绑定手机号
确认绑定









智猩猩AI整理
编辑:没方
当下 AI Agent赛道火热,以 OpenClaw 为代表的本地部署框架迅速走红,成为现象级开源项目。但传统面向大模型的强化学习系统,依赖中心化批量训练和预先标注数据集,训练流程繁琐、无法实时响应对话反馈,难以真正贴合用户个性化需求。
为此,普林斯顿大学王梦迪团队提出专为 OpenClaw 打造的全异步强化学习框架OpenClaw-RL,能够把日常对话直接转化为训练信号,让自托管模型在不中断服务的前提下持续进化,实现越用越聪明。

论文标题:OpenClaw-RL: Train Any Agent Simply by Talking
论文链接:https://arxiv.org/pdf/2603.10165
项目地址:https://github.com/Gen-Verse/OpenClaw-RL
01 方法
研究团队指出,每次智能体(agent)交互都会产生一个“下一状态”信号,无论是用户回复、执行结果、测试判定还是图形界面(GUI)状态转换,“下一状态”信号都编码了关于前序动作的评估性和指导性信息。
评估性信号:指示动作执行得有多好,这些信号通过一个过程奖励模型(PRM)裁判提取为标量奖励。
指导性信号:指示动作本应如何不同,这些信号通过基于提示的在线策略蒸馏(Hindsight-Guided On-Policy Distillation, OPD)技术恢复。
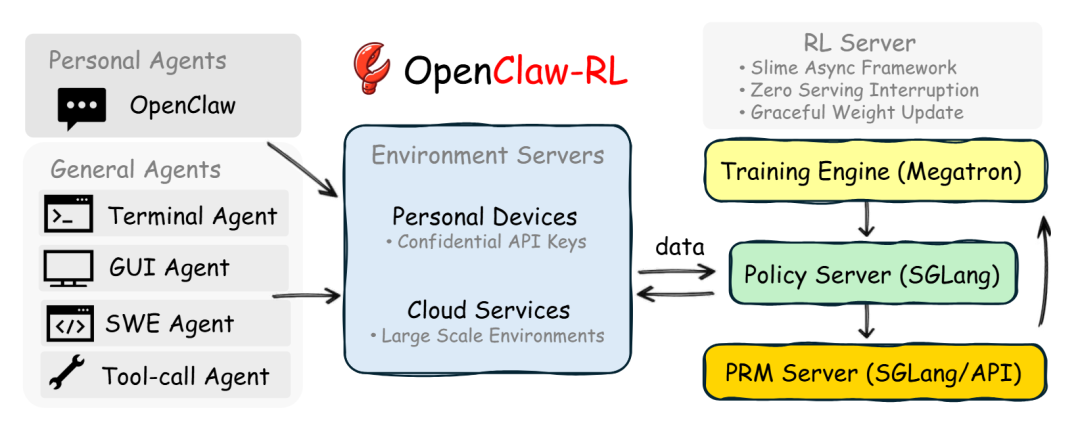
OpenClaw-RL 基于 slime 构建,能够让 AI 正常服务用户的同时,后台有四个完全解耦的模块在异步运转:策略服务、轨迹收集、过程奖励评估与参数训练,彼此互不阻塞(如上图所示)。
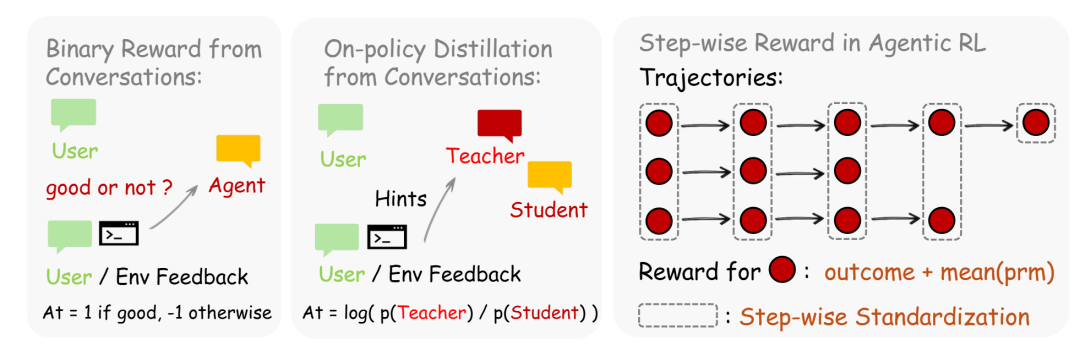
如上图所示,在个人智能体应用中,OpenClaw-RL 能够让模型通过日常使用过程中的自然交互信号进行在线、持续的策略优化,这一机制极大地拓展了现有强化学习基础设施。研究团队提供了两种优化选项:
二元强化学习(Binary RL):利用 PRM 将对话恢复为标量过程奖励。
基于提示的在线策略蒸馏(OPD):从下一状态中提取文本提示,构建增强的教师上下文,并将 token 级的方向性监督蒸馏回学生模型,从而提供仅靠标量奖励无法获得的训练信号。
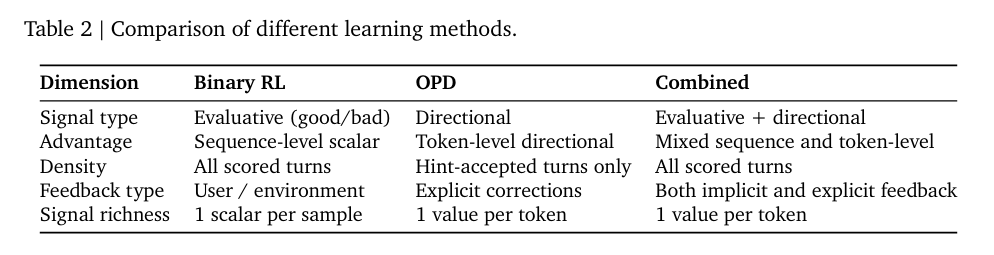
二元强化学习和OPD方法是互补而非竞争关系。通过二元强化学习在所有轮次上提供广泛的梯度覆盖,而OPD则在那些可获得指导性信号的轮次子集上,提供高分辨率的、逐token的修正。
因此,研究团队通过加权损失函数来结合这两种互补方法。它们共享相同的PPO损失,只是优势函数的计算不同。因此,可以直接使用以下优势:
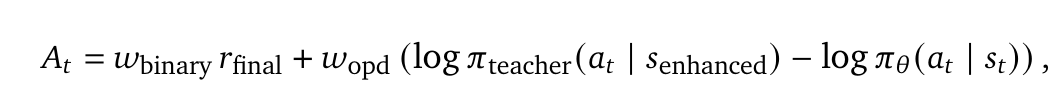
针对通用智能体的强化学习,除了标准的 RLVR外还提供了集成的逐步奖励(Step-wise Reward)机制,通过简单相加来整合结果奖励和过程奖励。
与 GRPO 不同,逐步奖励的存在使得优势函数的计算变得不那么直接。终端智能体的状态并不容易被聚类。因此,研究团队直接将具有相同步骤索引的动作进行分组,这种方法非常有效。
02 评估
(1)智能体设置
①个人智能体设置
使用 OpenClaw 做作业的学生(不希望被发现使用了 AI)
在此场景中,LLM模拟一名学生:该学生在个人电脑上使用 OpenClaw 完成作业,同时试图避免被认为依赖 AI。回答是否像 AI 生成,完全取决于该学生的个人偏好和写作风格。学生与 OpenClaw 持续互动并寻求作业帮助。作业任务选自 GSM8K 数据集。此场景中使用的 OpenClaw 策略模型为 Qwen3-4B 。将学习率设为 1×10−5,KL 散度系数设为 0,并在每收集到 16 个训练样本后触发训练。
使用 OpenClaw 批改作业的教师(希望评语具体且友好)
在学生完成文件中的作业后,教师也使用 OpenClaw 来批改这些由 AI 完成的作业。教师希望给学生的评语既具体又友好。OpenClaw 策略模型同样采用 Qwen3-4B,并使用相同的优化设置。
②通用智能体设置
模型
在终端、GUI、SWE(软件工程)和工具调用场景中,分别使用Qwen3-8B 、Qwen3VL-8B-Thinking 、Qwen3-32B 以及 Qwen3-4B-SFT。用于 GUI 和工具调用智能体的过程奖励模型分别是 Qwen3VL-8B-Thinking 和 Qwen3-4B。
数据集
分别使用 SETA RL 数据、OSWorld-Verified、SWE-Bench-Verified 以及 DAPO RL 数据来训练终端、GUI、SWE 和工具调用智能体。
(2)个人智能体评估
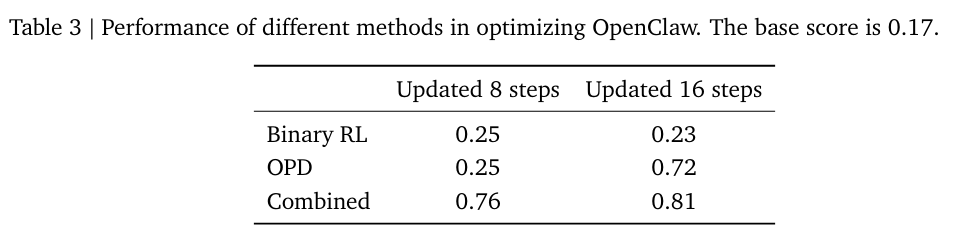
如上表所示,组合方法实现了最有效的优化。虽然在线蒸馏的表现优于二元强化学习,但由于训练样本的稀疏性,其效果显现需要更长的时间。

如上图所示,在组合优化方法下,OpenClaw 仅需在学生设置中进行 36 次解题交互,以及在教师设置中进行 24 次评分交互,即可实现明显的性能提升。
(3)通用智能体评估
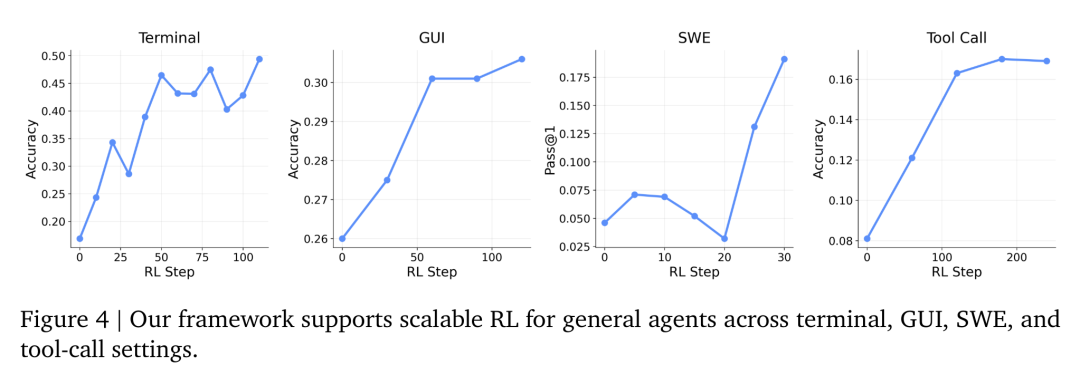
如图4所示,研究团队的框架能够处理多样化的真实世界场景,包括终端、图形界面(GUI)、软件工程(SWE)以及工具调用智能体,并能在不同模型规模和模态下实现大规模的环境并行化。
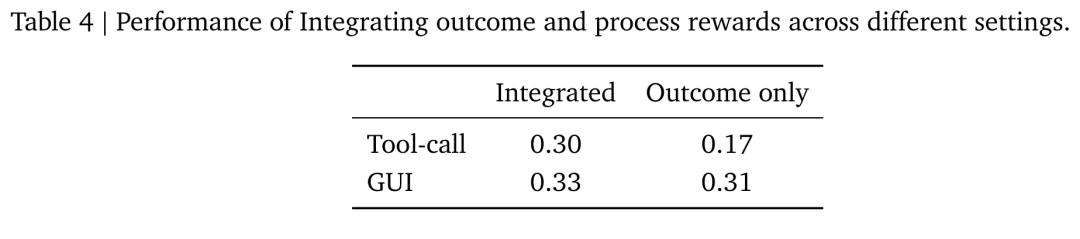
研究团队在工具调用(250 步)和图形界面(120 步)场景中进行了集成奖励的强化学习训练,可以发现将结果奖励与过程奖励相结合能进一步提升性能(如表 4)。但与仅基于结果的优化相比,部署过程奖励模型需要额外的计算资源。










