绑定手机号
确认绑定









智猩猩AI整理
格灵深瞳投稿
大型多模态模型(LMMs)在预训练阶段常面临模态表征差距问题:语言嵌入通常保持稳定,而视觉表征对上下文噪声(例如背景杂乱)高度敏感。
为解决这一问题,格灵深瞳联合中国科学技术大学、华为、伦敦帝国理工学院引入了一个视觉理解阶段ViCToR(基于token重建视觉理解),这是一种面向 LMM 的新型预训练框架。ViCToR 采用一个可学习的视觉 token 池,并利用匈牙利匹配算法从该池中选择语义相关的 token,用于替换原始视觉 token。此外,通过将视觉 token 重建损失与密集语义监督相结合,ViCToR 能够学习到保留丰富视觉细节的 token,从而增强大语言模型(LLM)对视觉信息的理解能力。在使用 300 万张公开可用的图像-文本对进行预训练后,ViCToR 取得了SOTA性能,在 MMStar、SEED-I 和 RealWorldQA 基准上分别比 LLaVA-NeXT-8B 提升了 10.4%、3.2% 和 7.2%。该成果已被AAAI 2026收录。

论文名称:ViCToR: Improving Visual Comprehension via Token Reconstruction for Pretraining LMMs
code:https://github.com/deepglint/Victor
paper:https://arxiv.org/abs/2410.14332
01 过去的多模态预训练方法
如何让LLM更好的理解视觉特征,这是多模态大模型在设计之初就需要思考的问题。OpenAI在CLIP中首次提出了通过对比学习方法,直接让视觉编码器对视觉的理解对齐人类语义。在有了对齐人类语义的视觉编码器之后,BLIP和LLaVA等工作开始尝试将视觉编码器与大语言模型连接到一起,试图让LLM长出眼睛看懂世界!
BLIP和LLaVA自设计之初开始,就在思考如何将视觉特征映射到文本空间中去,让LLM更好的理解视觉。LLaVA通过两层线性层的简单模块设计取得了卓越的效果,对后面许多的工作产生了深远的影响。人们发现,只要简单的维度映射模块和短caption的数据,就能让LLM对视觉内容有着初步的认知。加之以精心挑选的VQA数据进行微调,就能得到看懂世界的多模态大模型。随着研究的不断丰富,人们进一步发现,似乎可以制作大量的caption数据,从而保证LLM更加全面的理解视觉,并持续带来了能力的提升。
随着行业的不断发展,人们对于多模态大模型的普遍预训练的认知就是:简单的模块将视觉特征映射到语言特征空间中,辅以尽可能多的caption数据来提升视觉认知能力。
02 视觉和语言之间存在怎样的Gap?
但是让我们回归本质,视觉和语言,从本质的信息组成上他们究竟有怎样的Gap?
首先语言作为由人类创造的,用于对世界知识进行凝练抽象化和个人思想表达的信息媒介,其被在任意地方记录时,总会带着一定的前后因果与丰富的有效信息。学术界与工业界可以尽可能收集这些语言数据,并在海量的数据上进行大规模的自回归训练,得到现如今能力强悍的大语言模型。因此,语言的信息往往具有两个非常显著的特点,有限离散与因果。
相对而言,自数字媒体技术发明以来,图片这种信息媒介开始大量出现。相比于人们在进行书写时候的慎重表达,人们对于按下快门这件事似乎并没有那么慎重。大量的随意拍摄的图片在人类社会传播,物体与物体之间几乎可以有数不清的任意组合形式出现在图像中。因此图片中的不同元素的组合往往是空间拼接的,而非前后因果的。除此之外,相对于语言对物体的抽象表达,同一类事物在图片中的表现又有无数种。因此图片的特征空间其实是连续且无限的。
因此从本质上来说,视觉语言之间始终有两条巨大的鸿沟——无限与有限、前后因果与空间拼接。
03 ViCToR:让LLM更懂视觉的多模态预训练方法
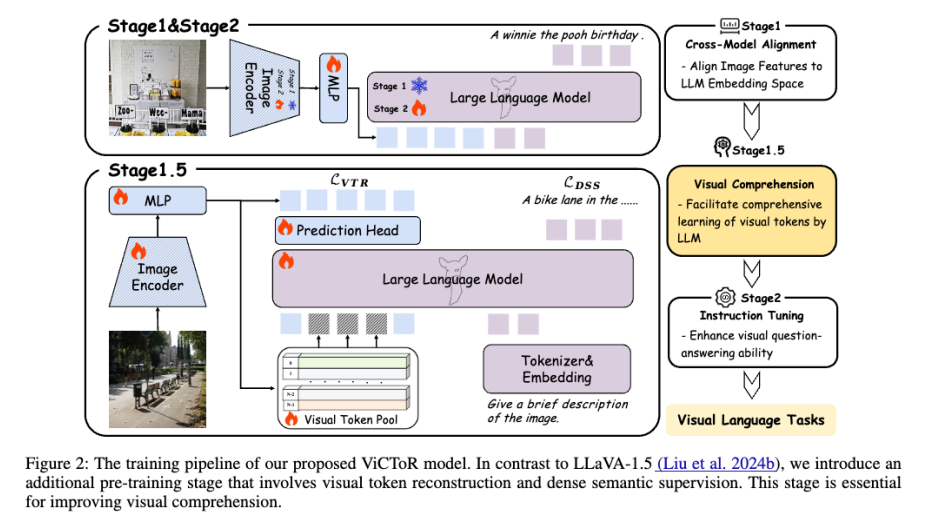
为了弥补视觉与语言之间的模态鸿沟,ViCToR通过视觉特征重建与VTP模块来让LLM更好的理解视觉特征。
首先,为了让LLM理解视觉信息的组织形式是空间上的拼接,而非前后因果关系,ViCToR通过随机mask的方式,保证LLM只能看到空间上离散的视觉特征。再利用特征级别的重建,促使LLM通过上下左右的可见的视觉特征“想象”中间的视觉特征的形式。
其次,由于视觉特征空间是无限的,为了让LLM主动总结视觉特征的类别。ViCToR提出了一种VTP组件,随机初始化N个可学习的视觉特征,并在将视觉特征喂给LLM之前,对部分的视觉特征从N个可学习的视觉特征中选择最相近的部分特征进行替换。利用此方式,LLM会不断优化VTP组件中的N个视觉特征,形成对视觉特征的总结与抽象。
除此之外,ViCToR还提出,此方式只需要作用于stage 1.5,可以促使图片的caption和视觉重建任务相辅相成,以较低的成本实现更佳的预训练效果。
04 实验
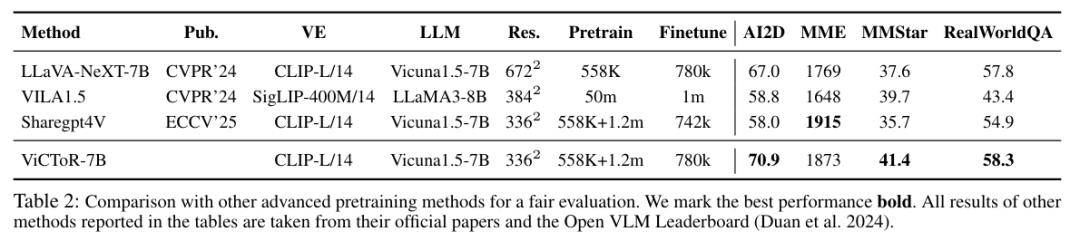
ViCToR-7B基于SigLip2和Qwen2.5-7B的预训练模型,在3m预训练数据和780k结构化微调数据上训练出超越了近似量级的多个SOTA模型。
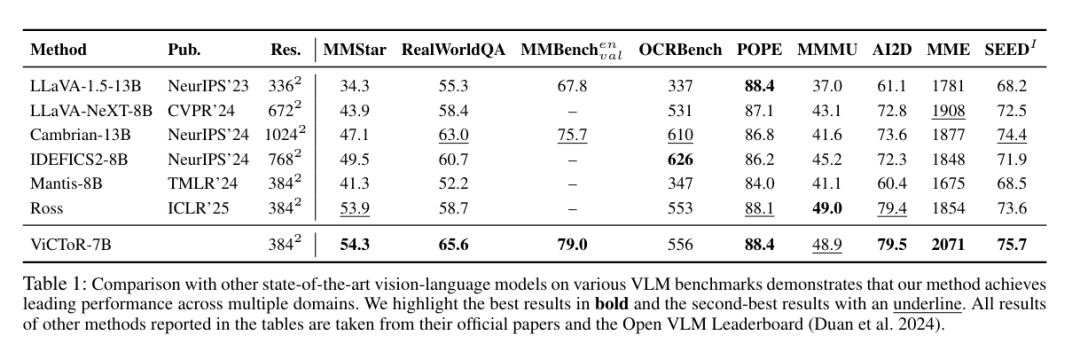
并且为了在相对公平的情况下体现ViCToR与其他预训练方法的高效性,研究团队还控制了视觉基座、预训练数据等多个setting相同或劣势于其他的方法进行了比较实验。
通过对不同图片中的视觉特征与VTP中的N个训练后的特征进行聚类,研究团队可视化了VTP对视觉内容强大的抽象能力。

05 总结
在当前业界普遍采用堆数据暴力升级的方式下,ViCToR从模态信息组织差异的本质入手,似乎能更好的解释为什么当前的多模态发展瓶颈。这启发了后面的相关工作应当更加关注信息本质,让模型的训练能够符合原本的信息特点。这或许也是为什么主流LLM总是自回归的因果mask attention,而ViT总是双向可见的attention的原因。










