绑定手机号
确认绑定









作者:王峰
地址:https://zhuanlan.zhihu.com/p/1995493539912623296
经授权发布,如需转载请联系原作者
本文所使用的分析方法,其实也是一众做loss function论文中常用的:一个loss对神经网络起作用的是它的梯度,而loss本身是什么形式并没有那么重要,所以我现在看到一个loss就习惯性地会对它求导,看看它的梯度,推导一下,再积分回去,就可以得到另一种loss形式,有时就会有一些新的体会。
本文准备介绍一下Flow-GRPO[1]、AWM[2]、DiffusionNFT[3]这三篇比较有代表性的文章,分别求一下它们的梯度和等效loss,通过这些分析,可以对DiffusionRL究竟在做什么有更深的理解。
阅读之前,建议还是先对这三篇文章有所了解,本文并不会过多介绍它们的基本原理,感兴趣的直接在知乎上搜对应文章即可。
01 Flow-GRPO
Flow-GRPO这篇文章之前也说过,提供了一个相当不错的代码基础和benchmark,过去一年有很多DiffusionRL的工作都是在此之上进行的。关于这篇文章的分析也挺多的,例如Flow Matching RL(一):Flow-GRPO在学什么? 和 DiffusionNFT的附录,我的结论与他们类似,看过的话可以跳过这一节。
Flow-GRPO使用SDE来在采样中间过程引入随机性,在每一步新加一个高斯噪声 :

在使用SDE获得了一系列样本(图像) 之后,输入reward model即可得到其reward ,之后计算GRPO Advantage:
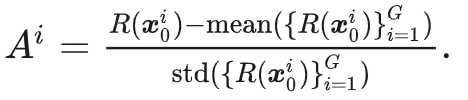
其最终的loss就是GRPO的loss(在此忽略KL项):

其中 ,而 服从高斯分布,其对数概率被定义为:

其中 代表训练时的一步预测但不加噪声,而 表示采样过程的一步预测加噪声。在每一步, 是一个常数,在 中可以被约掉,所以对数概率可以化简为:
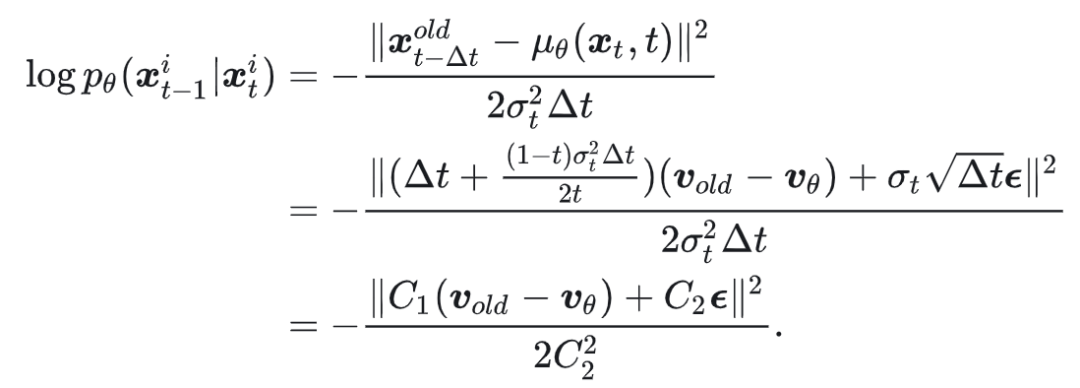
这里将两个常数分别用 和 替换以减少公式复杂度。
下面重点来了,对prob ratio 求导:

这里 是梯度截止符,前边这个指数项不改变梯度方向,而且 和 一般来说非常接近,在刚采样完成的第一个iteration这两者甚至完全一样,其实按flow-grpo的设定1个epoch里也就只有2个iteration,所以这里直接约等于了。
注意到loss中还有一堆min和clip,这个是PPO clip,起到稳定训练的作用,我们在分析时可以将其省略。所以loss的梯度为:

这里第一个约等于是因为上一个公式有一个约等号,第二个约等于则是假设了 ,这个假设跟上边假设 类似,但上边那个假设即使不成立也并不影响梯度方向,而两个速度相减直接影响了梯度方向,所以这个假设有一点牵强。
不过后来,Flow-GRPO原作者组里又出了一篇文章叫GRPO-Guard[4],对这个问题进行了修正,他们修改了log-prob的定义,最终起到的效果之一就是在梯度中去掉了 那一项,修正之后,后一个约等号就变成等号了,具体的改动可以看一看GRPO-Guard这篇文章,里面也有对梯度的分析,与本文的结论一致。
所以说,Flow-GRPO的policy gradient实际上是使用advantage加权的噪声,这一点其实还是有一点奇怪的,速度应该朝另一个速度的方向移动,沿噪声方向移动有什么意义?而这可能也是其优化效率不如后两个算法的原因。
速度 沿着梯度方向进行梯度下降,我们也可以求得其对应的目标位置: ,从而构成另一个loss:
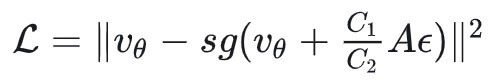
可以一眼看出来,这个损失函数的梯度跟上边是一样的。
如果只在意梯度方向而不在意幅度的话,则另一个对应目标位置为: ,实际上梯度下降也不可能真的到达 ,只能说向这个目标移动,射线上的每个点都可以作为目标,所以说 是优化目标也没什么错误。
02 AWM
AWM这个算法相当的简单,但效果却很不错,具体可以看作者的介绍:优势加权匹配(AWM):让扩散模型的强化学习与预训练对齐 。原文是从方差的角度来解释的,但本文从梯度角度也可以解释为什么它的优化效率如此的高。
AWM的训练过程与Diffusion本身的训练过程很类似,在采样到样本 之后,对样本重新进行加噪来训练,加噪方式和loss都与Diffusion基本一致,只是在最终loss的前边套上了advantage作为loss weight:

这几个公式熟悉flow matching的人都应该能看出来,其实就是标准的FM训练过程加了个weight,所以这篇文章的名字就叫advantage weighted matching,有点返璞归真的意味。
下面对这个loss求一下梯度,也非常简单:
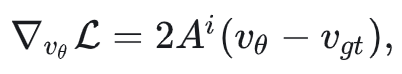
其对应的优化目标(之一)为: ,这个优化目标就比Flow-GRPO的好理解多了,起码v应该是向另一个v移动:如果当前样本很好时,比如A=1,那么优化目标就是 ;当样本很差例如A=-1时,要将其沿 推向远离 的方向,此时优化目标为 ,也就是向外插1倍的位置,非常的直观:
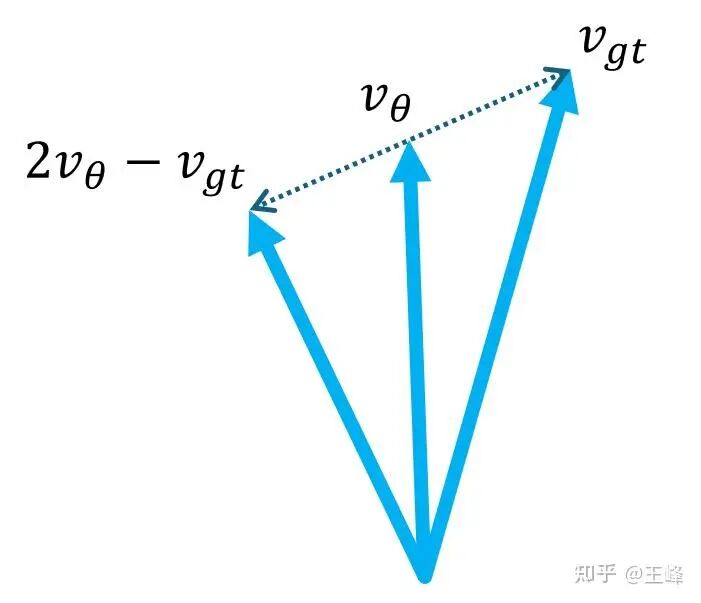
虽然AWM的论文中没有加入PPO clip,但我实际实验下来,还是需要套上的,否则优化一会就会剧烈抖动甚至直接归0。

03 DiffusionNFT
DiffusionNFT与AWM的主要区别是它是一个off-policy的方法,它会用滑动平均维护一个old model:
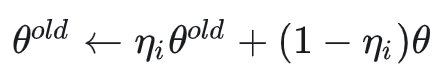
采样和梯度计算都在这个old model上进行,这样的好处是训练会更加稳定,但缺点是在old model上计算的梯度方向终归与new model不那么匹配,所以优化速度会慢。
DiffusionNFT的motivation和推导过程请参见原论文,这里只列出其最终的损失函数:
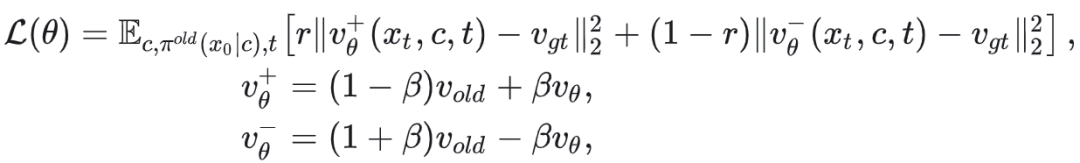
这里的 在实际工程中一般取1即可,r其实跟advantage很类似,只是它被归一化到了[0,1]范围,而advantage一般是零均值的,在实际应用中它们之间的关系可以表达为:A=2r-1。
为了简化推导,我们定义old和gt之间的差距为 ,定义new和old之间的差距为 ,这样上边的loss可以化简为:
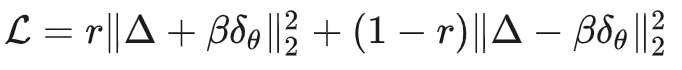
下面求一下梯度(注意到 ,而 里不含 ):

一番推导下来,可以看到这里有两项梯度,其中第一项跟AWM的形式很类似,起到指定优化方向的作用,而第二项起到了trust region的作用,熟悉RL历史的朋友会一下子想起来TRPO[5],而PPO clip[6]实际上是TRPO的一个改进,都是起到拉住模型不要崩溃的作用。也是因为这里有一个类似trust region的约束项,所以DiffusionNFT并不需要使用PPO clip即可让优化稳定进行下去。
进一步推导:
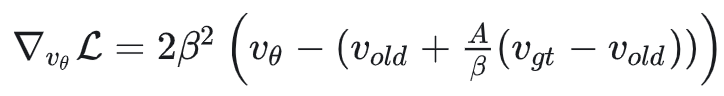
所以DiffusionNFT的等效loss可以写成:
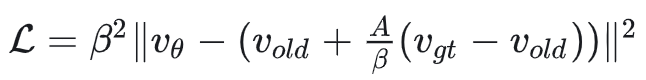
也就是说,它的优化目标为 ,与AWM对比,其实就是将 更换为 ,即使用off-policy的old model来计算优化目标,old model因为是moving average更新的,所以它更加稳定。
ps:回头看Flow-GRPO(非GRPO-Guard)的梯度中,也有一项 ,但因为前边有一个A的存在,而A有正有负,所以不能认为它也起到了trust region的作用。
04 网络输入
除了梯度和old model的更新方式上的区别之外,这几个算法还有一个区别是它们的输入 。Flow-GRPO使用的是采样过程中产生的 ,而AWM和DiffusionNFT使用的是重新加噪的 。在DiffusionNFT论文中,将重新加噪的过程定义为Forward过程,而采样过程中的 定义为Backward过程中得到的。这里还是用那张经典的flow matching训练-测试区别的图来解释一下:
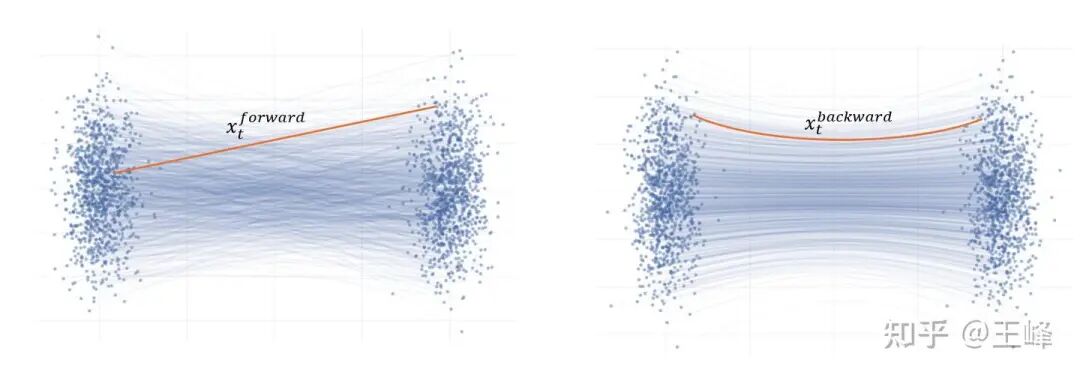
使用Forward 有两个好处:1. 它不依赖于特定的采样算法,可以随意更换一阶、二阶、ODE、SDE,甚至可以把真实图像塞进去都能优化。2. 它与Diffusion/FM的训练过程更加贴近,虽然数学上可以证明conditional和marginal等效,但那说的是固定输入时的网络输出等价,在网络输入 也变化的情况下,数学上就不再等价了。实测下来确实使用Forward效果会好一些。
但用Forward 也还是有一个缺点:因为 是训练时重新加噪产生的,所以需要在训练过程中重新走一遍old model才能获得 ,会多消耗一些算力,并且在rollout阶段之后不能放掉old model的参数,好在现在一般都是用lora来实现ref、old、new的参数加载,还算比较方便。
05 总结
最后,我列了一个表格对三个方法进行总结:

可以看到三个方法的优化目标其实都还是挺容易理解的,尤其是AWM和DiffusionNFT的区别几乎只在于on-policy或是off-policy。目前就我自己的实验来看,AWM优化速度快、效果好但没那么稳定,需要搭配PPO clip并且需要一定的调参技巧,DiffusionNFT略慢但优化稳定,迁移到其他算法时,基本上只需要调一调ema的参数。实际使用中,根据自己的需求进行选择即可。
参考文献
[1] Flow-GRPO: Training Flow Matching Models via Online RLFlow-GRPO: Training Flow Matching Models via Online RL
[2] Advantage Weighted Matching: Aligning RL with Pretraining in Diffusion ModelsAdvantage Weighted Matching: Aligning RL with Pretraining in Diffusion Models
[3] DiffusionNFT: Online Diffusion Reinforcement with Forward ProcessDiffusionNFT: Online Diffusion Reinforcement with Forward Process
[4] GRPO-Guard: Mitigating Implicit Over-Optimization in Flow Matching via Regulated ClippingGRPO-Guard: Mitigating Implicit Over-Optimization in Flow Matching via Regulated Clipping
[5] Trust Region Policy OptimizationTrust Region Policy Optimization
[6] Proximal Policy Optimization










