绑定手机号
确认绑定









智猩猩AI整理
编辑:汐汐
在AI智能体领域中,如果使用过Agent Skills,那么肯定会了解skill-creator,这个由Anthropic于2025年发布的一个skills零代码构建工具。
但是构建好skill后,仍然无从知晓这个skill是否有用、新模型还能用吗、运行准确吗、效果怎么样...
就在3月3日,Anthropic官方博客悄然发布了一篇重磅更新,叫做Improving skill-creator: Test, measure, and refine Agent Skills。这一升级让 Claude 的“技能工厂”真正走向成熟。
从“看起来能用”到“可测试、可衡量、可迭代”,彻底解决了此前技能作者最大的痛点,也就是“我做的技能到底好不好用?”

01 Agent Skills回顾:从通用助手到专业智能体的关键一步
2025年10月 Anthropic 正式推出 Agent Skills,这是一种模块化、可复用的“技能包”系统。一个文件夹里包含 SKILL.md 指令、脚本、资源,Claude在需要时自动加载,大幅提升文档生成、数据分析、品牌合规等场景表现。
Skills 已覆盖Claude.ai、Claude Code、API全平台,并开放GitHub仓库(目前星标超 8 万)。但早期版本的最大局限是,非技术用户只能凭感觉迭代,无法量化验证效果。
这次 skill-creator 升级,正是 Anthropic 把软件工程的严谨性带进了 AI 技能创作。
Skills有两种类型,分别是:
1. 能力提升型
模型原本“做不到”或“做不稳定”的事,通过 Skills 注入特定技巧、模式来稳定输出。典型例子是文档创建 Skills(如 PDF 处理)。
测试重点:监控模型通用能力是否已追上或超越 Skills,一旦基线模型无需 Skills 即可通过 evals,该 Skills 即可“退休”。
2. 偏好编码型
模型每一步都能做,但需要按团队特定流程严格排序。例子:按固定标准审查 NDA、按公司模板生成周报。
测试重点:验证 Skills 是否忠实还原真实工作流,而非模型的“自由发挥”。
而此次升级的5大亮点如下:
1、Evals(自动化评估):用户只需描述“测试提示词 + 期望输出样子”skill-creator 自动运行验证。
2、Benchmark 模式:批量跑标准化测试,输出通过率、耗时、Token 消耗等硬指标。
3、多代理并行执行:独立干净上下文,避免污染,测试速度暴增。
4、Comparator(盲测对比):A/B 测试两个技能版本或“有技能 vs 无技能”,由第三方代理客观打分。
5、Description Tuning(触发描述优化):自动分析样本提示,建议修改描述,减少误触发/漏触发。官方自测:6 个公开文档技能中 5 个触发准确率显著提升。

02 没有理由不安装!这次更新让旧技能起死回生
Anthropic对skill-creator的这次更新,迅速引发AI Agent从业者和开发者热议。核心焦点集中在“零代码引入软件级测试与迭代能力”上,这被视为Agent Skills从“实验玩具”走向“生产级基础设施”的关键一步。
Anthropic员工Lance Martin发布帖子,用一条视频演示了更新后的skill-creator。
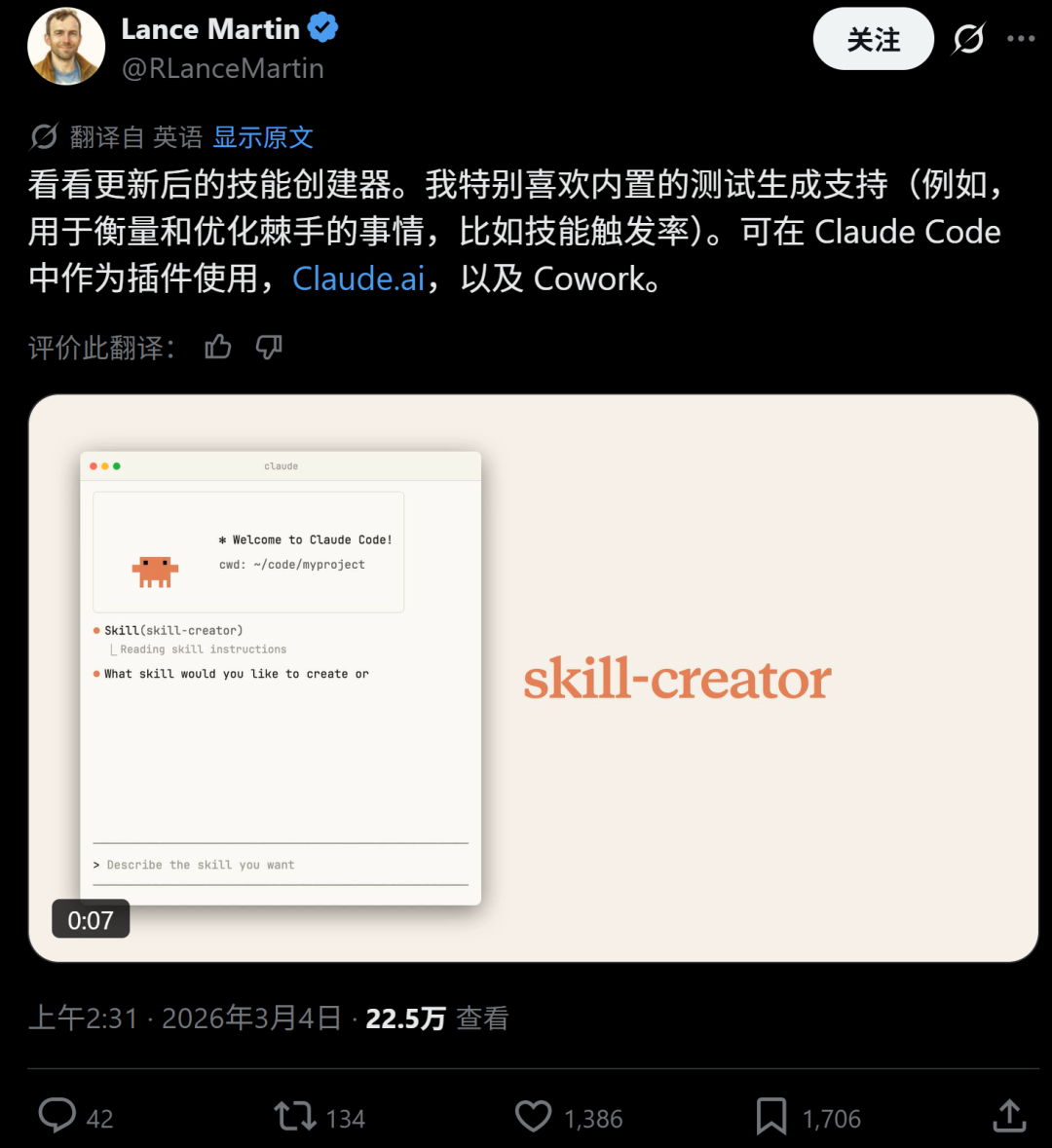
视频如下。
开发者Numman Ali发帖,称新的skill-creator比起旧版是一个巨大进步,用它升级旧技能,其改进程度简直令人惊讶,简直可以说是起死回生。
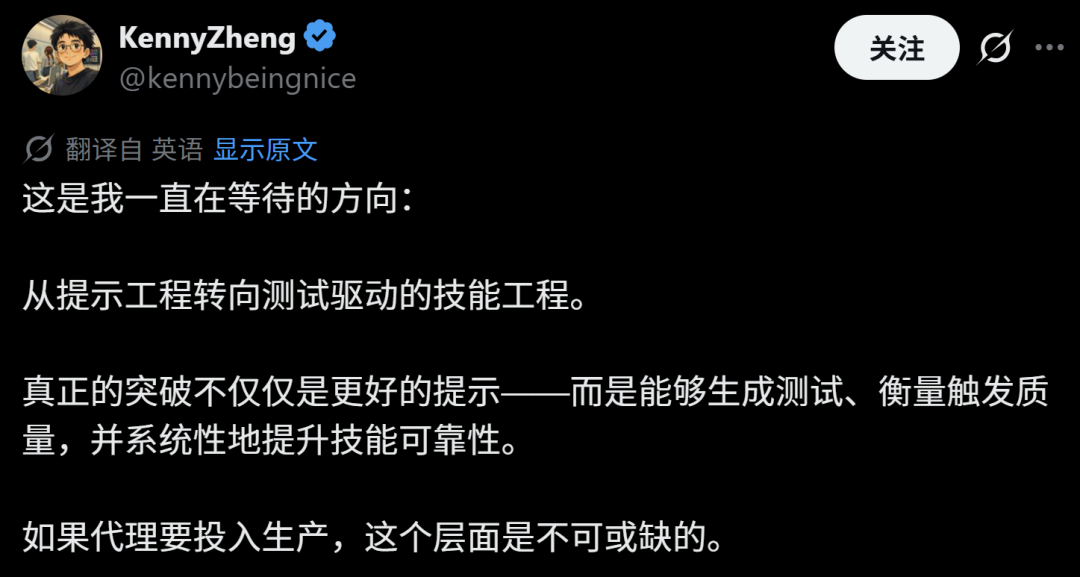
前 CapCut/Hypic AI PM,现独立 AI 构建者KennyZhang发帖,从开发者的角度说,“真正的突破不仅仅是更好的提示——而是能够生成测试、衡量触发质量,并系统性地提升技能可靠性”。
Brain Rabun,Living Intelligence 构建者从一个更宏观的背景下观察,结合内部观点(Claude 代码即将99% AI 生成,工程师变 agent 管理者),以及恶意链式使用报告,强调 skill-creator 中的 evals 等测试层是防备恶意的必要基础设施。


03 AI 智能体的CI/CD时刻:从艺术品变成了工程产品
Anthropic 此次对 skill-creator 的升级,本质上是把软件工程中最成熟的那一套“测试-基准-迭代”闭环,低门槛地带给了普通用户和企业团队。这意味着 Agent Skills 不再是“写完就扔”的一次性 prompt 工程,而是可以持续维护、跨模型版本兼容、可数据化优化的“活资产”。
短期来看,最大受益者是已经在 Claude Code / Cowork 里积累了大量自定义技能的开发者与企业用户。他们可以用 evals 快速诊断旧技能失效点、用 benchmark 对比迭代前后表现、用触发率优化降低误触发成本,整体工作流可靠性有望大幅提高。
而放眼更宏观的视角,这次更新进一步夯实了 Anthropic 在 Agent 生态中的“工具链护城河”。当 OpenAI、Google 等还在比拼基础模型能力时或自己家的生态迁移性时,Anthropic 已经开始抢占“后训练时代”的生产力基础设施,即可测试、可移植、可治理的 Skills 标准。如果未来 Skills 真正成为跨平台开放协议(Anthropic 已在2025年底推动过类似尝试),那么 Claude 生态很可能复制当年插件经济或 npm 生态的网络效应,越多人贡献高质量、可验证的技能,整个 Agent 生产力天花板就被越高推。
更激进地说,当 evals 框架成熟到一定程度,skill-creator 本身或许会进化成“元目标描述器”,用户只需要告诉 AI “我要实现什么业务目标”,剩下的实现路径、测试用例、迭代优化全部交给多智能体闭环自动完成。
那时我们谈论的就不再是“怎么写 Skill”,而是“怎么教 AI 自己学会写更好的 Skill”。










