绑定手机号
确认绑定









智猩猩AI整理
编辑:没方
Agentic AI 正在成为人工智能领域最具变革性的研究方向之一。这类具备自主规划能力、能够灵活调用工具并与环境持续交互的智能体,正从早期的实验室原型逐步走向复杂真实场景中的规模化应用(如Claude Code与OpenClaw),其核心特征也从“回答生成”转向“驱动决策与行动”。在这一范式演进背后,Agentic RL正逐渐成为关键技术支柱。不同于传统的 RLHF,Agentic RL 强调在多轮交互环境中,通过可验证反馈与序列决策优化,让大语言模型(LLM)具备持续决策、动态规划与自我修正的能力,从而真正支撑复杂任务中的长期推理与执行。
在这一背景下,中国科学技术大学认知智能全国重点实验室率于2025年年初开源发布了 Agent-R1 训练框架。近期,Agent-R1 正式迎来 v2 版本的重要升级,目前项目在 GitHub 上的 Star 数已突破 1300+。相较于首代版本,Agent-R1 v2 在底层系统架构、Trajectory 表示机制以及多轮训练策略等方面实现了系统性重构,不仅提升了复杂任务下的稳定性与训练效率,也显著增强了智能体在开放环境中的泛化能力与鲁棒性,进一步推动 Agentic RL 从研究探索走向可落地的工程实践。

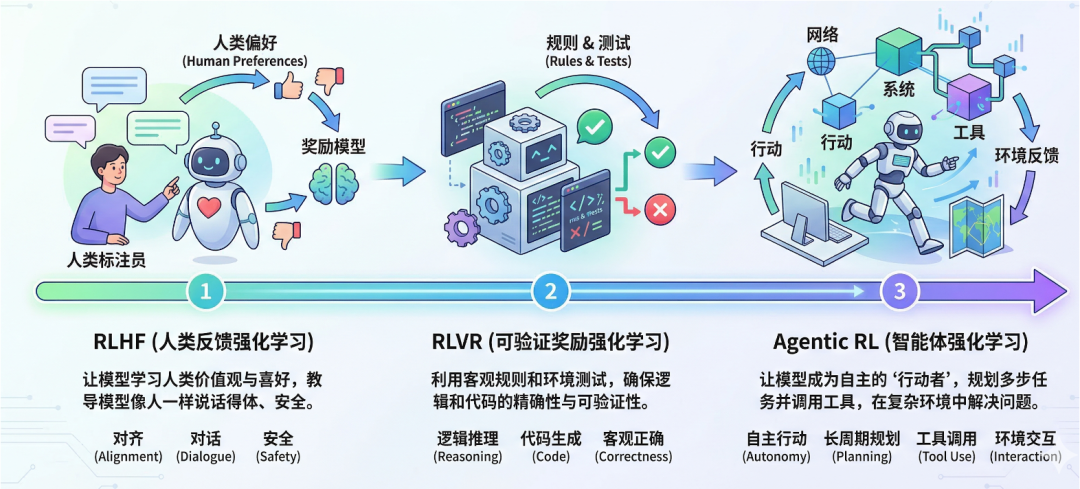
近年来,强化学习与大语言模型的结合正快速演进,并逐步形成一条从“对齐”到“推理”再到“行动”的清晰技术路径:
第一代:RLHF(Reinforcement Learning from Human Feedback) 以 InstructGPT、ChatGPT 为代表。这一阶段的核心在于利用人类反馈对模型进行行为对齐:通过人工标注偏好数据,训练奖励模型,再借助 PPO 等方法优化模型输出,使其在表达上更加符合人类价值与安全规范。然而,这类方法高度依赖人工信号,成本较高,且奖励往往具有主观性与模糊性,因此在数学推理、程序生成等需要客观正确性的任务上存在一定局限。
第二代:RLVR(Reinforcement Learning with Verifiable Rewards) 以 DeepSeek-R1 等工作为代表。该阶段的重要转变在于引入可验证的客观奖励机制,如代码是否成功执行、数学结果是否正确等,从而摆脱对人工打分的依赖。这一范式显著提升了模型在逻辑推理与结构化任务中的表现,并促进了长链推理(Long Chain-of-Thought)的涌现。不过,这类方法仍主要聚焦于“单体推理”,模型多在封闭环境中进行推断,与外部环境的动态交互相对有限。
第三代:Agentic RL(Agent-oriented Reinforcement Learning) 这是当前正在兴起的前沿方向,也是 Agent-R1 所聚焦的核心范式。在这一阶段,大模型从“文本生成器”转变为“任务执行者”:不仅能够生成内容,还可以主动调用工具、感知环境反馈、调整决策策略,并在多轮交互中逐步完成复杂任务。其奖励信号直接来源于任务完成情况,状态空间扩展为“上下文 + 环境”,动作空间也由“token 生成”拓展为“工具调用与行动决策”,从而更贴近真实世界中的决策过程。
从整体来看,这三代技术演进反映出强化学习在大模型中的作用不断深化:从最初的行为对齐(Alignment),到强调推理能力(Reasoning),再到迈向决策与行动(Action),逐步推动大模型从“会说话”走向“能做事”。
1、从 R1 到 Agent-R1
DeepSeek-R1 通过长链思维(CoT)解决逻辑复杂问题,本质是一种静态的内生推导——模型只在自己的"脑袋里"想,不与外界互动。
Agent-R1 引入了 Agentic RL 范式,核心在于三点升级:
| 维度 | R1(推理模型) | Agent-R1(智能体) |
| 奖励来源 | 数学/逻辑一致性 | 任务达成率 |
| 动作空间 | 文本 Token 生成 | 文本 + 外部工具指令调用 |
| 状态空间 | 上下文 Context | 上下文 + 环境实时反馈 |
2、Agent-R1框架概览
Agent-R1 将传统单轮 RL 训练框架扩展为支持多轮交互 Rollout 的完整系统, 核心由 Tool 与 ToolEnv 两个模块构成。
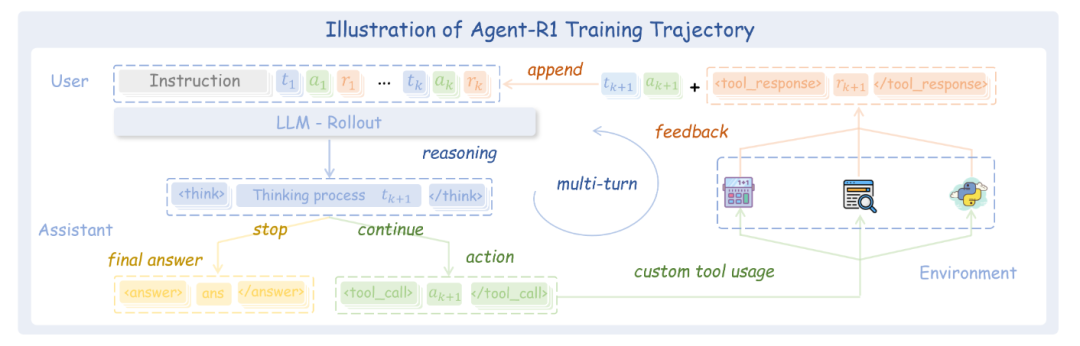
Agent-R1 训练轨迹示意图
如上图所示,Agent 在 Rollout 阶段进行多轮推理与工具调用,接收环境反馈,最终用完整轨迹进行 RL 更新。
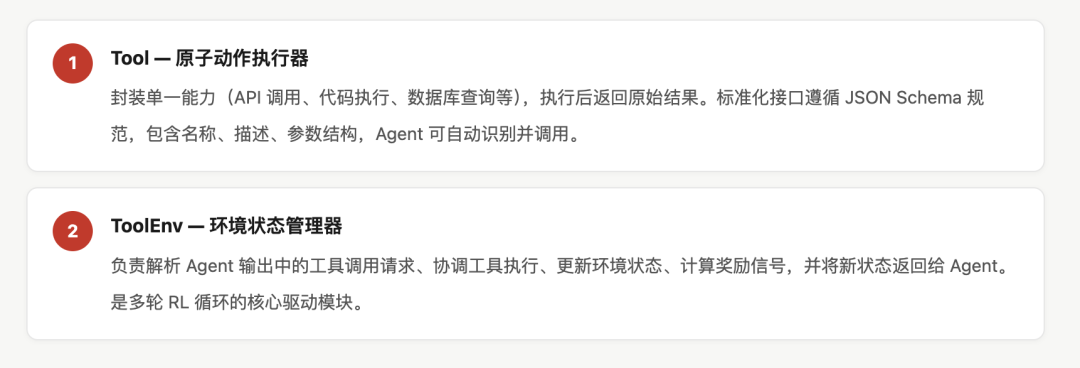
Agent-R1 的训练后端设计极为简洁,背后藏着一个重要洞见:无论是单轮问答,还是跨越数十步的"思考-工具-反馈"多轮交互,在训练层面都只是一条 Token 序列。具体而言:
这意味着 RL 训练的复杂性被完全封装在 Advantages 的计算中,训练后端本身无需感知智能体的多轮交互逻辑,从而实现了采样与训练的彻底解耦。
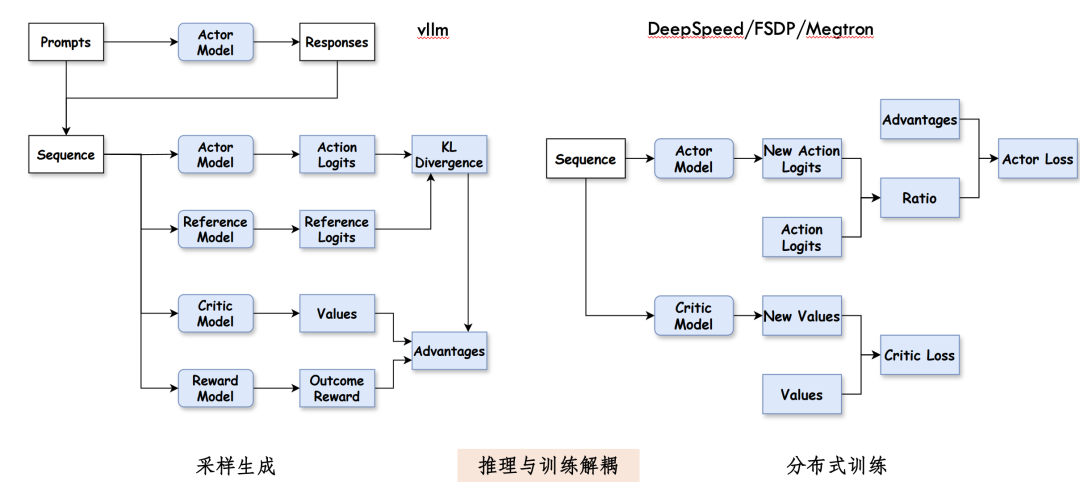
Agent-R1 采用业界成熟的分布式训练链路,将采样生成与梯度更新彻底解耦:
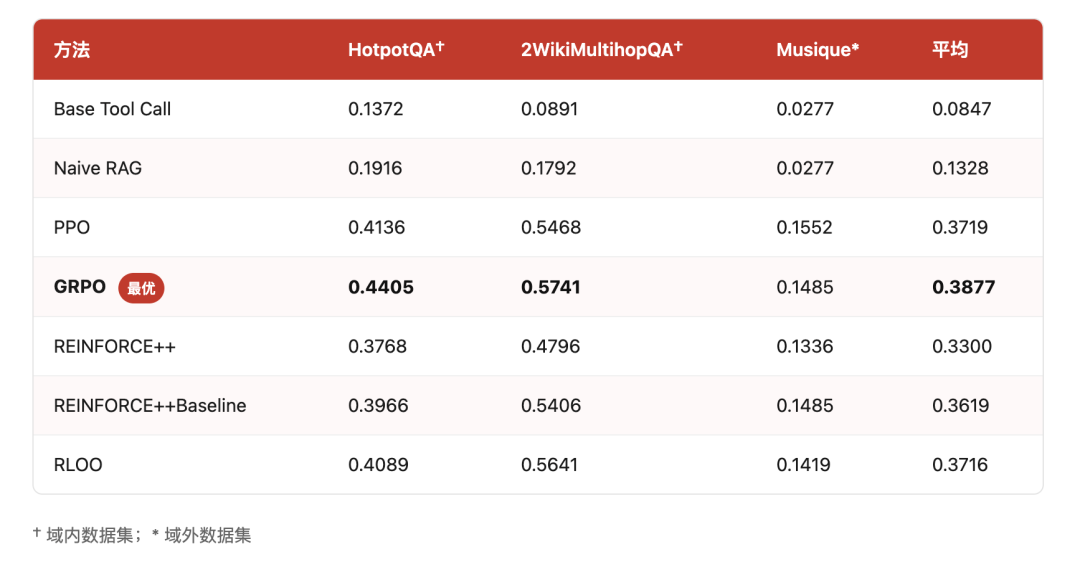
所有 RL 训练方法均大幅超越基线:最弱的 RL 算法(REINFORCE++,平均 EM 0.33) 仍比 Naive RAG(0.13)高出约 2.5 倍。GRPO 综合表现最优, PPO 在域外 Musique 数据集上表现突出,展现了良好的泛化能力。
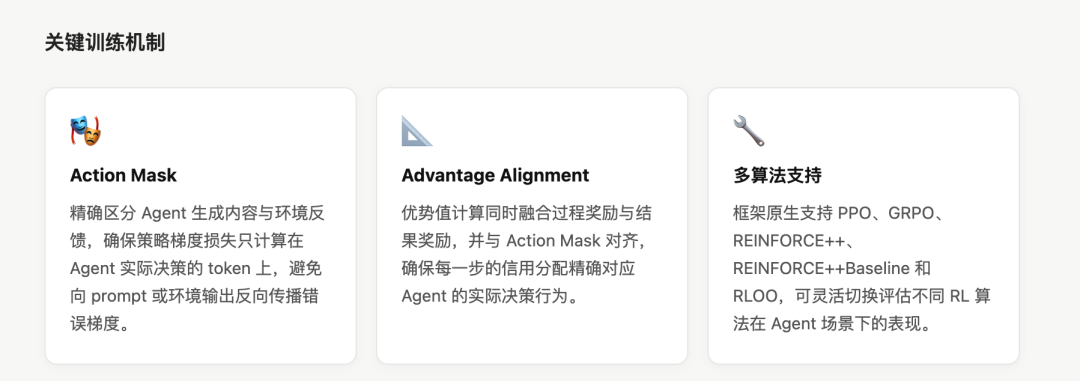
消融实验证明 Action Mask(用于损失计算与优势对齐) 是 Agent-R1 框架中最关键的设计之一。 去掉 loss mask 或 advantage mask 均会导致性能显著下降, 说明精确的信用分配对多轮 Agent 训练至关重要。

Step-level MDP:多轮任务的正确建模方式
传统单轮 RL 将任务退化为多臂赌博机问题,无真实中间状态转移。Agent-R1 v2 提出 Step-level MDP,恢复了完整的序列决策特性:
这使得模型能从真正意义上学习"怎么做",而不仅仅是"说什么"。
Layered Abstractions:开发者友好的分层设计
v0.1.0 全面重构了代码库,引入分层抽象设计:

如何在多轮工具调用中准确收集训练轨迹,是 Agentic RL 的核心工程难题。Agent-R1 经历了三代方案的演进:
第一代:Messages
第二代:Token-In-Token-Out
第三代(v2 最新):Step-based Sequence
从 RLHF 到 RLVR,再到 Agentic RL,大模型强化学习的演进路径正逐步清晰:强化学习赋予大模型的,不仅是“更强的推理能力”,更是在真实环境中进行决策与行动的能力。
Agent-R1 v2 的发布,尝试在这一范式下迈出关键一步:通过 step-level MDP 重构多轮任务的建模方式,以 step-based sequence 缓解训练与推理不一致的问题,并通过分层抽象降低复杂 Agent 系统的研究与开发门槛。这些探索并非局限于单一框架优化,而是指向一个更普遍的问题——如何让大模型在开放环境中稳定地进行长程决策。
我们逐渐认识到,未来大模型能力的核心,不再只是“生成更好的答案”,而是完成真实世界中的复杂任务。在这一意义上,能够“做事”的智能体,或许将成为下一阶段人工智能最关键的研究方向之一。










