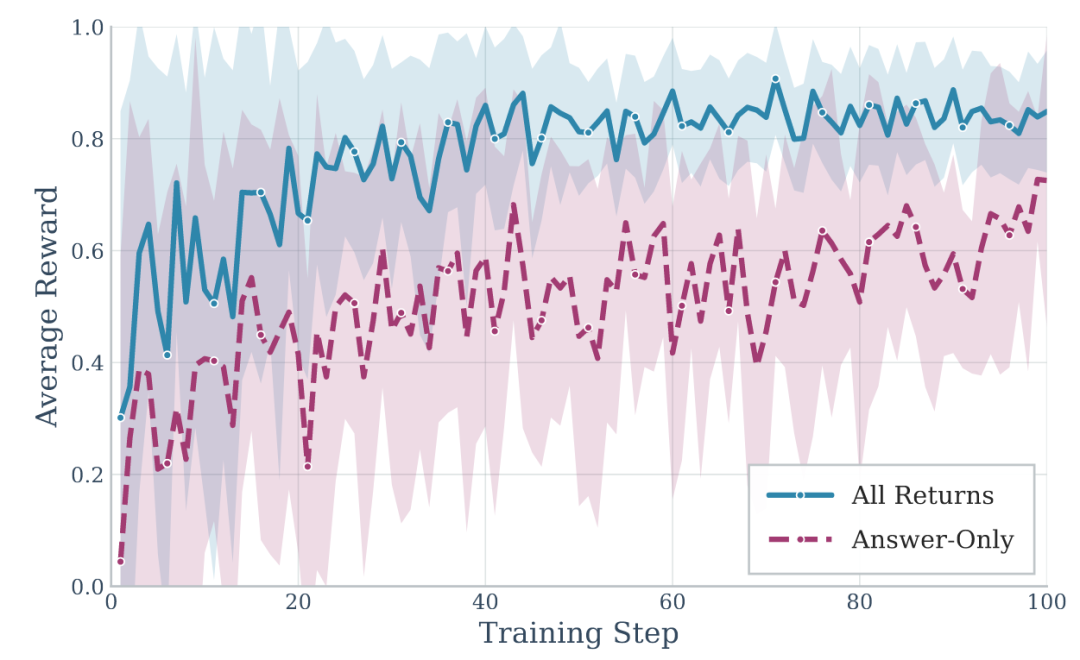
图6:HotpotQA上工具使用统计(数字为每回合平均调用次数)
RL训练显著增加长期记忆工具使用:ADD操作在Qwen2.5-7B上从0.92次增至1.64次,UPDATE操作从近乎零增至0.13次。短期记忆工具使用更均衡,FILTER调用从0.02次显著增至0.31次。
(5)消融研究
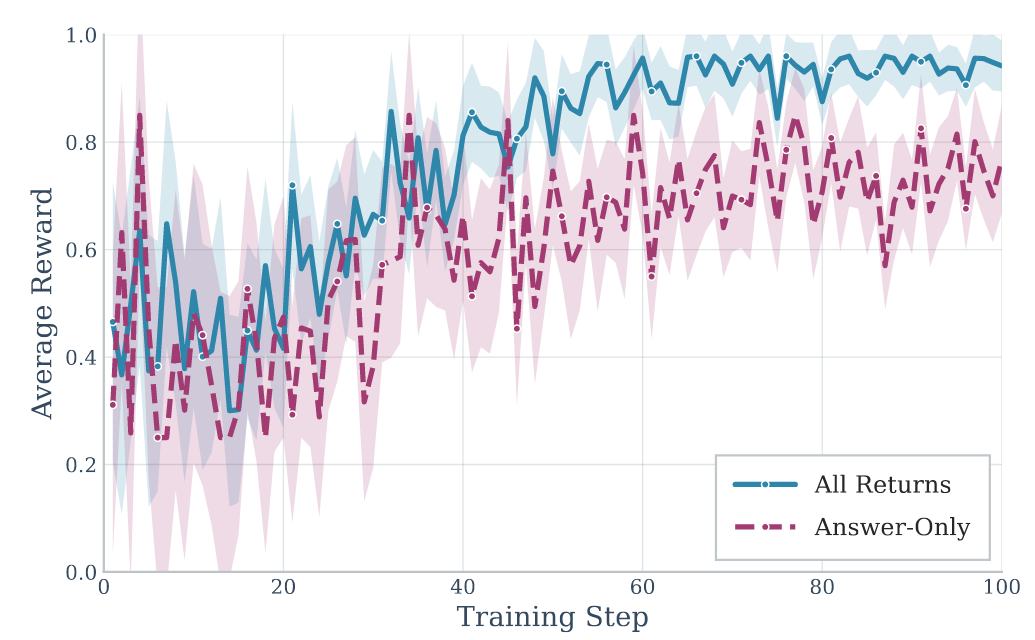
图7:LTM、STM和RL组件的消融研究(Qwen2.5-7B)
添加LTM(+LT)较基线带来10.6%–14.2%增益;加入RL训练(+LT/RL)在HotpotQA上进一步提升6.3%;完整AgeMem系统(+LT/ST/RL)在所有基准上取得最佳结果,整体提升13.9%–21.7%。
(6)奖励函数设计验证
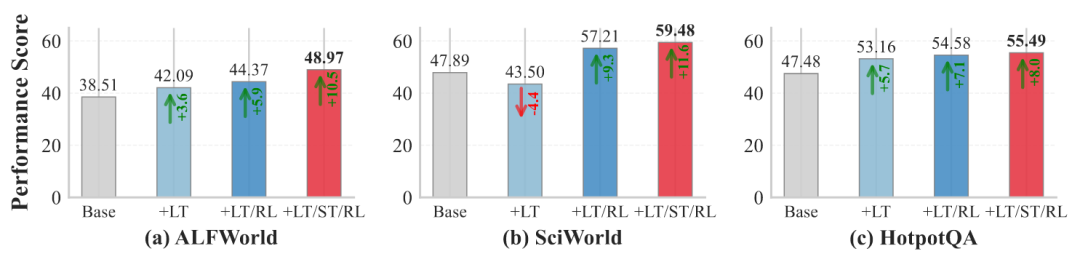
图8:LTM、STM和RL组件的消融研究(Qwen2.5-7B)
研究团队的全奖励策略(All-Returns)比仅任务奖励(Answer-Only)收敛更快、最终性能更高,在保持更高LLM评判分数(0.544 vs 0.509)的同时,记忆质量显著提升(0.533 vs 0.479)。










