绑定手机号
确认绑定









AMAP CV Lab团队投稿
智猩猩AI整理
机器人领域长期追求“One-Brain, Many-Forms(一个大脑,多种形态)”的通用智能体:在不同机器人本体、不同任务与不同场景下,依然具备可迁移、可泛化、可组合的操作能力。
现实瓶颈主要集中在三方面:
数据层:开源数据分散在不同平台与格式中,难以统一治理与复用;同时高质量动作标注成本高、积累慢。
表征层:不同数据集动作空间、坐标系、控制频率各异,导致跨本体学习难以对齐,模型容量被迫“记住差异”。
训练层:主流VLA 往往沿用 VLM 范式,但机器人操作需要更强的空间结构理解与稳定的动作生成目标,二者存在天然错配。
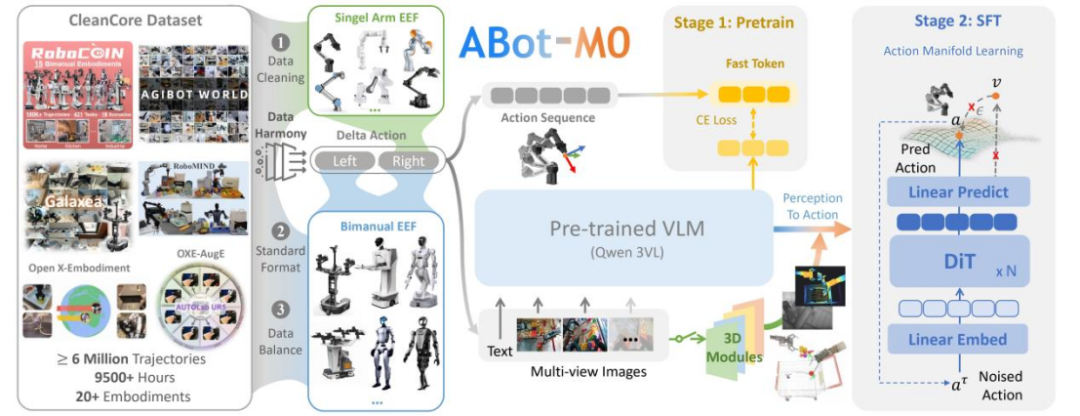
为此,阿里巴巴高德AMAP CV Lab团队发布 ABot-M0:一个面向机器人操作的 视觉-语言-动作(VLA)基础模型框架,以“数据治理 + 统一动作表征 + 新的动作学习范式 + 可插拔感知结构”为核心,提供一条从异构开源数据到高性能通用策略的系统化、可复现路径。ABot-M0在具身智能领域主流三大开源仿真评测基准Libero、Libero-Plus、RoboCasa中,平均任务成功率均实现SOTA。

论文标题:《 ABot-M0: VLA Foundation Model for Robotic Manipulation with Action Manifold 》Learning
论文链接:https://arxiv.org/abs/2602.11236
代码:https://github.com/amap-cvlab/ABot-Manipulation
项目主页:https://amap-cvlab.github.io/ABot-Manipulation
01 ABot-M0 的关键贡献(从数据到模型的完整闭环)
1. UniACT-dataset:统一、开源、超大规模的操作数据基座
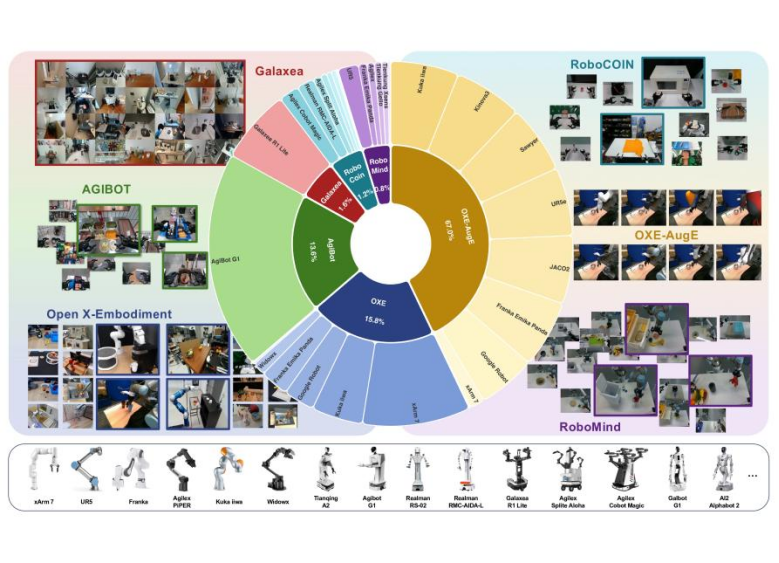
AMAP CV Lab团队整合并治理 6 个主流开源数据集,构建 UniACT-dataset:目前非私有领域内规模领先的机器人操作混合数据集之一,覆盖 600 万+ 轨迹、9500+ 小时、20+ 机器人形态(embodiments)。其价值不只是“更大”,更是“可对齐、可训练、可迁移”。
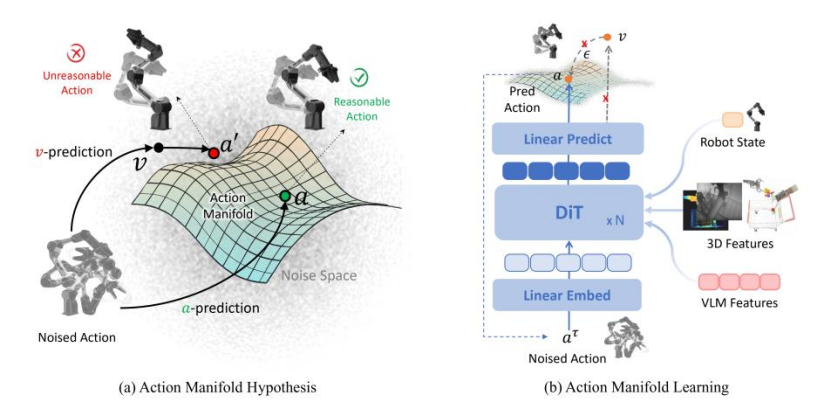
2. Action Manifold Learning(AML):面向机器人动作生成的学习范式升级
在动作生成上,ABot-M0 提出动作流形假说(Action Manifold Hypothesis):有效、可执行、连续的机器人动作序列并不随机分布在高维空间中,而是受物理规律与任务约束影响,集中于一个低维、光滑的“动作流形”之上。
据此该团队设计 Action Manifold Learning(AML):以 DiT(Diffusion Transformer) 为动作专家骨干,不再以预测噪声为核心目标,而是更直接地学习生成“可行、平滑、连续”的动作序列,从而在效率、稳定性与高维动作空间建模方面取得优势。
3. Modular Perception:语义与几何解耦、可插拔的双流感知架构
标准VLM 擅长语义理解,但在精细 3D 空间推理上存在结构性短板。ABot-M0 采用双流感知:
VLM 语义流:以 Qwen3-VL 为骨干,承担视觉理解与语言对齐。
3D 几何流(可选、可插拔):通过模块化方式引入几何先验,例如 VGGT(单图3D 结构特征)与 Qwen-Image-Edit(多视角合成与特征融合)。
该设计的工程优势在于:无需修改骨干网络,即可按任务需求开启/关闭 3D 能力注入,实现从通用到高精度的能力扩展。
02 方法要点:统一动作空间、统一训练接口、统一单/双臂能力
1. 统一动作表征:跨本体对齐的关键工程
针对开源数据中的动作定义不一致问题,该团队将所有数据统一到:
末端执行器(EEF)坐标系下的增量动作(Delta Actions)
旋转统一为更稳定的 旋转向量(Rotation Vectors)
单臂/双臂统一采用 Pad-to-Dual-Arm(填充至双臂):单臂数据在未使用手臂维度进行零填充,使单一策略网络能够统一学习与推理。
这套标准化显著降低跨本体学习中的“对齐成本”,让模型容量更多用于学习可迁移的操作规律。
03 实验结果:多基准验证的性能与泛化
AMAP CV Lab团队在多个主流仿真基准上对ABot-M0 进行了系统评估,结果表明其在“高成功率 + 强鲁棒性 + 跨场景泛化”上具备一致优势。
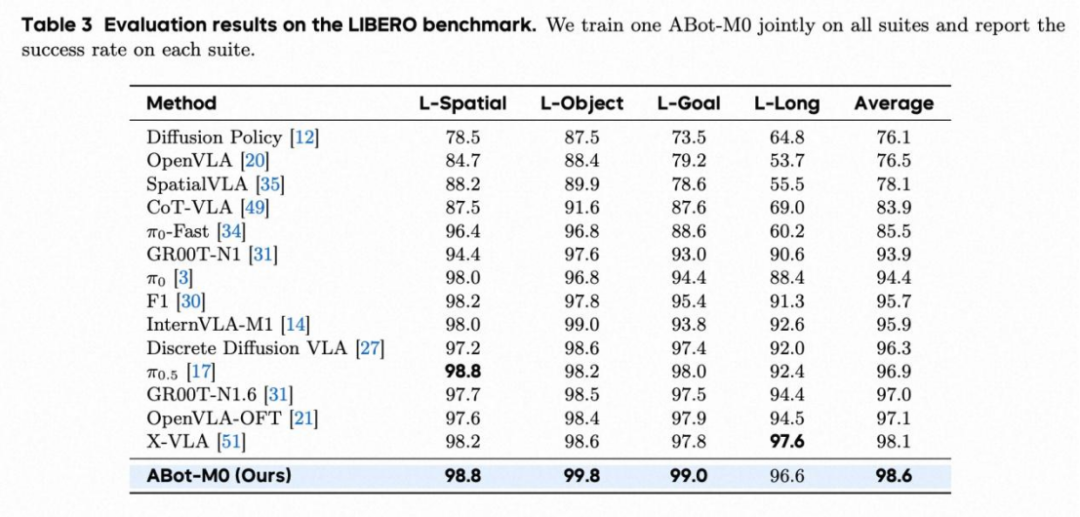
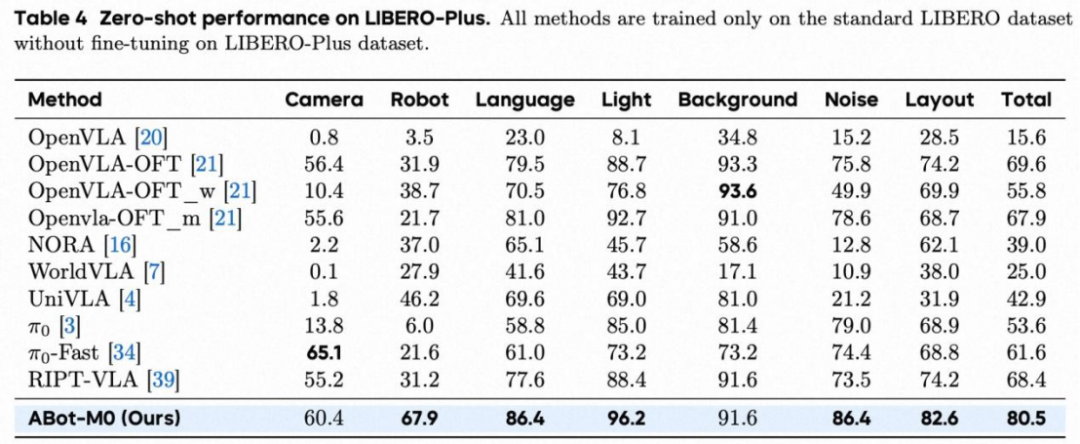
1. LIBERO & LIBERO-Plus
LIBERO:平均成功率 98.6%,在长序列任务上表现突出。
LIBERO-Plus(零样本鲁棒性评估):成功率 80.5%,显著领先多种强基线,体现对视觉/语言扰动与场景变化的稳健泛化能力。
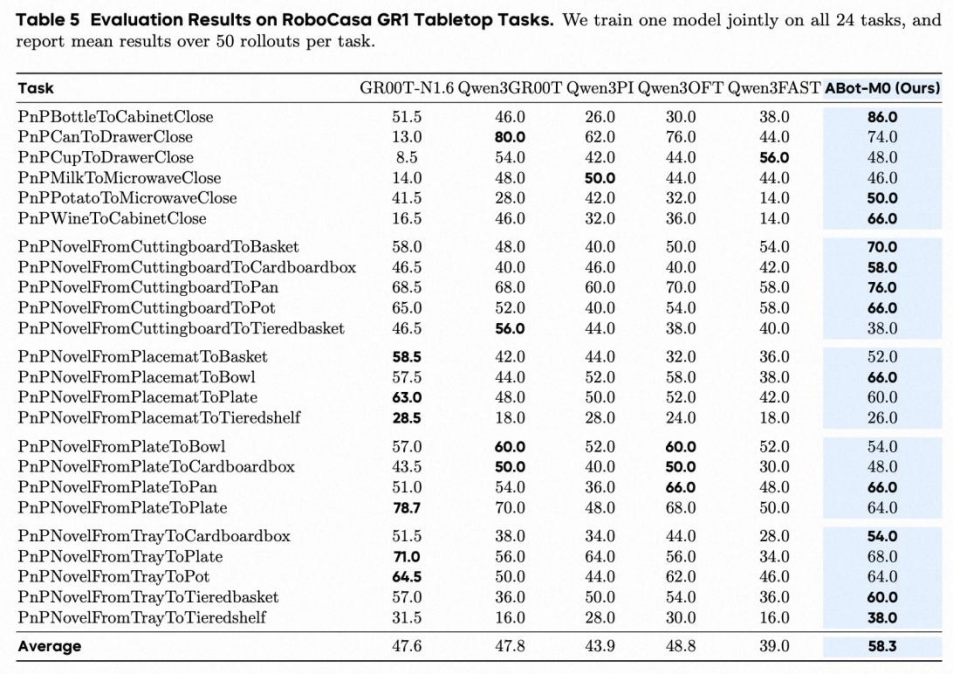
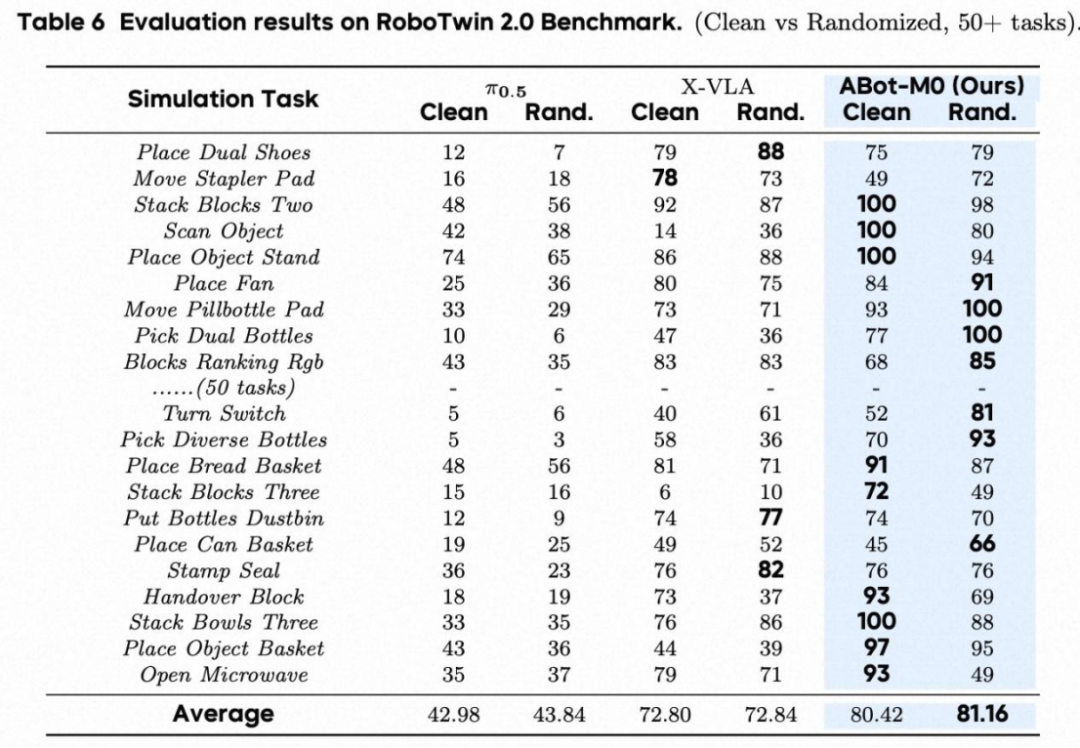
2. RoboCasa GR1 & RoboTwin 2.0
RoboCasa GR1(高维双臂/全身动作空间):成功率 58.3%,验证AML 在高维动作建模与长 chunk 预测中的优势。
RoboTwin 2.0(多任务 + 强随机化):随机化场景下成功率 81.2%,优于π0.5、X-VLA 等基线,体现跨任务鲁棒学习能力。
04 开源与意义:在公开资源上构建可复现的通用操作基座
ABot-M0 不仅是一个更强的 VLA 模型,更是一套面向“通用具身智能”可落地的系统化方案:
从 多源开源数据治理 出发,提供统一标准与训练接口
通过 动作流形学习(AML) 提升动作生成稳定性与效率
以 模块化感知架构 兼顾语义泛化与 3D 精度需求
支持后续在更多本体、更长任务、更高自由度控制上的可扩展研究










