绑定手机号
确认绑定









Soul App投稿
智猩猩AI整理
当金鱼精走进录音室唱起《菩萨鱼》,当孙悟空也能玩起流行摇滚乐......
从《西游记》AI神曲刷屏到各类AI歌手出圈,过去一年,生成式人工智能在音乐行业的应用正不断创造新体验,不少AI音乐作品破圈,但当聚焦到技术层面,歌唱语音合成领域(SVS,Singing Voice Synthesis)一直缺少一个亮点工作。特别是传统SVS模型存在大多在规模较小的数据集上训练、缺乏对未见歌手的泛化能力等局限。
为此,Soul App AI 团队(Soul AI Lab)发布了面向真实工业场景设计的高质量零样本歌声合成模型 SoulX-Singer,超 42000 小时训练数据,覆盖多语言、多音色及多种演唱风格,在稳定性、可控性与泛化能力方面,均达到了当前开源 SVS 模型中的SOTA。
注:此视频中的人声由SoulX-Singer生成

论文标题:SoulX-Singer: Towards High-Quality Zero-Shot Singing Voice Synthesis
Technical Report: https://arxiv.org/pdf/2602.07803
Demo Page: https://soul-ailab.github.io/soulx-singer/
Source Code:https://github.com/Soul-AILab/SoulX-Singer
HuggingFace: https://huggingface.co/Soul-AILab/SoulX-Singer
01 研究背景
SVS(Singing Voice Synthesis,歌唱语音合成)是一种根据歌词和乐谱生成歌声的技术。相比于普通语音合成(TTS, Text-to-Speech Synthesis),SVS 需要对音高、音律以及演唱风格等进行精细控制,以实现自然且富有表现力的歌声输出。与近期热门的 Music Generation(自动生成整段音乐或伴奏)不同,SVS 专注于可由 MIDI 控制的人声生成,因此在虚拟歌手、歌词演绎以及多语言歌声创作等场景中展现出独特价值。
过去一段时间,语音合成与音乐生成领域迎来了快速发展,大模型与生成式AI 持续刷新行业认知。然而,与这一热潮形成对比的是,行业内仍缺乏一个真正稳定可用、同时支持零样本(Zero-shot)生成的开源歌声合成(SVS)模型,这很大程度上制约了 SVS 技术在真实业务场景中的应用与落地。具体来说,目前该领域面临的痛点包括:
零样本泛化困难:之前相关的工作,比如StyleSinger和TCSinger等受限于数百小时的数据和有限的歌手数量,难以实现鲁棒的零样本泛化。
控制方式单一:近期工作大多采用旋律驱动的合成范式,不提供音符级别的时长控制,导致两个关键问题:一是需要从现有歌曲中提取旋律,无法纯粹从乐谱和歌词生成歌曲;二是缺乏显式的音符时长建模,使得音节级时序不可控,导致合成歌声与原始伴奏时间不对齐。
工业部署障碍:现有开源SVS系统在鲁棒性和零样本泛化方面存在显著障碍,难以满足实际音乐制作工作流的需求。
为了解决这些挑战,研究团队提出了SoulX-Singer,该工作在以下方面实现了重要突破:
(1)Music Score 与 Melody 多种控制方式
在生成控制能力方面,SoulX-Singer 同时支持基于 Music Score(MIDI) 和 基于 Melody 的两种歌声合成控制方式。前者强调精确的符号级控制,适合从零进行歌曲创作;后者则通过对参考旋律与演唱方式的建模,实现对已有歌曲的风格迁移与翻唱生成。
这种统一但灵活的控制框架,使模型能够无缝适配从创作到再创作的完整音乐生产流程。
(2)大规模SVS 训练数据
零样本歌声合成对训练数据的规模、多样性与覆盖范围提出了极高要求。SoulX-Singer 得益于超过 42000 小时的高质量歌声数据进行训练,覆盖多语言、多音色及多种演唱风格。
(3)高质量零样本克隆
在大规模数据的支持下,模型在面对未见过的歌手与复杂音乐条件时,依然能够保持稳定、自然且高质量的合成表现。在实际测试中,SoulX-Singer 展现出了良好的鲁棒性和一致性,为零样本歌声合成技术从“可演示”走向“可使用”提供了坚实基础。
(4)支持多语言支持
SoulX-Singer 当前支持普通话、英语和粤语三种语言的歌声合成,并在不同语言和音乐风格下均展现出稳定一致的合成质量。这一多语言能力为其在内容创作、虚拟歌手、互动娱乐等应用场景中的落地提供了更广阔的空间。
(5)专用评估基准
构建了SoulX-Singer-Eval基准数据集,包含50位未见歌手(25位中文、25位英文)的100个演唱片段,并进行了精细的音符级旋律标注,为零样本SVS性能的系统评估提供了可靠平台。
02 方法
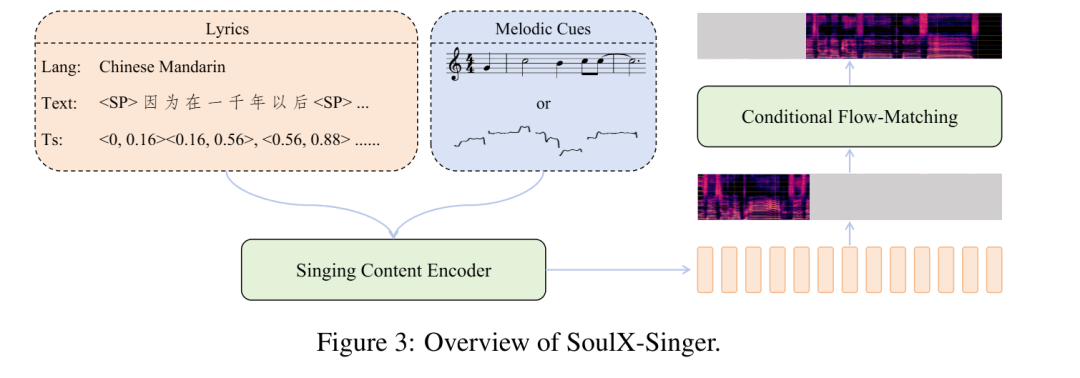
带有 MIDI 乐谱与对齐歌词标注的干净歌声录音是训练具备精细、基于乐谱可控性的歌声合成模型的关键前提。为了获得对齐的歌声音频、MIDI 以及歌词标注,研究团队构建了一条完整的数据处理工作流,涵盖歌声分离、歌词转录与音符转录等步骤。整体处理流程如下:
歌声分离。为了获得不含伴唱的高纯度干声,采用两阶段歌声提取策略。首先,使用预训练的主唱分离模型提取主唱并抑制伴唱与和声。考虑到商业录音在混音过程中通常会引入明显混响,随后进一步应用预训练的歌声去混响模型,以获得更加接近录音室干声条件的数据。
自动歌词转录。不同ASR模型在不同语种上的表现差异较大。为了尽可能提高歌词准确率并保证时间戳对齐质量,SoulX-Singer 的数据处理管线引入了一个基于 SenseVoice 微调的语种识别模型:首先进行语种判别,再调用对应语种最优的 ASR 模型获取歌词及字级时间戳。
音符转录。为了生成与歌词对齐的音符级表示,采用ROSVOT模型进行音高级估计和音符边界检测。具体来说,将上一阶段获得的时间戳歌词作为输入,生成沿时间轴严格对齐的音符级token序列,包括文本、音高、音符类型及其时长信息。这些结构化的对齐表示为可控且富有表现力的歌声合成提供了必要的基础。
基于上述处理流程,研究团队最终构建了约 42,000 小时的高质量歌声数据集:其中中文与英文各约 20,000 小时,粤语约 2,000 小时。为了实现对歌声的精细建模,数据集以“音乐音符”为基本组织单位。具体而言,每个音符被表示为一个元组,包含对应的文本 token、音高以及音符类型。其中音符类型为离散分类属性:
1 表示休止符(rest),2 表示歌词音符(lyric note),3 表示连音音符(slur note)。
这种音符级表示方式能够在语音内容与旋律结构之间建立高精度对齐关系,从而为可控、自然且富有表现力的歌声合成提供稳定而可靠的数据基础。
SoulX-Singer 是一个面向真实工业应用场景设计的零样本歌声合成模型,其核心目标是在未见过歌手音色的情况下,实现稳定、自然且高度可控的歌声生成。为此,模型在整体架构、建模范式以及控制机制上进行了针对 SVS 场景的系统性设计。
在模型架构上,SoulX-Singer 采用 基于 Flow Matching 的生成建模范式,并将歌声合成问题建模为一种 audio infilling(音频补全)任务。针对歌声合成中“歌词—旋律—发声”三者强耦合的特点,SoulX-Singer 在建模阶段显式引入了 note 级别的对齐机制。模型通过构建歌词、MIDI 音符(note)与声学特征之间的精细对齐关系,使得每一个音符的 起止时间、音高(pitch)以及持续时长 都能够被准确建模和独立控制。这一设计使得模型不仅能够忠实还原乐谱信息,还可以在生成阶段灵活调整音符结构,从而满足音乐编辑、重编曲等复杂需求。
此外,SoulX-Singer的训练分为两个阶段,逐步增强模型的鲁棒性和长文本生成能力。
在第一阶段,模型在相对较短的音频片段上进行训练,时长从2秒到16秒不等。在这个阶段,提示mel频谱图是从目标音频的非相邻片段中采样的。这种设计鼓励模型减少对局部声学连续性的依赖,更多地依赖于提供的语言和音乐条件,从而提高鲁棒性和泛化能力。
在第二阶段,训练策略转向了长声部歌唱声音建模。相邻音频片段被连接起来构建持续时间在30秒到90秒之间的较长训练样本,使模型能够捕捉歌唱表演中的长距离时间依赖关系。为了进一步增强模型的即时响应能力,在本阶段的提示音频是从目标音频的紧邻前一段采样而来的。
通过采用这种两阶段训练策略——从简短、不相邻的提示逐步过渡到长篇、上下文相邻的提示,SoulX-Singer实现了稳健的条件生成和对长时歌唱音频的有效建模。
03 评估
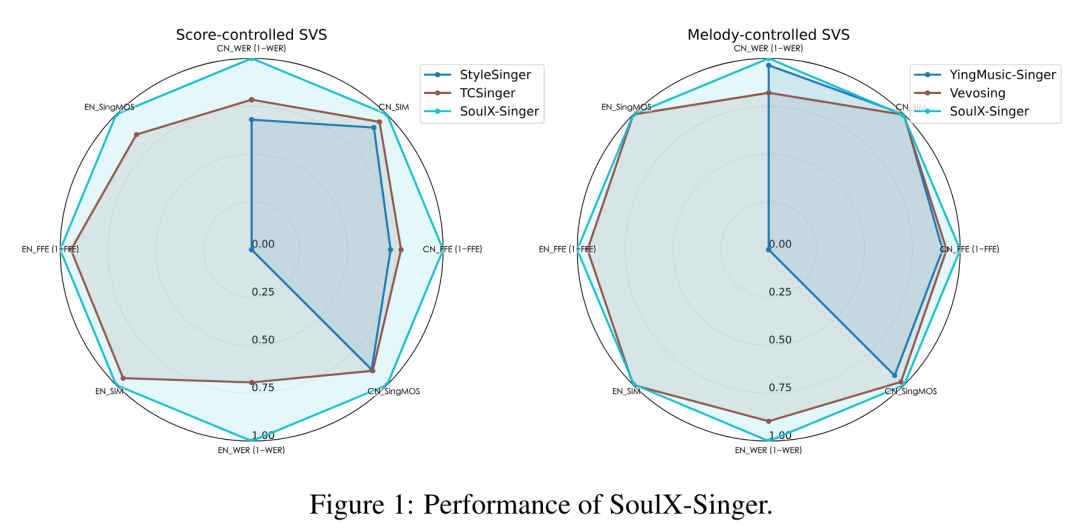
在GMO-SVS和SoulX-Singer-Eval两个评估基准上的实验结果表明,SoulX-Singer在旋律控制模式下实现了最低的F0帧错误率(FFE),在乐谱控制模式下达到了最低的词错误率(WER),同时在音色相似度(SIM)、SingMOS和Sheet-SSQA等质量指标上均超越了所有基线模型。
在跨语言合成任务中,SoulX-Singer在保持高音色相似度(SIM=0.898)的同时,显著优于基线模型Vevosing(WER从0.717降至0.110),证明了其在严格分离说话人身份与语言内容方面的有效性。