绑定手机号
确认绑定









智猩猩AI整理
编辑:没方、汐汐、卜圆
DeepSeek最新开源的「记忆」模块再次刺痛硅谷!当行业仍在为扩大模型参数量激烈竞争时,DeepSeek与北京大学的研究者们提出了一个颠覆性思路:给稀疏模型引入“条件记忆”,使大模型得以从根本上摆脱用昂贵计算动态重建静态查表的低效模式,为下一代稀疏模型奠定了一种全新的基础范式。研究团队引入Engram模块以实现条件记忆,上线不足24小时便在GitHub斩获 1.2k star,同时在社交平台上引发技术圈火热讨论,包括PyTorch核心维护者Dmytro Dzhulgakov在内的不少专业开发人员对其表示认可。

论文链接:https://github.com/deepseek-ai/Engram/blob/main/Engram_paper.pdf
项目地址:https://github.com/deepseek-ai/Engram
01 条件记忆:下一代稀疏模型基础建模范式
MoE 通过条件计算扩展模型容量,以低计算开销实现模型规模大幅提升,已成前沿大模型核心架构选择。
语言建模包含两类子任务:组合推理(compositional reasoning)与知识检索(knowledge retrieval)。组合推理需要深度、动态的计算;知识检索对应的文本内容(如命名实体、公式化表达)具有局部、静态且高度刻板化的特点,经典 N-gram 模型在捕捉此类局部依赖关系上十分有效,这些规律天然适合以低计算成本的查表操作来表示。
尽管条件计算范式取得了巨大成功,但Transformer 架构缺乏原生的知识查表机制,迫使当前 LLM 必须通过计算来模拟检索过程。例如,解析一个常见的多词元实体(multi-token entity)往往需要消耗多个早期注意力层和前馈网络,该过程本质上是在运行时以高昂代价重建一个静态查表,导致宝贵的序列深度(sequential depth)被大量耗费在琐碎操作上。而若采用直接查表机制,这些计算资源便可用于更高层次的推理。
为使模型架构更好地契合语言的这种双重特性,DeepSeek联合北大的研究者们提出条件记忆,为大模型引入了一种全新的稀疏化维度。如果说条件计算是通过稀疏激活参数来处理动态逻辑推理任务,那么条件记忆则通过稀疏查表操作,高效检索用于表征固定知识的静态嵌入。
研究团队引入Engram 模块以实现条件记忆,该模块对经典的 N-gram 嵌入进行改造,可支持O(1) 常数时间查表操作,可成为MoE架构的理想补充。Engram 采用了四项核心技术:分词器压缩(tokenizer compression)、多头哈希(multi-head hashing)、上下文门控(contextualized gating)以及多分支集成(multi-branch integration)。
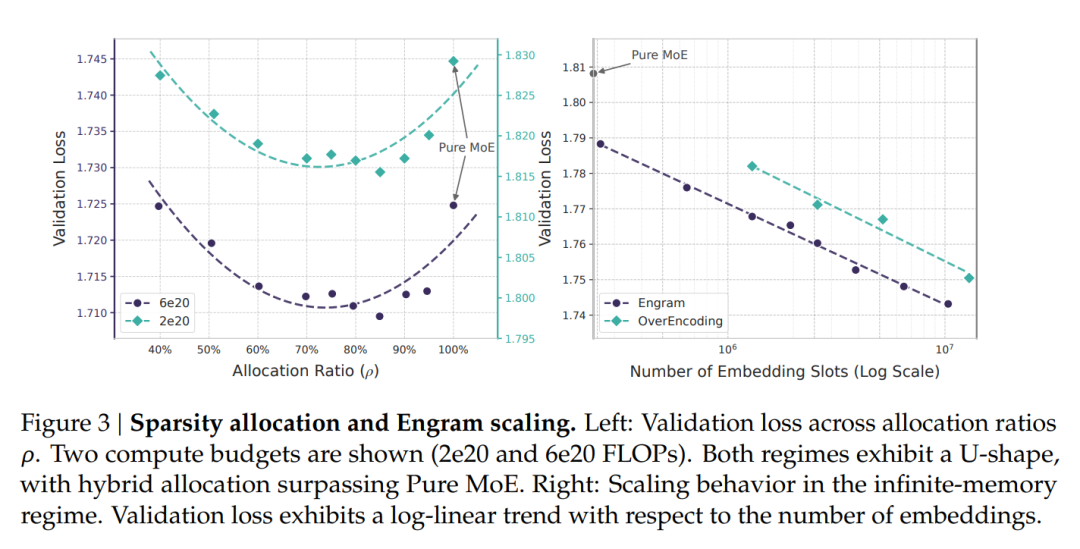
为量化模型推理和知识检索之间的协同效应,研究团队将其形式化为“稀疏分配问题”(Sparsity Allocation Problem):在总参数预算固定的前提下,应如何在 MoE 专家和 Engram 记忆之间分配容量?研究团队通过实验揭示了一条U形scaling law,表明在 MoE 专家与 Engram 记忆之间进行混合分配稀疏容量,会优于纯 MoE 基线模型。
依据该分配规律,研究团队将 Engram 参数规模扩展至27B。在多个领域均取得了更优的性能。值得注意的是,尽管记忆模块从设计直觉上聚焦于提升知识检索能力,但其在通用推理、代码和数学任务上的增益幅度反而更为突出。
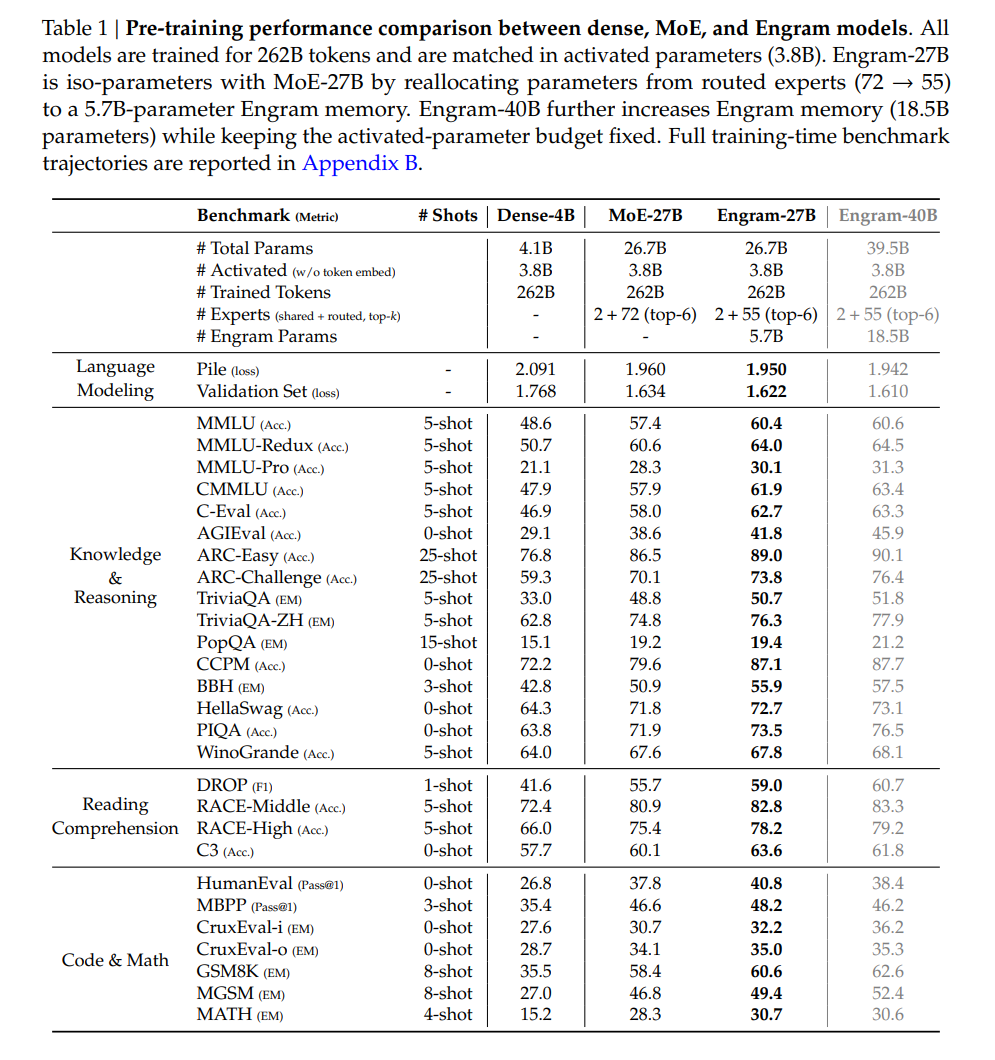
Engram 减轻了主干网络在早期层重建静态知识的负担,从而释放出更多有效深度用于复杂推理。此外,通过将局部依赖交由查表处理,Engram 释放了注意力机制的容量,使其能更专注于全局上下文,从而大幅提升长上下文处理能力。
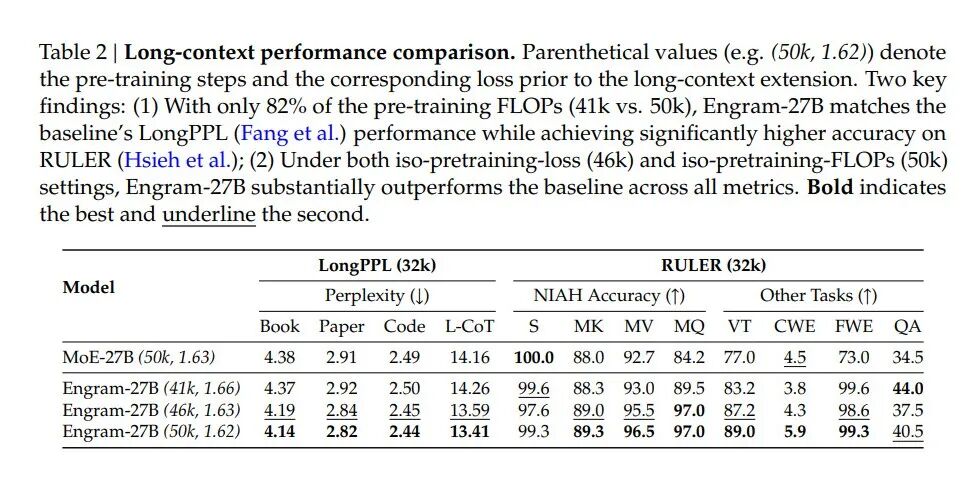
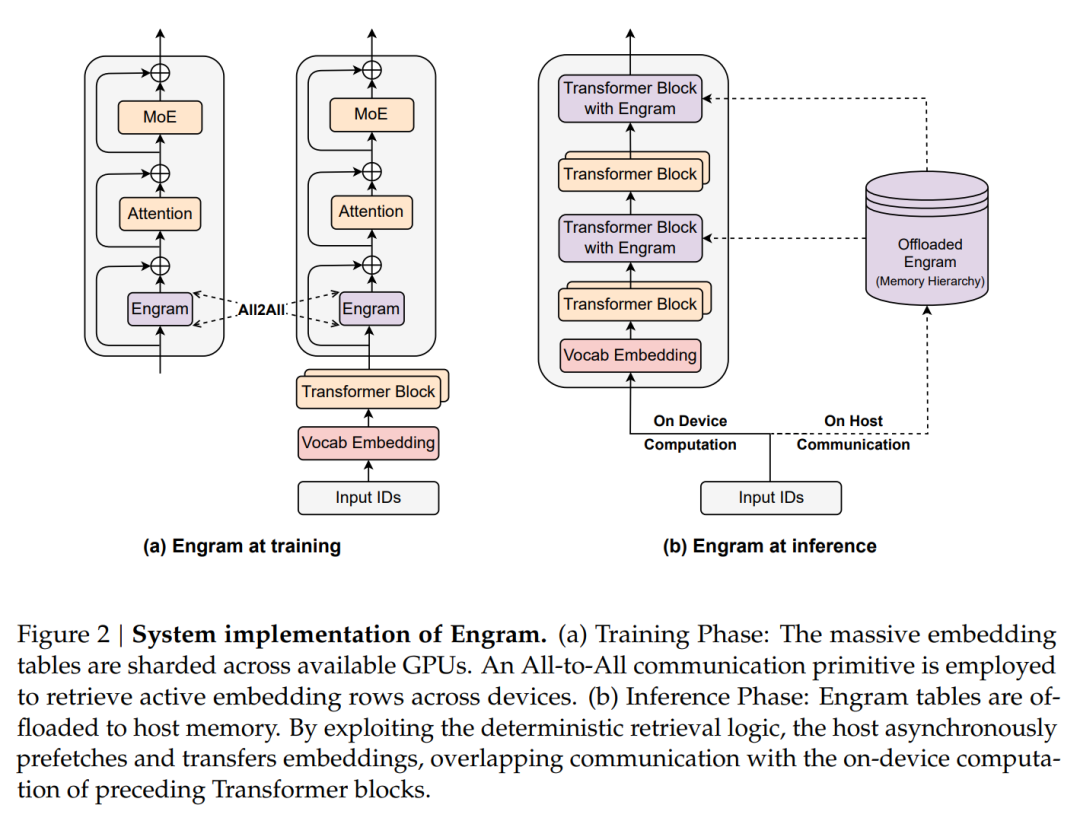
Engram 实现了面向基础设施的高效设计,其确定性的寻址机制支持在运行时从主机内存预取数据,实现通信与计算重叠。实验结果表明,将一个 100B参数规模的查表卸载至主机内存所带来的额外开销微乎其微(< 3%)。研究团队相信,条件记忆将成为下一代稀疏模型中不可或缺的基础建模范式。
02 网友评论:我本打算从谷歌抄的,得从DeepSeek抄了

Engram 的核心创新之一,在于其 O(1) 复杂度的哈希 N-gram 查找机制。它可以高效存储和检索静态、重复性强的模式信息,从而避免模型在每一次推理中反复“思考”这些已知内容。
有网友评论这一机制,将其形象地比喻:为模型配备了一块“高速外存”。
PyTorch 核心维护者之一,并曾参与 ONNX 的联合创建的开发者Dmytro Dzhulgakov,对DeepSeek开源的Engram工作表达了比较积极的态度,并表示其理念与他曾在Meta中参与过的一些工作相似。

X上的网友表示,Deepseek Engram技术的方向非常有意思,能够降低开销,但是在这方面仍然保有疑虑,比如说除了在Benchmarks的干净的输入外,Engram方法是否能够在未来长时间的过程当中从混乱的真实输入中减少错误:

当然也有网友表达了幽默的意见:
除此之外,还有网友表达了比较辩证的看法,表示这个工作可能一眼看上去并不精细甚至可以说是相当粗糙,但是却是一种很有意思并且很直观的方法,将模型的学习记忆与推理两方面隔离开:
同样的,除了上述对Engram方法提出的直接见解之外,还有例如对AIGC、AI剪辑、渲染和AI资源生成领域也表达了一些看法:
也有网友对该工作提出了非常高的评价,表示Engram为未来的AI铺平了道路,例如说未来如果要进行长期的角色扮演,在长时间的过程中,通常的大模型会丢失上下文信息,并且可能需要重复输入prompt。但是有了Engram后,角色与情境本身就是其一部分:

有中国网友表达了对未来AI发展的硬件方面的考量。同时提出了一个很有意思的构想:是否能够让Engram可拔插而不是端到端的,这样的话未来更新模型知识并不需要完全训练整个Expert。
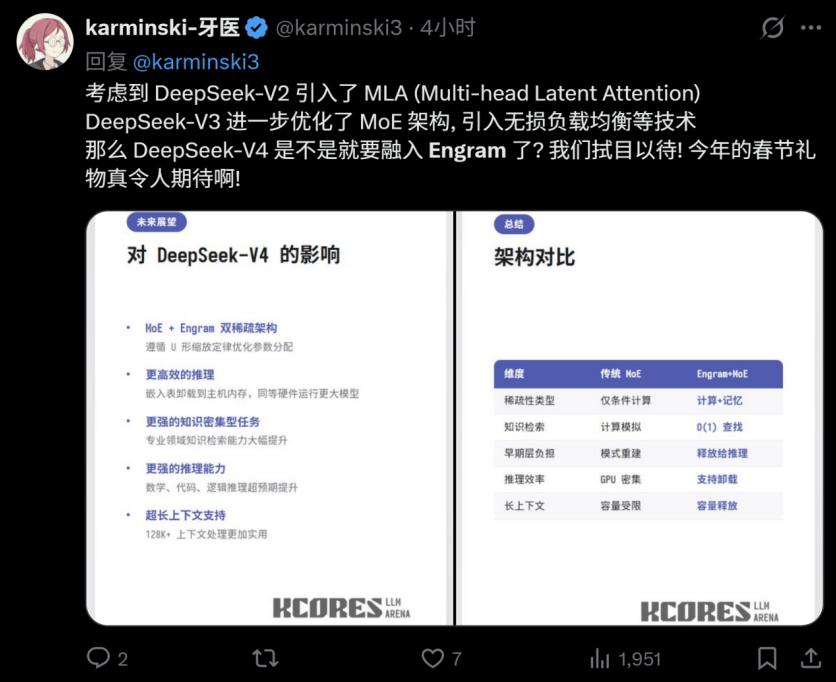
同时,有消息声称Deepseek V4将在春节前发布,该网友对Deepseek后续发布模型(V4)的架构和一些可能的优化策略进行了预测:
03 V4有望春节前后发布,架构创新推动范式转变
在架构革新的浪潮中,DeepSeek 联合北京大学提出的Engram,减轻了主干网络在早期层重建静态知识的负担,使其更专注于高阶逻辑推理与泛化,为下一代稀疏大模型提供了全新的技术路径。
此前,DeepSeek提出的mHC架构,则确保了“思考系统”本身的稳健与高效。它通过数学约束稳定了深层网络的信息流,为复杂推理提供了可靠的基础架构。
以此为镜,V4 的进化可能不在于参数的单纯增加,而在于通过系统性的架构创新,重新定义大模型的能力边界与效率极限。在Engram与mHC等前沿技术的协同下,V4或将真正实现“高效计算+结构化记忆” 的混合智能范式,引领AI迈向一个更高效、更可靠、更具认知深度的新时代。
值得注意的是,多方信息显示,DeepSeek V4 有望在 2026 年农历春节前后重磅发布,延续此前 R1 时代“节日窗口”的传播效应。这一时间节点的选择颇具深意,它不仅象征着技术突破的“辞旧迎新”,更可能预示着一次重要的范式转变。这场即将到来的技术盛宴,值得我们共同期待。










