绑定手机号
确认绑定









智猩猩AI整理
编辑:六六
当前的世界模型仅限于一次模拟单个智能体的观察。然而在我们这个根本上多智能体的世界中,需要能够模拟环境中所有智能体视角的视频世界模型,以捕获准确的世界状态。
为此,纽约大学谢赛宁研究团队提出了 Solaris 多智能体视频世界模型,可在《我的世界》(Minecraft)中模拟一致多人视角。其核心贡献包括 SolarisEngine 数据系统、大规模多人训练数据集、评估系统及多视角适配新架构;研究末期还引入内存优化的检查点自强制方法,实现更长时序的教师引导。
实验结果表明,本研究提出的架构与训练方法,性能显著优于现有基线模型。研究团队通过开源相关系统与模型,旨在为新一代多智能体世界模型的研发奠定坚实基础。

论文标题:Solaris:Building a Multiplayer Video World Model in Minecraft
论文链接:https://arxiv.org/pdf/2602.22208
官方网站:https://solaris-wm.github.io/
Github:https://github.com/solaris-wm/solaris
Huggingface:https://huggingface.co/collections/nyu-visionx/solaris-models
01 Solaris模型架构
模型的架构基于 Matrix Game 2.0 ,这是一个在包括 《我的世界》在内的多个视频游戏上训练的单智能体可控视频 DiT 模型。图 1 可视化了研究团队提出的多智能体DiT模块。
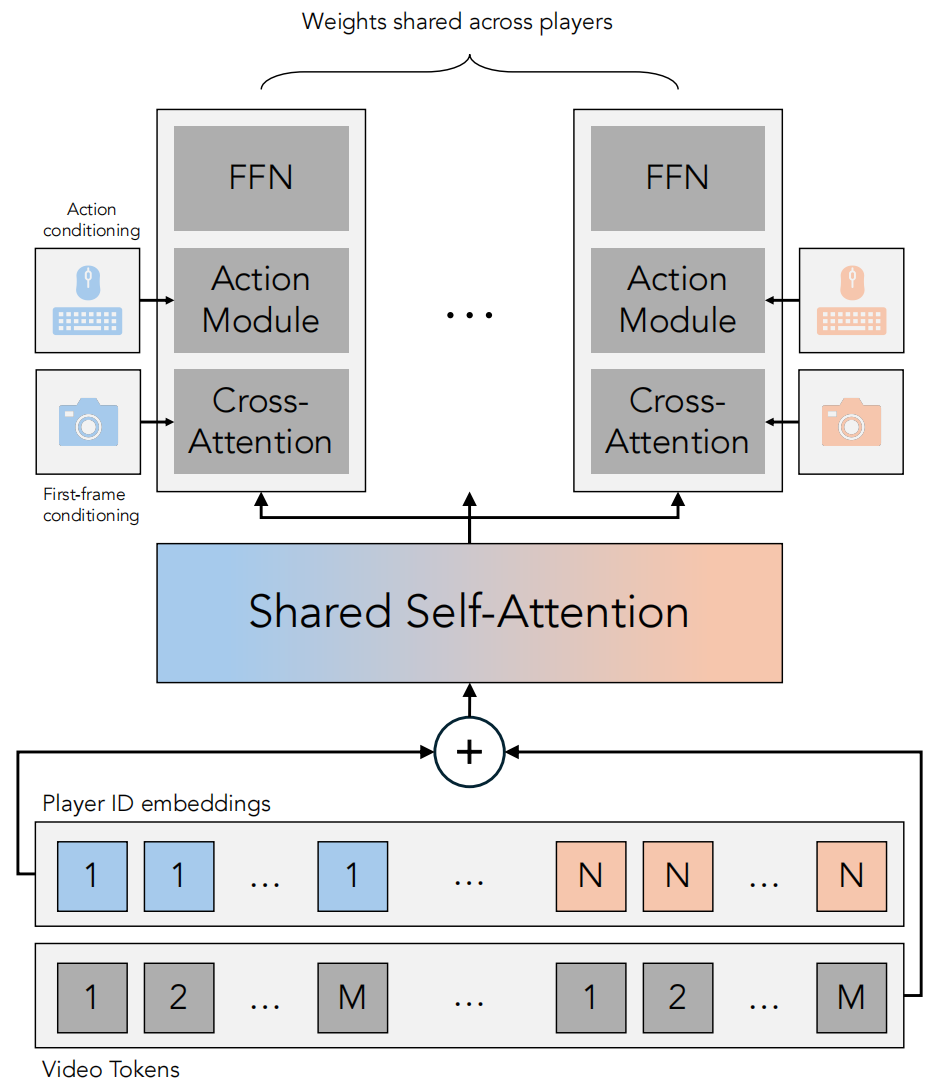
图 1 多智能体扩散变换器模块。
为将 Matrix Game 2.0 适配至多智能体建模场景,研究团队引入以下几处关键修改:
扩展的动作空间:增加 Matrix Game 2.0 键盘动作模块的输入维度并重新初始化其权重。动作模块按每个智能体独立运行,将智能体维度折叠到批次维度中。
多智能体注意力机制:不同智能体之间的信息通过在 DiT 模块中引入的多智能体自注意力层进行交换。模型对每个智能体的令牌独立应用3D旋转位置编码(RoPE),并在每个多智能体自注意力层的起始处,通过向每个智能体的令牌添加可学习的智能体 ID 嵌入来注入智能体身份信息。
02 SolarisEngine数据收集框架
为系统性地采集预编程的多人在线《我的世界》游戏数据,研究团队构建了SolarisEngine 框架,如图 2 所示。该框架通过基础技能库、多人通信层与模块化情节系统,实现数百万帧数据的自动化采集,并为视觉-语言-动作模型及AI协作测试提供基础支撑。
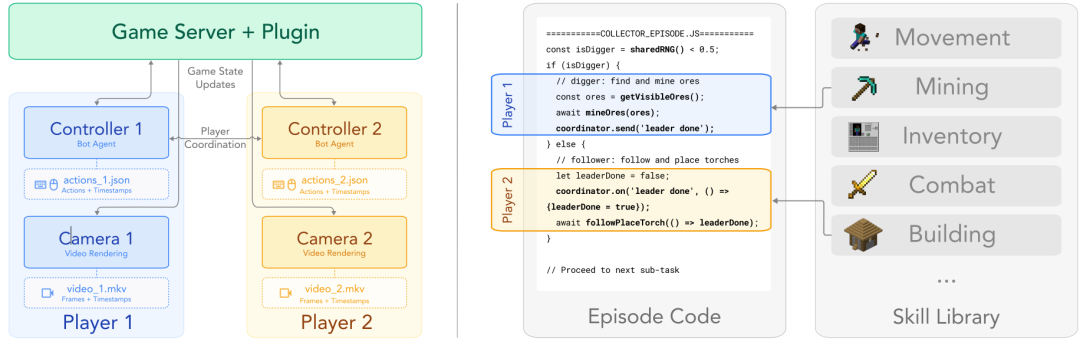
图 2 SolarisEngine 系统概览。 (左)基于 Docker 的容器化游戏服务器、相机机器人与控制器机器人编排架构。相机机器人通过自定义服务端插件镜像控制器的状态与动作;控制器为运行情节代码并记录底层动作的 Mineflayer 机器人。(右)情节通过组合共享库中的可复用基础技能构建。图中展示了简化的“采集者”情节代码示例。
多人在线训练数据集:如图 3 所示,该数据集涵盖建造、战斗、移动、采矿等核心任务,在“超平坦”与“普通”世界中均衡采集,总计每玩家 632 万帧。其中包含昼夜、生物群系、工具使用、天气等多样状态,动作标注包括 WASD 移动、视角控制及挖掘、放置等交互。该数据集是首个适用于机器学习的多人在线《我的世界》动作标注数据集。
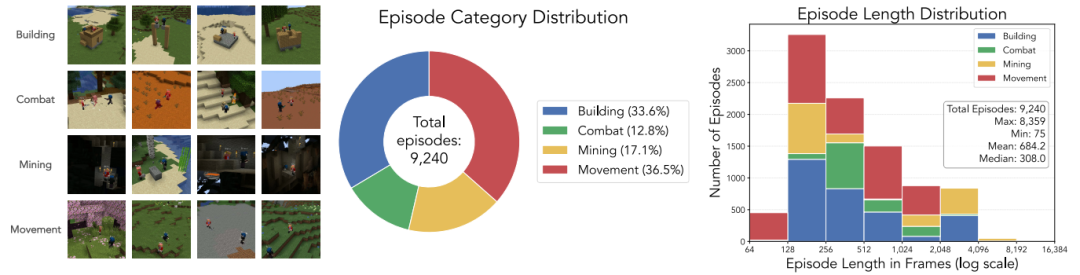
图 3 训练数据集的统计数据。
03 多智能体训练流程
训练流程遵循先训练双向基模型、再将其适配为因果模型以实现自回归生成的成熟范式。图 4 展示了各训练阶段。
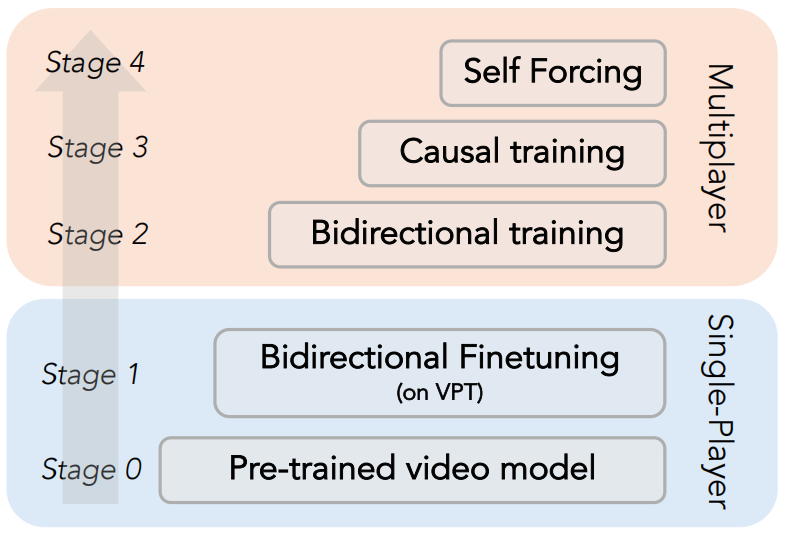
图 4 完整训练流程概览。
第一阶段:双向单智能体训练
模型从 Matrix-Game 2.0 的预训练权重初始化。为覆盖完整的《我的世界》动作集,模型在 VPT 数据集上进行微调,采用双向注意力机制,以 33 帧的上下文长度训练 12 万步。这一单智能体预训练阶段为后续的多智能体建模奠定了有效的初始化基础。
第二阶段:双向多智能体训练
基于 Solaris 架构,将单智能体模型扩展至多智能体场景,并在多智能体数据集上以全序列扩散方式继续训练 120k 步。此时,留出测试集上的 FID 指标趋于收敛,该检查点将作为后续自强制过程中的教师模型。
第三阶段:因果多智能体训练
为节省训练开销,在双向模型训练至 60k 步时分支出一个副本用于初始化因果模型,而原双向模型则继续独立训练至 120k 步,以获得高质量的教师模型。
因果模型遵循 Matrix Game 2.0 的设计,采用滑动窗口注意力掩码,窗口大小为 6 个潜变量帧(对应 24 个原始帧),该窗口尺寸即为推理时滚动 KV 缓存的最大长度。该模型使用扩散强制技术训练 60k 步,并作为自强制过程中生成器的初始权重。
第四阶段:自强制
为使生成器能从更强大的教师模型中受益,本文将教师模型的上下文长度扩展至超过学生模型,这要求学生在视频生成过程中采用滑动窗口上下文。
针对滑动窗口场景下直接应用自强制导致的内存爆炸问题,提出一种高效实现——检查点自强制(Checkpointed Self Forcing)。该方法首先在禁用梯度追踪的情况下执行自回归展开,生成初始视频并缓存中间加噪帧;随后在启用反向传播的附加前向过程中,利用这些缓存状态重新计算最终视频。此机制通过解耦自回归生成与梯度计算,有效消除了滑动窗口反向传播中固有的内存冗余。
04 评估
为全面评估模型能力,研究团队设计了一套留出情节类型,涵盖运动、空间定位、记忆、建造与一致性五个维度。视觉质量采用 FID 衡量,语义遵循度则引入“VLM 作为评判者”指标:向视觉语言模型提出与任务相关的可验证问题,若其答案与预期一致,则视为生成正确。
研究团队将所提出的架构实现与 Multiverse 的帧拼接方法进行了对比,后者是本研究之前唯一现存的多人世界模型。同时,通过将本文方法与未使用单智能体模型初始化的变体进行性能比较,验证了单智能体预训练的必要性。

图 5 Solaris 模型与基线方法的定性比较。
如图 5 所示,本文方法在定性视觉结果上表现优异;而在所有评估类别上的定量结果(如表 1 所示)同样优于对比方法。所有架构变体在基于运动的轨迹中都表现出较强的动作跟随能力,并在相应类别的评估中获得了较高的视觉语言模型评分(见表2)。本文方法在涉及建造、场景一致性和玩家空间定位等复杂场景中展现出更优性能,这体现在这些类别的视觉语言模型评分更高。尽管帧拼接方法在运动评估指标上表现更优,但定性分析发现,该方法在无操作动作存在时会产生动作幻觉。
表 1 跨任务定量比较。 将Solaris分别与参照 Enigma Multiverse 沿通道维度拼接玩家观测的方法,以及未经过单智能体预训练的从头训练方法进行了对比。











