绑定手机号
确认绑定









智猩猩AI整理
编辑:宁宁
视觉语言模型这两年进步很快,但推理效率始终是落地中的核心瓶颈。主流 VLM 仍采用自回归解码,一次只生成一个 token,在长回答、多步推理、实时交互等场景下延迟高、吞吐低。尤其在机器人、自动驾驶、具身智能等 Physical AI 场景中,单请求在线推理往往受限于内存带宽,很难真正发挥 GPU 的并行能力。
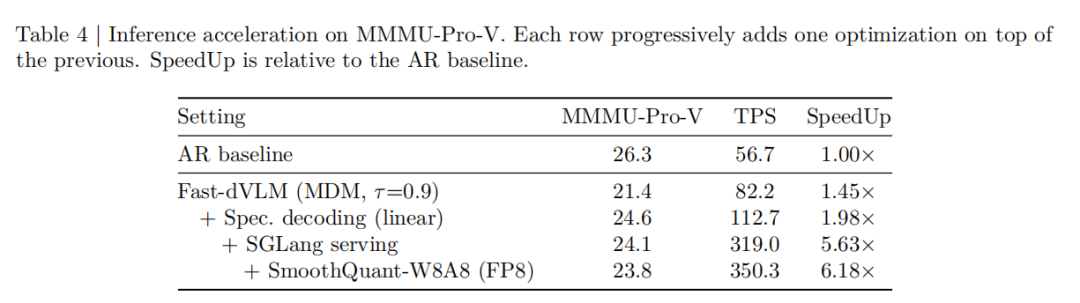
针对这一问题,MIT韩松团队联合港大、英伟达等提出了 Fast-dVLM,可由预训练自回归视觉语言模型直接转换得到的 block-diffusion VLM。该方法通过按块并行生成并结合 self-speculative decoding,在尽量保持原有生成质量的同时显著提升推理效率。研究团队不仅提出了 Fast-dVLM,还系统比较了两条 AR→Diffusion 路径。结果表明,在相近训练预算下,直接从预训练 AR VLM 出发的 direct path 明显比“先做文本 diffusion、再进行多模态微调”的 two-stage 路线更高效。实验结果显示,在短答案任务上,Fast-dVLM 在 speculative decoding 设置下可将平均成绩提升至与 AR 基线相同的 74.0,同时把 Tokens/NFE 提升到 2.63×;而在 MMMU-Pro-V 上,进一步结合 SGLang serving 与 SmoothQuant-W8A8(FP8)量化后,端到端吞吐最高可达到 AR baseline 的 6.18×。但需要注意的是,这一最高加速对应的精度为 23.8,仍略低于 AR 基线的 26.3。

论文标题:Fast-dVLM: Efficient Block-Diffusion VLM via Direct Conversion from Autoregressive VLM
论文链接:https://arxiv.org/pdf/2604.06832v1
GitHub 仓库地址:https://github.com/NVlabs/Fast-dLLM
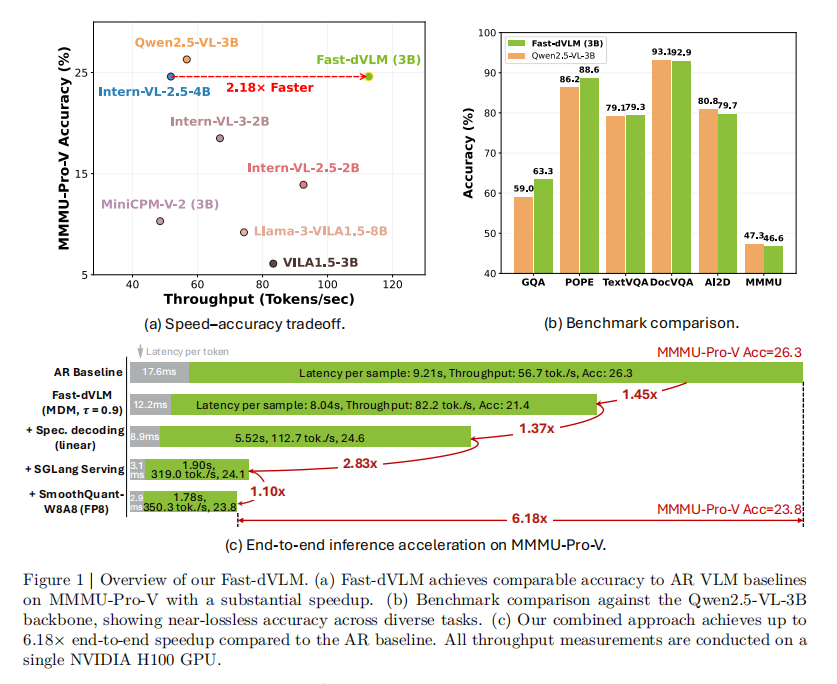
Fast-dVLM 的核心思想,是把 VLM 的逐 token 自回归生成改造成按 block 并行去噪生成。但研究团队并没有简单照搬文本扩散模型,而是针对多模态场景重新设计了训练与推理流程。
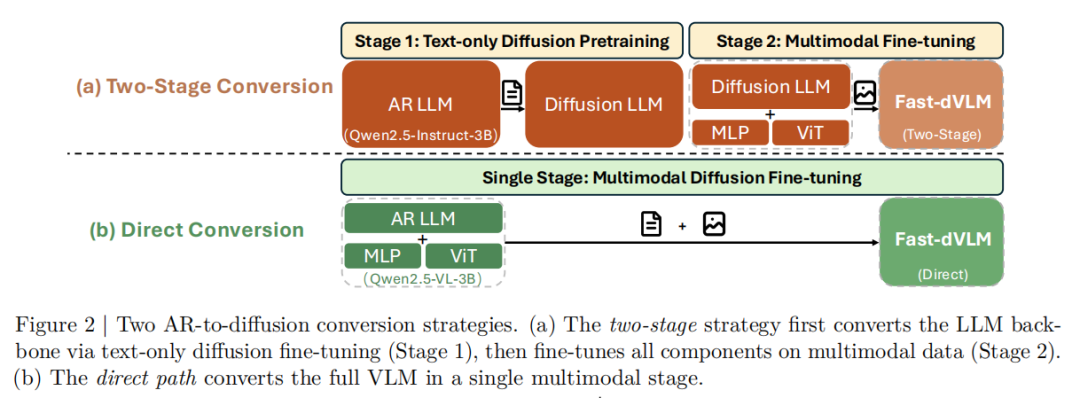
研究团队首先比较了两种转换策略,如图2所示。
(i)Two-stage 路线先把文本 LLM 变成 diffusion LLM,再接入视觉模块做多模态微调;
(ii)Direct path 则直接从已经完成多模态预训练的 AR VLM 出发,在单阶段多模态训练中完成扩散化。
研究发现direct path 更能保留原始 VLM 已经学到的视觉—语言对齐能力,因此在相同预算下更有效。
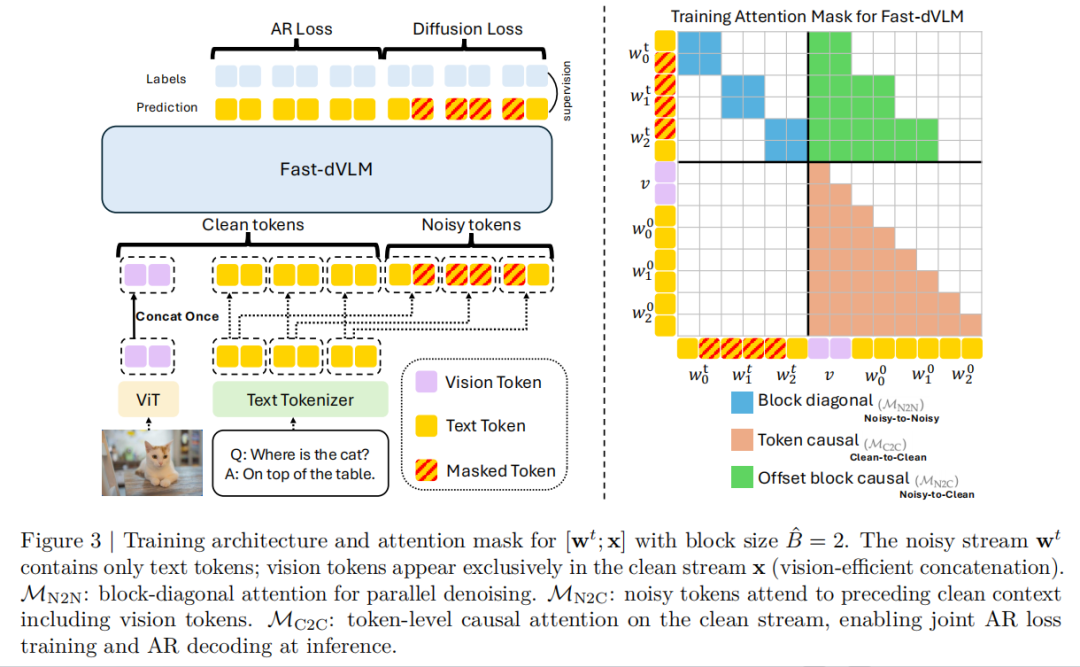
在训练架构上,Fast-dVLM 将输入分成 clean stream 和 noisy stream:只对响应文本 token 加噪,视觉 token 不扰动。围绕这一结构研究团队设计了三类注意力关系:
(i)noisy block 内部双向注意力,用于并行去噪;
(ii)noisy token 可看到前面的 clean 上下文,包括视觉 token;
(iii)clean stream 保留因果注意力,以继承 AR 模型原有的顺序建模能力。
为让这套结构真正适配 VLM,研究团队又提出了四个关键技巧:causal context attention、block-size annealing、auto-truncation masking、vision-efficient concatenation。其中vision-efficient concatenation 只在 clean stream 中保留视觉 token,避免冗余复制,在不损失效果的前提下将峰值显存降低 15.0%,训练时间缩短 14.2%。训练目标则采用 diffusion loss 与 causal LM loss 联合优化,使模型既具备并行去噪能力,又保留 AR 生成能力。
推理阶段,Fast-dVLM 采用 block-by-block 解码,并引入 self-speculative decoding:由 diffusion 模式先草拟一段 token,再由 causal 模式验证并接受最长匹配前缀。研究团队将系统接入 SGLang,并结合 SmoothQuant 的 FP8/W8A8 量化,实现更接近实际部署的系统级加速。
实验中,研究团队从 Qwen2.5-VL-3B 初始化模型,采用 direct path 完成转换,目标 block size 设为 32,并在 11 个多模态任务上进行评测。吞吐测试在单张 H100、batch size=1 的条件下完成,这一设定与真实在线服务场景较为一致。
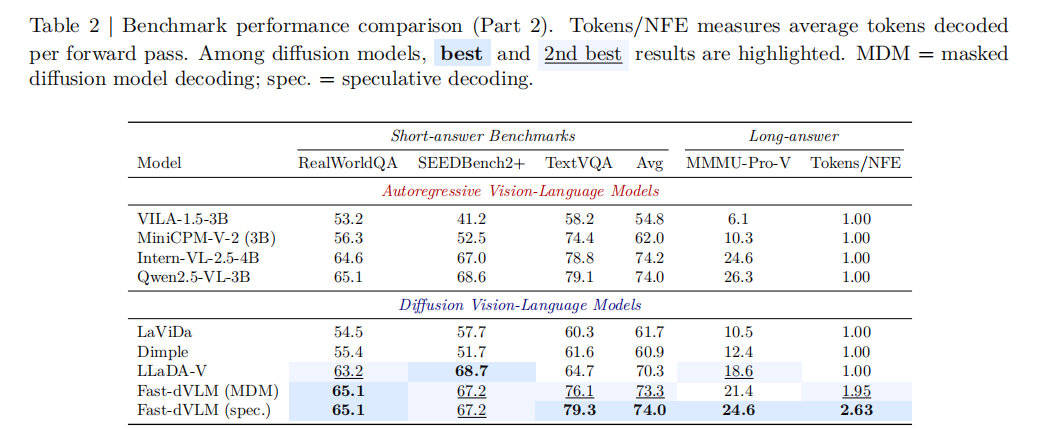
结果显示,在短答案任务上,Fast-dVLM 表现非常突出,如表2所示。使用 MDM decoding 时,平均分为 73.3,而 AR baseline 为 74.0,仅差 0.7 分,但 Tokens/NFE 达到 1.95×;换成 speculative decoding 后,平均分提升到 74.0,与 AR 基线完全持平,同时 Tokens/NFE 达到 2.63×。此外,Fast-dVLM 在 11 个短答案 benchmark 中有 8 个取得 diffusion VLM 最优结果,说明它已经相当接近“无损加速”。
如表2和图1(a)所示,在长链推理任务 MMMU-Pro-V 上,AR baseline 得分 26.3,Fast-dVLM 的 MDM 解码得分 21.4,仍有明显差距;但 speculative decoding 可将成绩提升到 24.6,仅落后 1.7 分。研究团队认为长链 reasoning 更依赖严格的序列一致性,因此块级并行生成仍有天然挑战,但结果已经证明该路线具备继续逼近 AR 的潜力。
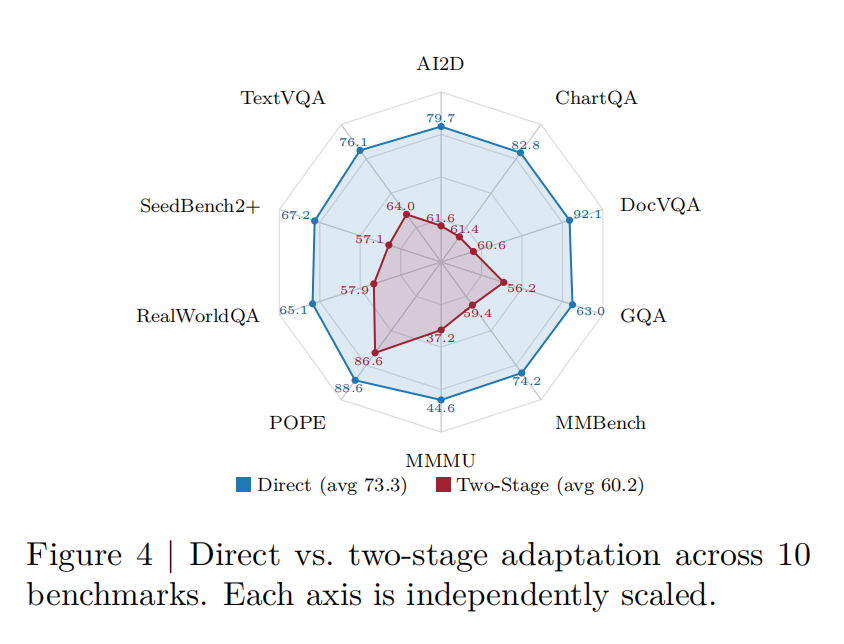
全文最关键的一组实验,是 direct path 与 two-stage path 的正面对比,如图4所示。结果显示,direct path 平均分为 73.3,而 two-stage 仅为 60.2,并且前者在 10 个 benchmark 上全部领先,在 DocVQA、ChartQA、AI2D 等知识和推理更密集的任务上优势尤其明显。这说明,对于已经完成预训练的 AR VLM,直接从完整 VLM 出发进行扩散化,能够更充分地继承其已有的多模态对齐能力,因此在相同训练预算下比 two-stage 路线更高效。研究团队也据此将 direct path 作为默认推荐方案。
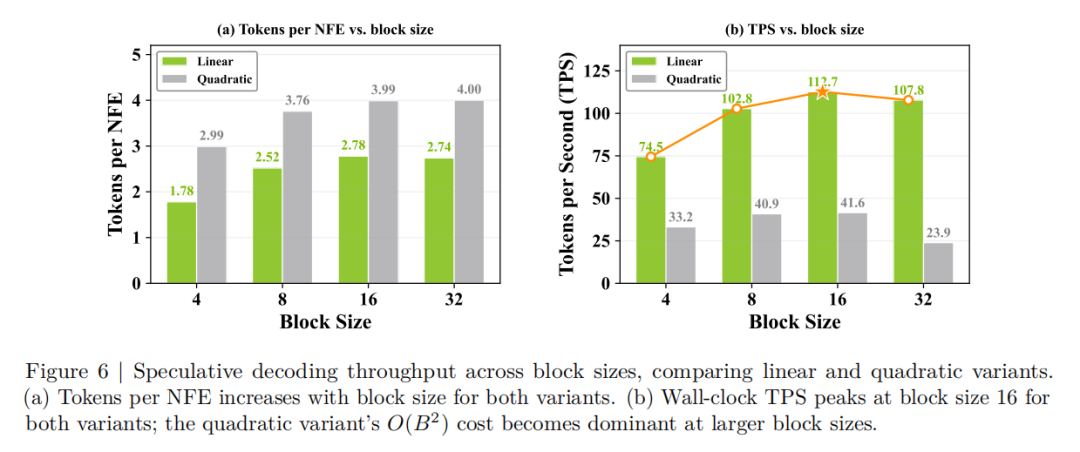
消融实验也验证了各组件的重要性,如表4,图6所示:去掉 causal context attention 后,平均精度下降 22.5%;去掉 block-size annealing 后,平均分下降 4.4%;去掉 auto-truncation 后,平均分下降 3.7%。这说明 Fast-dVLM 的提升并不是单一技巧带来的,而是整套训练与推理设计共同作用的结果。
Fast-dVLM 的价值,不只是“把 VLM 做快了”,而是更进一步回答了一个方法论问题:如果已经拥有高质量 AR VLM,怎样才能以更直接、训练效率更高的方式,把它转换成高吞吐的扩散式 VLM?论文给出的答案是:直接从预训练好的 AR VLM 出发,尽可能保留其多模态对齐能力与因果建模能力,再通过 block diffusion 和 self-speculative decoding 换取并行生成效率。
从结果看,这条路线已经相当有说服力:在短答案任务上,Fast-dVLM 几乎实现了与 AR 基线持平的效果,同时显著提升了解码效率;在长链推理任务上,它也通过 speculative decoding 明显缩小了与 AR 的差距;进一步结合 SGLang 与 FP8 量化后,系统层面则实现了超过 6× 的端到端提速。










