绑定手机号
确认绑定









智猩猩AI整理
编辑:没方
推理模型通过扩展测试时计算(test-time compute)来增强问题解决能力,但过多的思考 token 在实际应用中往往会降低模型性能,而非提升性能。该现象源于根本性的架构缺陷:标准的大语言模型(LLMs)本质上是一种只分配不释放(malloc-only)的引擎,它们在推理过程中持续堆积 tokens,缺乏一种机制来剪除过时或无用的信息。
为应对上述挑战,腾讯 AI Lab 提出 Free()LM,通过增加一个即插即用的LoRA模块,给模型引入内在的自我遗忘能力。实验表明,Free()LM 在所有模型规模( 8B 至 685B)上均带来一致的性能提升:相较于当前顶尖的推理基线模型,平均提升达 3.3%;使用 DeepSeek V3.2-Speciale 时,在 IMOanswerBench 基准上达到新SOTA 性能。此外,在长程推理任务中,标准 Qwen3-235B-A22B 模型完全崩溃(准确率为 0%),而 Free()LM 成功将其性能恢复至约 50%。该研究表明,可持续的智能不仅需要思考的能力,同样需要遗忘的自由。

论文标题:Free(): Learning to Forget in Malloc-Only Reasoning Models
论文链接:https://arxiv.org/pdf/2602.08030
项目地址:https://github.com/TemporaryLoRA/FreeLM
模型:https://huggingface.co/collections/ldsjmdy/freelm
数据集:https://huggingface.co/datasets/ldsjmdy/FreeLM
01 方法
没有free()的模型如图1的左边部分,在从 AIME 24&25 基准中采样的 480 条推理轨迹中,当思考所用的 token 数量超过 16K,模型退化现象便急剧上升。具体而言,在达到上下文限制的31个案例中,已有26例(84%)陷入重复循环状态;当思维 token 数达到 48k 时退化率飙升至100%,模型推理能力已完全崩溃。
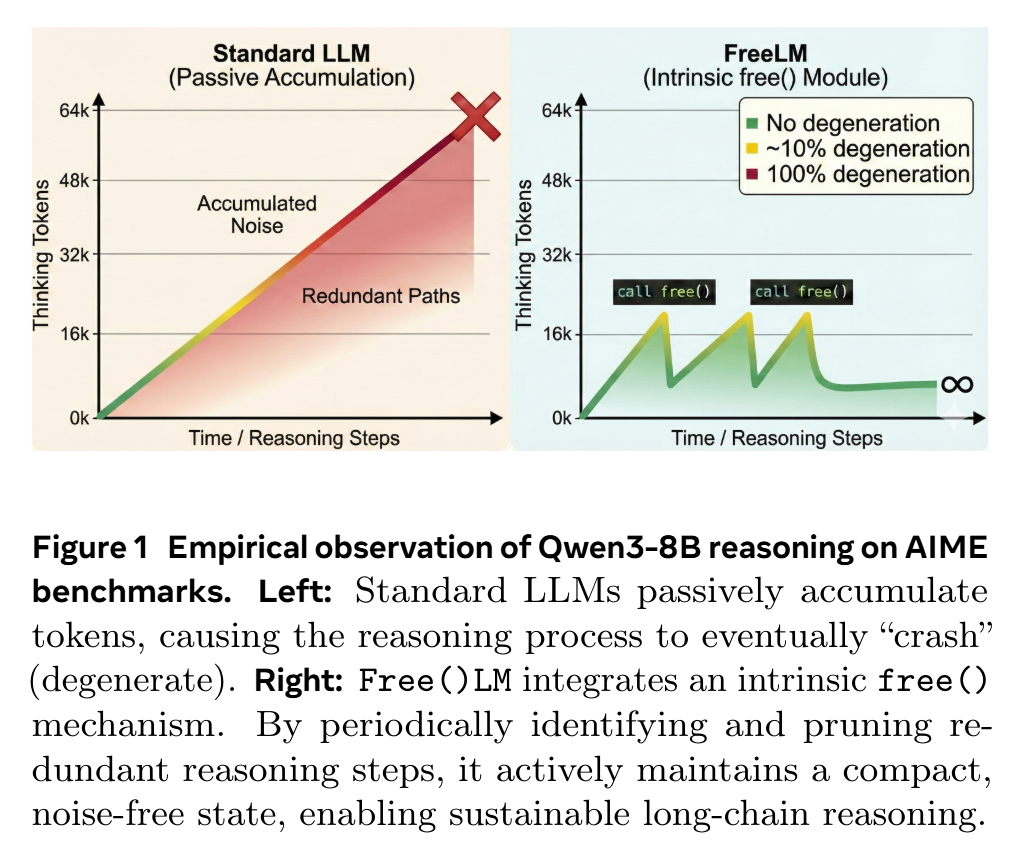
(1)架构与推理
为突破这种“malloc-only”循环,研究团队提出了 Free()LM。该设计源于一个简单观察:复杂推理过程必然产生冗余信息,例如已被解决的中间步骤或失效的尝试路径。因此,可以通过内置的free()机制周期性地修剪这些冗余信息。
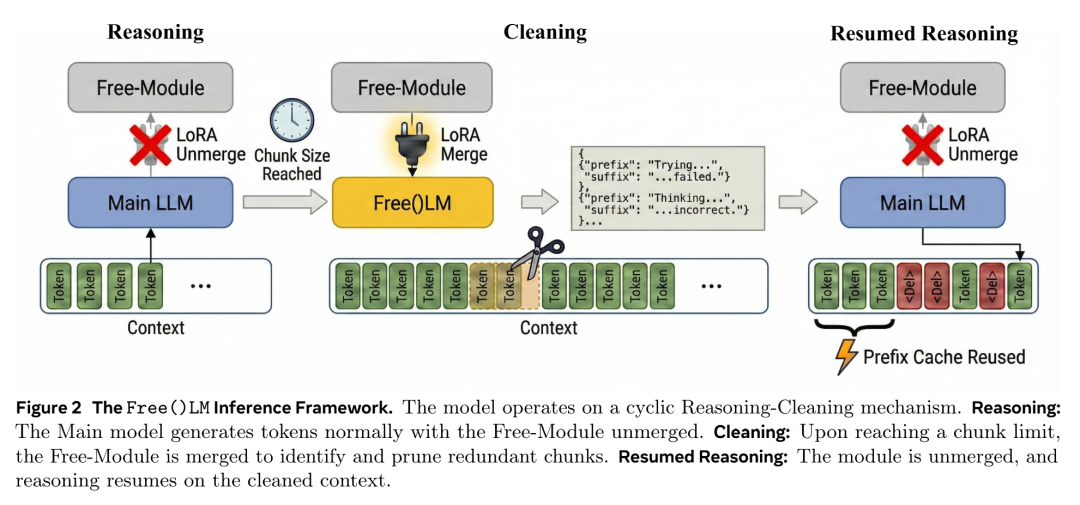
如图2所示,研究团队通过插入一个额外的LoRA模块(Free-Module),通过动态合并(merge)与分离(unmerge)该模块,Free()LM可在两种模式间切换:
推理模式(unmerge模式):模型行为与原始主干网络完全一致,专注于生成下一个 token 以解决问题。
清理模式(merge模式):Free-Module 被激活,扫描当前上下文识别出无用片段,并输出一条包含所有待删除chunk的前缀和后缀的删除命令,然后直接来一个 re.sub() 一键替换,这样的方式,可以用极少decoding tokens删除超长chunks。
借助这种动态切换机制,Free()LM 得以持续维持紧凑无噪的思维状态,实现可持续的推理过程。
(2)训练:学会遗忘
考虑到主动上下文管理这一概念,一个自然的切入点是从上下文学习(In-Context Learning,ICL)着手:让模型进行自我修正,或借助强大的外部大语言模型来识别冗余内容。然而,即便经过大量提示优化并调用Gemini-2.5-Pro等顶尖模型作为专家助手,Qwen3-8B模型的性能提升也微乎其微(仅约1%)。这一发现表明,有效执行free()操作(即区分必要历史上下文与过时噪声)是一种需要通过专门训练才能获得的复杂能力。
为解决缺乏真实标注数据的问题,研究团队提出了一套以精细化奖励机制为核心的数据构建流程。首先通过 ICL 方法, 利用 Gemini-2.5-Pro 从 DeepMath-103k 中生成大量候选剪枝操作。随后采用严格的拒绝采样策略进行验证:对每个候选操作,在原上下文与剪枝后的新上下文上分别执行 8 次独立推理 rollout,仅保留那些不降低准确率的剪枝样本。通过这一流程,最终筛选出 6648 个高质量训练样本,用于训练Free-Module,使其学会去除噪声,并能够保持正确解题的概率。整个流程如图3所示。
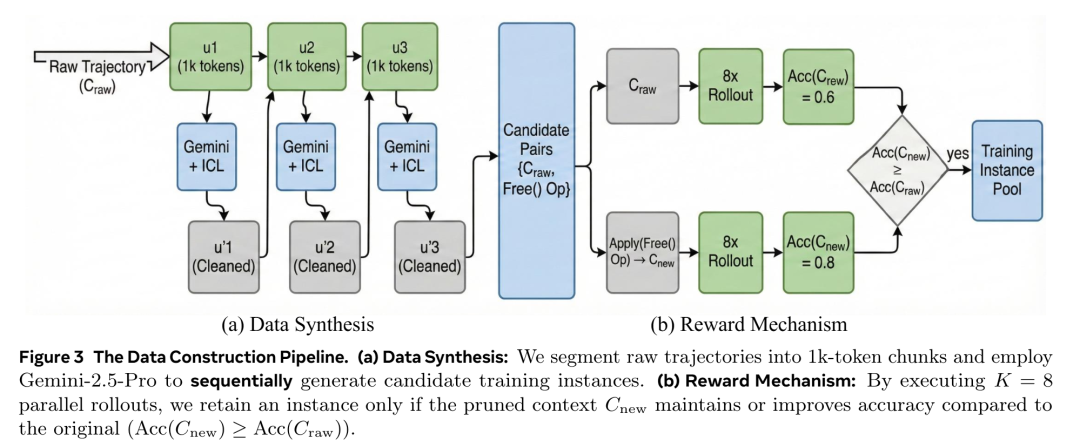
02 实验
在实验中,研究团队有三个惊人的发现:
从8B-235B,效果全线上涨!
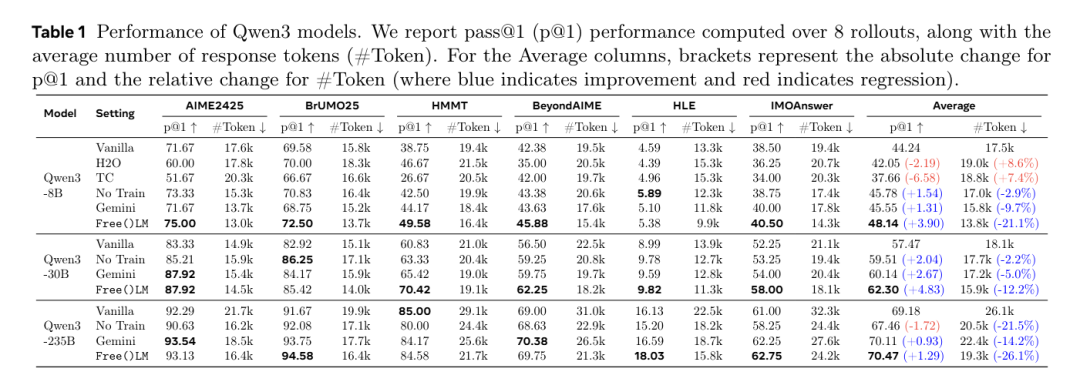
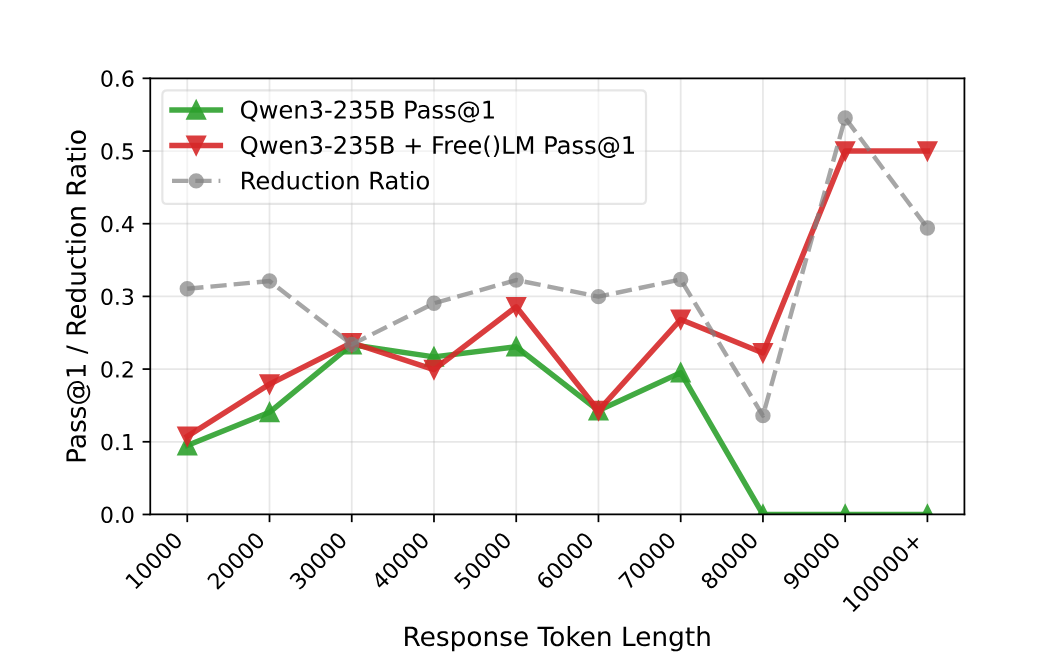
另外,因为 Megatron 还没支持训练 Deepseek V3.2,研究团队用 8B 的Free()LM 强行给 Deepseek V3.2 Speciale 当外挂。结果 IMOAnswerBench 直接涨了2.2%,刷出了个新 SOTA 。
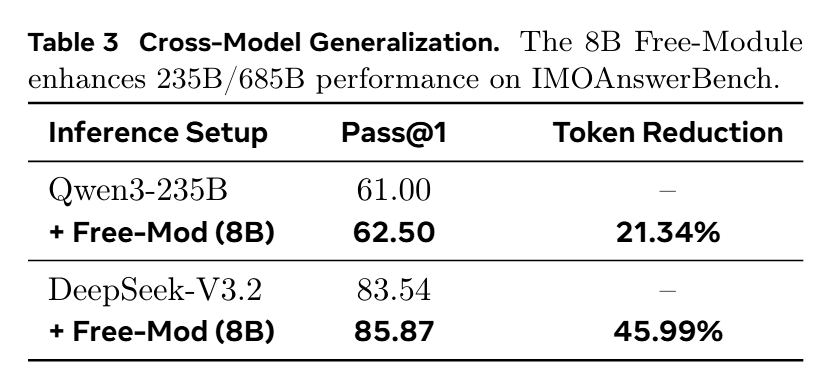
最神奇是,研究团队在 HLE 上发现一旦 Qwen3-235B 推理长度超过 80K tokens,它就彻底崩了,准确率直接暴跌为 0%。而加上 Free()LM 后,在这些必死的 Case 上,准确率回到了 50%!虽然样本量有限(毕竟能推这么长的 case 也不多),但效果的对比是鲜明的,毕竟 HLE上 平均才16%。
AGI的下一块拼图可能不在于更大的内存,而是一个小小的 delete 键。










