绑定手机号
确认绑定









智猩猩AI整理
编辑:汐汐
向量化模型(Embedding Model),是AI世界里那条“隐形纽带”——它把海量如文字、图片、视频等非结构化数据,转化为高维向量,让机器能“理解相似性”,从而驱动语义搜索、推荐系统、RAG(检索增强生成)等核心应用。
没有向量化模型,现代AI应用就如同“盲人摸象”,文本模型看不懂图片,视觉模型听不到声音,开发者不得不搭建繁琐的多模型管道、先转录再对齐,延迟高、准确率低、成本爆炸。过去几年,OpenAI的text-embedding-ada、Google旧版text-only向量化模型虽强,但面对真实世界的多模态数据时,始终卡在“碎片化”瓶颈上。
今天,谷歌直接打破天花板。Gemini Embedding 2正式公测!这是谷歌首个原生多模态向量化模型,基于Gemini架构,一次性把文本、图像、视频、音频、文档塞进同一个向量空间。复杂管道?直接砍掉。AI终于能像人类一样,“一眼看懂”多媒体世界的深层关系。

01 Gemini Embedding 2:谷歌AI向量化模型的SOTA级飞跃
3月11日,谷歌AI Studio官方账号在X平台重磅宣布,Gemini Embedding 2现已通过Gemini API和Vertex AI公测开放。
谷歌这个新版的向量化模型具备多个极其强大的更新功能。
首先,就是它具备真正原生多模态的统一空间。我们知道,谷歌的Gemini模型本身就是一个原生多模态的模型,而这次的向量化模型更新,更是让谷歌的AI在原生多模态这方面更上一层楼。
有了原生多模态的统一空间,大模型不再是“文本主导+其他模态补丁”,而是直接映射高达8192tokens上下文文本、单次请求最多6张PNG/JPEG格式图像、长达2分钟的MP4/MOV格式视频、无需任何转录的原生音频,以及最多可以映射6页PDF的文档到同一个向量化向量。支持交错输入(比如图片+文字一起喂),模型能精准捕捉跨模态的“微妙语义关联”。
另外,还有本次更新还有Matryoshka Representation Learning(MRL)加持,默认具备3072维度,支持灵活缩放到1536、768甚至更低维,允许开发者根据存储/性能需求自由裁剪,质量衰减很小,这完美平衡了企业级大规模部署的需求。
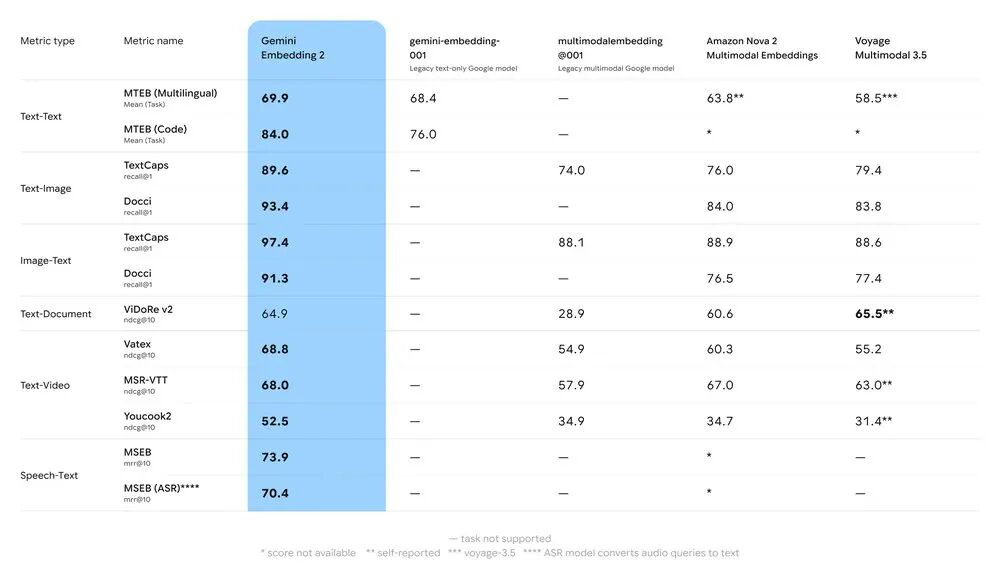
在实际表现上,Gemini Embbeding 2在文本、图像、视频任务上全面超越前代以及竞品,具备亮眼的SOTA级性能表现,尤其是其新增强劲的语音能力。谷歌自己直言:“这不是简单迭代,而是多模态深度的新标杆。”

同时,在生态上,它还能无缝对接LangChain、LlamaIndex、Haystack、Weaviate、QDrant、ChromaDB等主流向量数据库,还有官方Colab笔记本和轻量多模态语义搜索Demo。
官方发布中介绍,如下方式就能通过Gemini API或Vertex AI开始使用Gemini Embedding 2模型。
from google import genaifrom google.genai import types# For Vertex AI:# PROJECT_ID='<add_here>'# client = genai.Client(vertexai=True, project=PROJECT_ID, location='us-central1')client = genai.Client()with open("example.png", "rb") as f: image_bytes = f.read()with open("sample.mp3", "rb") as f: audio_bytes = f.read()# Embed text, image, and audio result = client.models.embed_content( model="gemini-embedding-2-preview", contents=[ "What is the meaning of life?", types.Part.from_bytes( data=image_bytes, mime_type="image/png", ), types.Part.from_bytes( data=audio_bytes, mime_type="audio/mpeg", ), ],)print(result.embeddings)总结来说,Gemini Embedding 2把“多模型拼凑”变成了“一个API调用”,开发者终于可以告别痛苦的管道工程。
02 所有应用都用同一语义层!数据管线团队直接变成了一个API
Gemini Embbeding 2模型发布的消息一出,海外社交媒体几乎可以说是瞬间刷屏,从谷歌内部人士、DeepMind研究者,到全球各地的开发者纷纷下场,直呼“游戏规则改变者”。
根据谷歌的介绍,已经有不少公司用上并给出了实际反馈。
例如法律科技公司Everlaw CTO Max Christoff称,“在数百万份诉讼记录中,Gemini多模态向量化显著提升精准率和召回率,还解锁了图像/视频的全新搜索功能。”

还有Sparkonomy联合创始人Guneet Singh表示,“延迟降低高达70%,文本-图像/视频语义相似度从0.4飙升至0.8,直接驱动创作者经济引擎。”

以及Mindlid联合创始人Ertuğrul Çavuşoğlu也表示,“top-1召回率提升20%,完美适配个人健康App的对话+音频+视觉记忆。”

AI自动化开发者@PostCorp表示,公司雇佣8个人的数据管线团队,现在直接变成了一个API调用了,整个部门被压缩成为了一个端点了!
有用户直指未来,称Agent需要长期跨模态记忆,而统一向量化模型就是其基础,让所有应用都用同一语义记忆层。
谷歌自家的高级经理,Github 10万Stars仓库作者Shubham Saboo直言不讳地表示,“是时候从头重构RAG和多模态AI Agent了。”
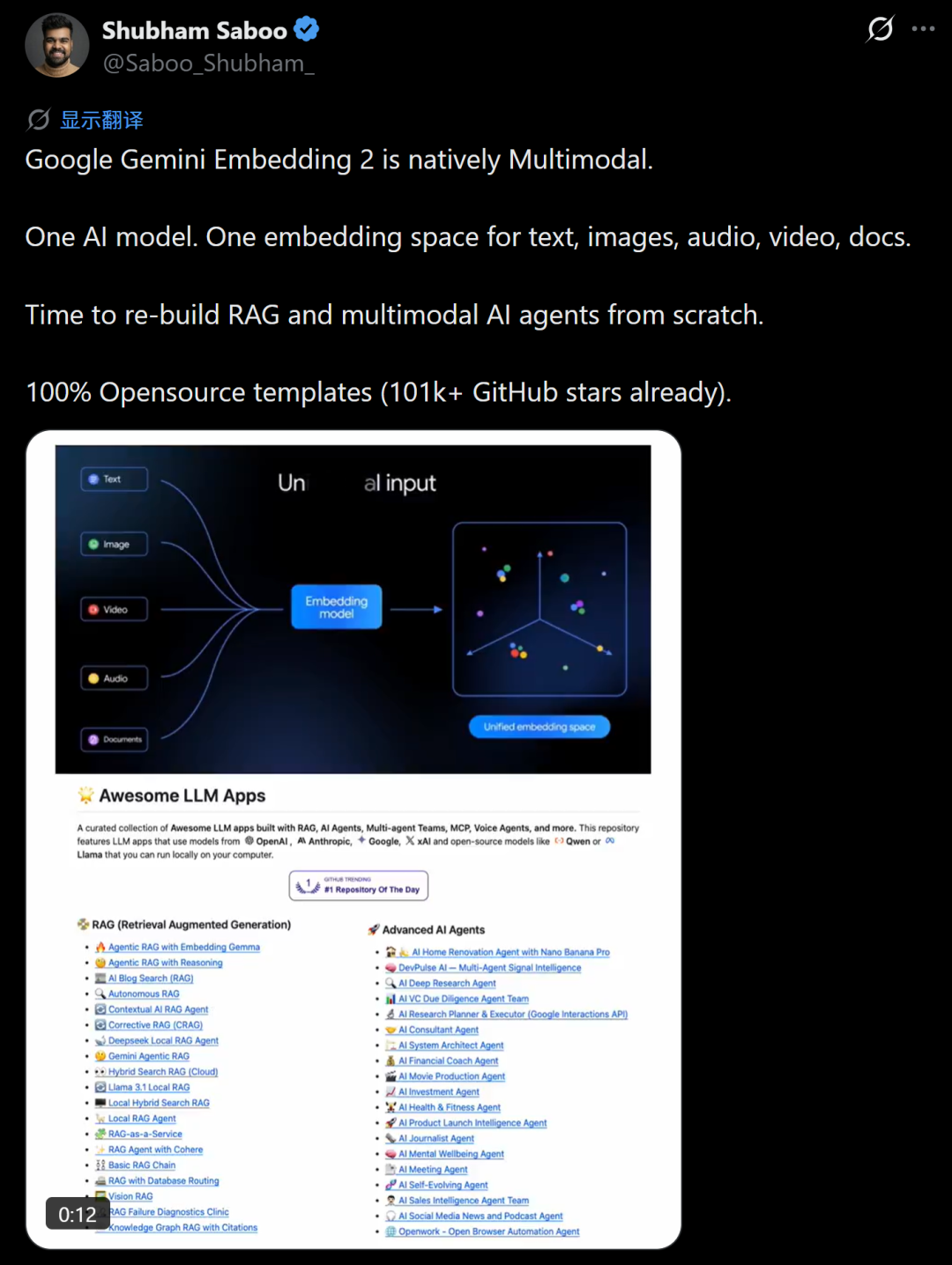
还有开发者称赞道,“多模态RAG和搜索管道的巨大飞跃!原生统一空间终于让真正跨模态检索生产就绪,不用再搞尴尬的独立编码器或后期融合了。”

这带来的最直接的影响就是,AI不再各个模态分裂地、碎片化地看世界,而是像你我这样的人类一样,能联系地看这个世界。
03 AI迈入多模态统一理解时代,奠定Agent跨模态大脑基础
Gemini Embedding 2的发布,标志着AI从“文本主导+其他模态配合”正式迈入多模态统一理解时代。
对行业而言,这是RAG和语义搜索的巨大变革,企业级多媒体知识库,例如合同+照片+视频证据+录音等可以一键检索,法律、医疗、电商、内容创作场景下使用AI的准确性与效率将会暴增。
对于开发者来说,开发难度和复杂度将会雪崩式下跌,再也不需要多个模型拼接、也不需要中间转录,中小企业也能玩转顶级多模态AI了。
而对更上一层的AI智能体而言,统一向量化空间将成为下一代Agent的“跨模态大脑”,实现真正持久的跨媒体记忆与推理。
更深远的意义在于,过去我们用不同模型来“翻译”不同的模态,而如今Gemini Embbeding 2让AI第一次以人类的视角来感知世界的声音、画面、文字等,这些是融为一体的,而不是割裂的。这或许会成为更通用的AI智能体的关键一步。










