绑定手机号
确认绑定









小红书投稿
智猩猩AI整理
基于可验证奖励的强化学习(RLVR)一直是大语言模型后训练的核心技术,GRPO 便是其中的代表性算法。然而,小红书研究团队在从底层优化目标重新审视 GRPO 及其变体时,发现这类算法存在正样本的 梯度错配(Gradient Misassignment)以及负样本的 梯度主导(Gradient Domination)问题,导致策略优化并不高效。
为了从根本上破局,小红书团队提出了一种全新框架——REAL(Rewards as Labels)。该方法跳出了传统 RLVR 将奖励用于计算优势(Advantage)的固有思维,而是直接将奖励视为“分类标签”。这一框架不仅在梯度分配上完美解决梯度错配与梯度主导两大问题,更在 1.5B 和 7B 尺寸的模型上大幅超越了 GRPO 及其强势变体 DAPO 和 GSPO。值得一提的是,即便退化使用最简单的二元交叉熵(BCE)损失,REAL 依然能保持卓越的训练稳定性,并超越 DAPO。
论文标题:Rewards as Labels: Revisiting RLVR from a Classification Perspective
论文地址:https://www.arxiv.org/abs/2602.05630
开源代码:https://github.com/DeepExperience/REAL
01 方法
为理解 GRPO 在训练中可能遇到的问题,研究团队从梯度视角审视 GRPO,其代理函数梯度更新的计算公式为:
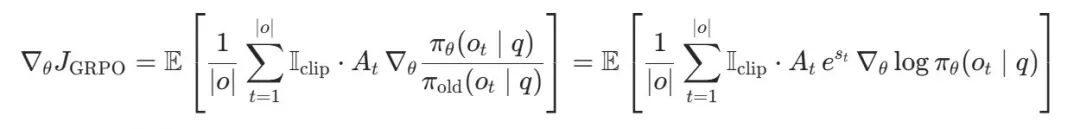
这里 表示 token 级别的相对对数概率, 为优势函数, 是裁剪指示函数,代表是否在未被裁剪的区间内。
故对于每个 token,其梯度更新权重可以表示为(为简洁省略 token 序号 t ):
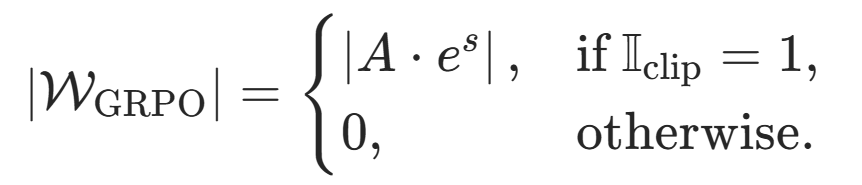
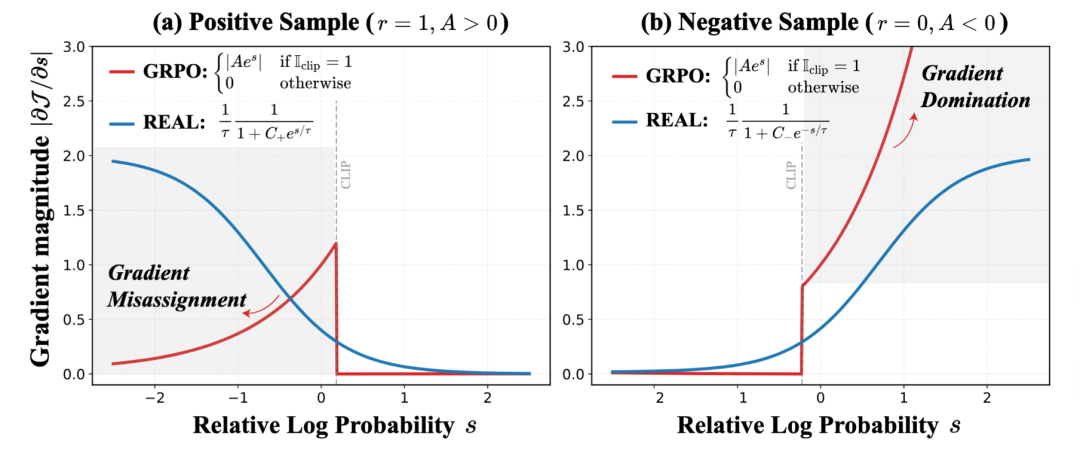
通过可视化分析梯度权重 关于相对对数概率 s 的变化曲线(如图中红线),研究团队发现了两个关键缺陷:
问题一:梯度错配(Gradient Misassignment)
针对正样本,当 token 的相对置信度 s 降低时,其获得的梯度更新权重反而减小。这与优化直觉相悖——那些模型尚未充分学习、置信度相对较低的正确 token(hard token),本应获得更强的梯度信号来强化学习,但 GRPO 却让已经“过度自信”的 token 获得更多更新权重,导致梯度错配。
问题二:梯度主导(Gradient Domination)
针对负样本,随着错误 token 的置信度 s 增大,其梯度权重呈现指数级爆炸式增长且缺乏上界约束。这会导致少数高置信度的错误 token (hard token)产生极大的梯度值,压制了其他负样本 token 的梯度信号,使优化过程产生较大波动和不稳定性。
针对上述问题,团队提出了 REAL(图中蓝线)改进方案,该框架的核心解法非常直接:既然 RLVR 场景下的奖励是确定的可验证信号,何不直接将其作为分类标签,将复杂的策略更新转化为组内分类问题?并且该框架实现了更合理的梯度分配机制。
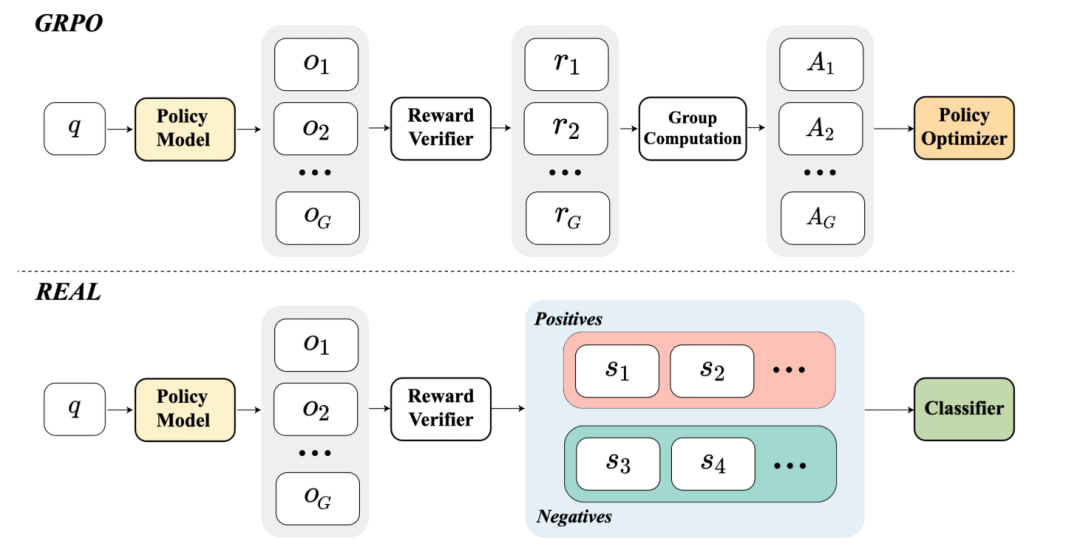
(1) 分类 logits 的设计:使用长度归一化相对对数概率
REAL 让模型对同一指令生成一组候选回复,并根据奖励划分为正样本集 和负样本集 。对于生成的每个样本 (k 为 rollout 中第 k 个样本),REAL 计算其在当前策略与旧策略下的长度归一化相对对数概率作为该样本的 logits 分值:
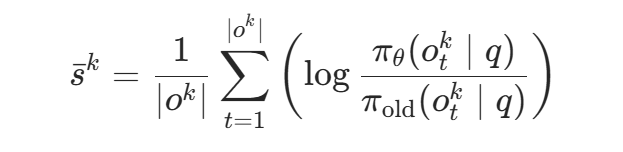
这个分值的设计非常直观: 代表模型倾向于增强该样本, 代表抑制该样本。天然以 0 作为正负样本的分界线。
(2)损失函数的设计:引入 Anchor Logits 的统一交叉熵
为了拉开正负样本的得分差距,REAL 创新性地引入了一种更为优雅的 Unified Softmax Loss,并加入了固定锚点 。通过将正样本分值约束在 0 以上,负样本分值约束在 0 以下,并引入温度系数 ,REAL 最终的总损失函数定义为正负样本损失之和:
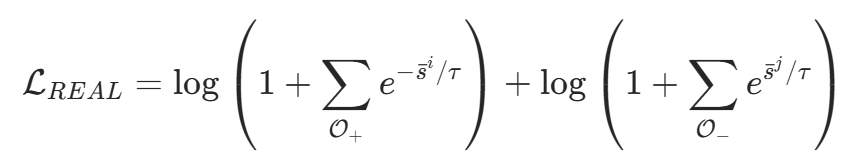
(3)梯度特性:完美解决梯度偏差
在这种分类损失的约束下,REAL 计算出的梯度权重公式为:
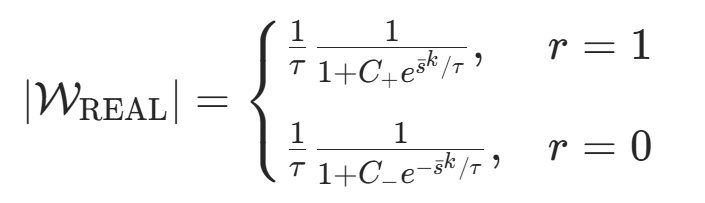
其中 、 为常数项,这一梯度公式彻底解决了 GRPO 的弊端:
针对正样本:当 变小,即模型对正样本更“不自信”时,梯度权重显著增加,强迫模型加大力度学习正确的长尾 token,纠正了“梯度错配”问题。
针对负样本:当 变大,即模型对负样本“过于自信”时,由于 Softmax 的饱和特性,梯度被严格限制在上界以内,避免了“梯度主导”引发的更新失控。
02 评估
为全面验证 REAL 框架的有效性,研究团队使用 DeepSeek-R1-Distill-Qwen-1.5B 和 7B 作为基础模型,在多个数学推理基准上进行了系统性实验。实验对比了GRPO、DAPO、TRPA 和 GSPO 四种主流 RLVR 方法。主实验采用 DeepScaleR-Preview-Dataset(约40.3K样本)进行训练。评测覆盖 AIME 2024/2025、MATH 500、AMC 2023、Minerva 和 Olympiad Bench六大数学推理基准,报告 Pass@1 指标(每题采样16次取平均准确率)。实验中 REAL 的温度参数设为 ,且 REAL、DAPO 和 GSPO 均未使用 KL 散度惩罚项。
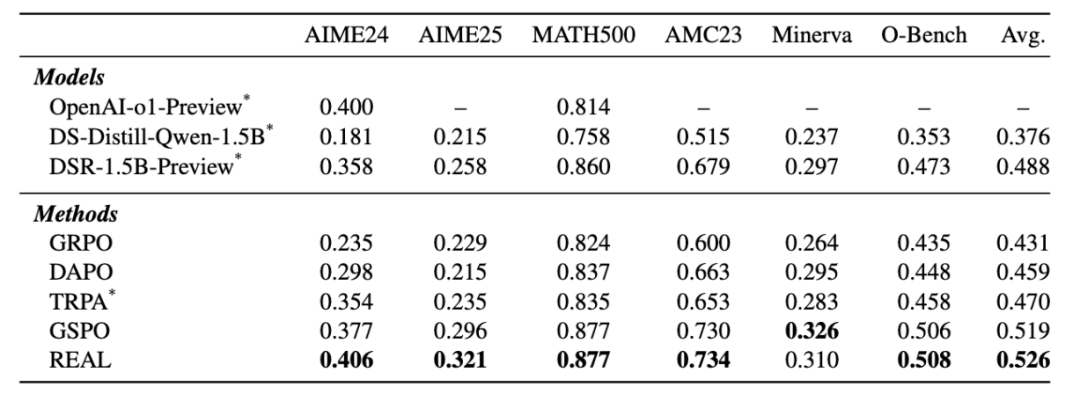
1.5B 模型尺寸结果:
7B 模型尺寸结果:
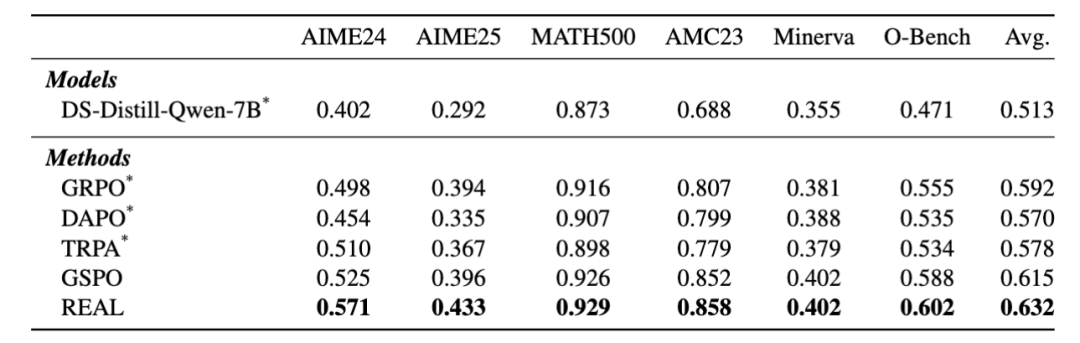
(1)在 1.5B 和 7B 模型上全面领先
在 1.5B 规模下,REAL 的平均 Pass@1 达到了 52.6%,相较于 GRPO 和 DAPO 分别实现了 9.5% 和 6.7% 的大幅提升。在具有挑战性的 AIME 2024 和 AIME 2025 竞赛题中,REAL 分别斩获 40.6% 和 32.1% 的成绩,超过强基线方法 GSPO。这证明 REAL 经过修正“hard token”的梯度分配后收益巨大。在 7B 模型上,REAL 同样取得了 63.2% 的平均准确率,分别超越 DAPO 和 GSPO 6.2% 与 1.7%,证明了该框架良好的规模可扩展性。
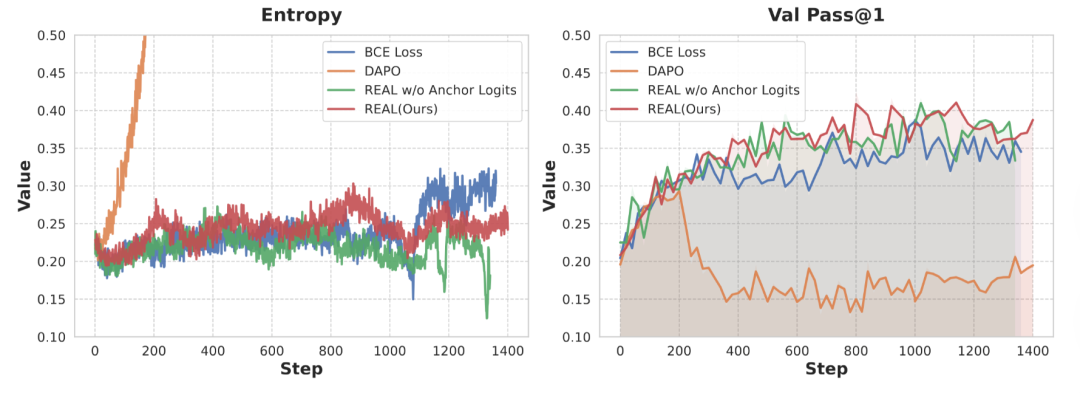
(2)训练稳定:探索与利用之间的良好平衡

先前的 RLVR 方法在训练时容易出现“熵坍塌”(过早丧失探索能力)或“熵爆炸”(策略更新失控),导致验证集的性能停滞。相比之下,REAL 在整个训练周期内始终维持着平稳健康的熵轨迹,实现了探索与利用的完美平衡,其完全正确解决的样本比例也呈现了更好的增长曲线。
(3)消融分析:分别拆解 REAL 的设计
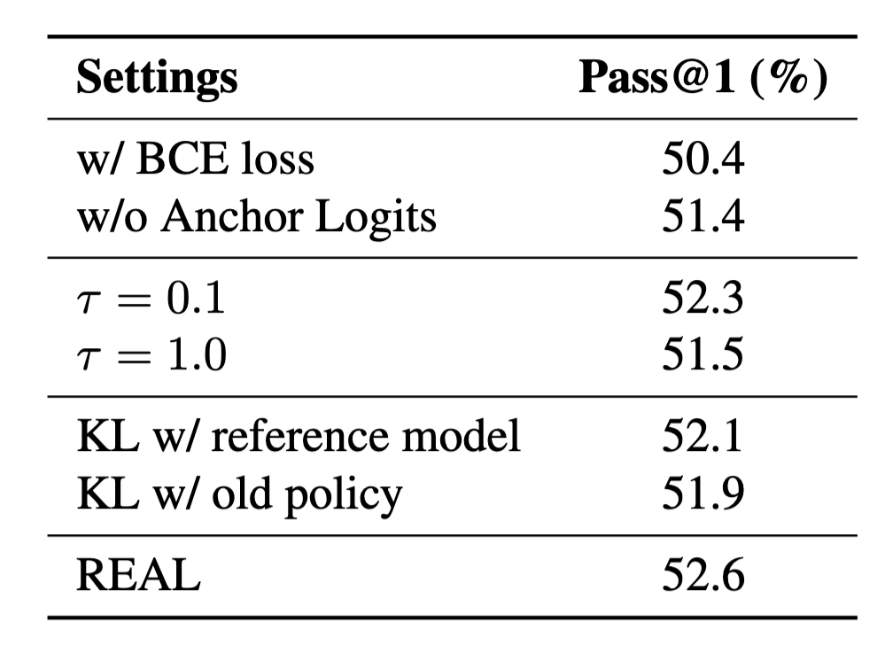
损失函数选择:REAL 所使用的 Softmax Loss 能天然引入组内样本的竞争机制,性能比 BCE 高出 2.2%;即便退化为 BCE,REAL 框架依然保持训练稳定且比DAPO 高出 4.5%。
Anchor Logits:移除 Anchor Logits 后性能有所下降(-1.2%),这表明引入固定零点作为 Anchor 提供了绝对优化基准,在消除优化方向歧义的同时加速了模型收敛。
温度参数:该参数用于控制梯度上界,测试了 三组设置均取得不错的效果,其中 取得了最佳性能(52.6%)成为所采用的配置。
KL 散度:对比不加 KL 惩罚、加入相对参考模型的 KL、加入相对旧策略的 KL 三组实验表明效果差异不大,最大(52.6%)与最小(51.9%)的差异只有 0.7%,证明 REAL 框架天然的有界梯度权重已起到自适应梯度裁剪的作用,无需额外的 KL 惩罚来约束。
03 展望
REAL 框架表明在具备可验证奖励的场景下,只要确保梯度方向与权重合理,策略优化未必需要复杂的优势估计和其他 RL 组件,一个简单的分类器同样能取得很好的效果。未来,研究团队计划进一步拓展 REAL 框架的边界,探索其在多元离散奖励以及连续奖励条件下的分类建模潜力,将这一思想扩展到任意形式的奖励情形。










