绑定手机号
确认绑定









失控上下文投稿
智猩猩AI整理
当 AI Agents 从“会聊天、会调工具”走向“能长期工作、能跨任务复用经验”,一个越来越现实的问题浮出水面:
Agent 不是记不住,而是不会高效地记。
表面上看,现在不少智能体都能保存长上下文、存下交互历史、接入外部记忆模块;但问题在于,这些“记忆”往往只是冗长、零散、低密度的原始轨迹。信息越存越多,真正能在关键决策时派上用场的部分反而越难被找到,最终把 Agent 拖入上下文膨胀、检索失焦和推理迟钝的泥潭。微软研究院今天发布的官方博客就直接点出了这一点:给 AI Agents 更多记忆,反而可能让它们更低效。
也正是在这样的背景下,微软研究院官方今天专门发文介绍了一项来自伊利诺伊大学厄巴纳-香槟分校、清华 、Microsoft Research联合的新工作:PlugMem。
博客链接:https://msft.it/6017Qc9vv
研究团队不只是提出了一个新的 Agent memory 方法,更试图回答一个更底层的问题——AI Agents 应该如何组织长期记忆,才能把“交互历史”真正变成“可复用知识”。

论文题目:
PlugMem: A Task-Agnostic Plugin Memory Module for LLM Agents
论文链接:
https://arxiv.org/pdf/2603.03296
01 为什么说 PlugMem 踩中了 AI Agents 现在最痛的点?
最近 AI Agents 的热度已经不需要再证明了。无论是龙虾(OpenClaw)和大厂的 agentic workflows、企业里的自动化流程,还是浏览器代理、知识工作助手、多智能体协作系统,整个行业都在从“单轮生成”转向“长流程执行”。而一旦 Agent 真的要长时间工作,Memory 就不再是锦上添花,而是底层刚需。 微软 Azure 近期对 agentic AI 的概括里,就把 memory 与 orchestration、goal-oriented behavior 并列为关键能力;Google Cloud 也在最新趋势内容中持续强化 AI agents 正在进入复杂业务流程这一判断。
问题是,今天大量 Agent 的 memory 设计仍然停留在“存更多历史,再从历史里捞”。
而 PlugMem 想做的,是把这个范式扭转过来。 研究团队指出,现有长期记忆设计常常陷入两难:
要么是任务特化型,在特定场景里很好用,但几乎无法迁移;
要么是任务无关型,但因为直接检索原始记忆,容易出现低相关性和上下文爆炸。
PlugMem 的核心目标,就是做一个task-agnostic 的插件式 memory module,不需要针对每个任务单独重做记忆系统,也能在不同 Agent 任务之间复用。
更关键的一点在于,它没有把“记忆”理解成大段历史文本,而是受认知科学启发,把记忆分成更适合 Agent 决策的两类知识:
一类是 propositional knowledge,也就是“知道什么”的事实性知识;
另一类是 prescriptive knowledge,也就是“知道怎么做”的程序性知识。
这其实非常贴近真实使用场景。
例如长期对话里,Agent 真正需要的并不是把几十轮聊天记录全重新读一遍,而是快速抓到“用户偏好、限制条件、长期目标”这种浓缩后的事实知识。
又比如网页操作类 Agent,真正有价值的也不是完整保留一个网页操作轨迹,而是沉淀成“搜索、筛选、排序、结账”这类以后还能复用的操作性知识。换句话说,在陌生网页界面上,Agent 更需要的是可泛化的 procedural knowledge,而不是带着大量无关页面观察的原始轨迹。
总而言之,PlugMem 不是让 Agent 记得更多, 而是让 Agent 把记忆组织成真正有用的知识单元。
02 PlugMem 到底做了什么?
从整体设计上看,PlugMem 可以理解成一个面向 Agent 的通用记忆骨架。
它的核心流程是:
首先,它会把来自不同来源的原始交互——比如对话、文档片段、网页操作轨迹——统一标准化成 episodic memory;
然后,再从这些经历中抽取出 semantic memory 和 procedural memory,把它们组织进一个以知识为中心的 memory graph;
最后,在具体任务发生时,通过检索和推理,把这些知识重新压缩成对当前决策最有帮助的 memory tokens,送给基础 Agent 使用。
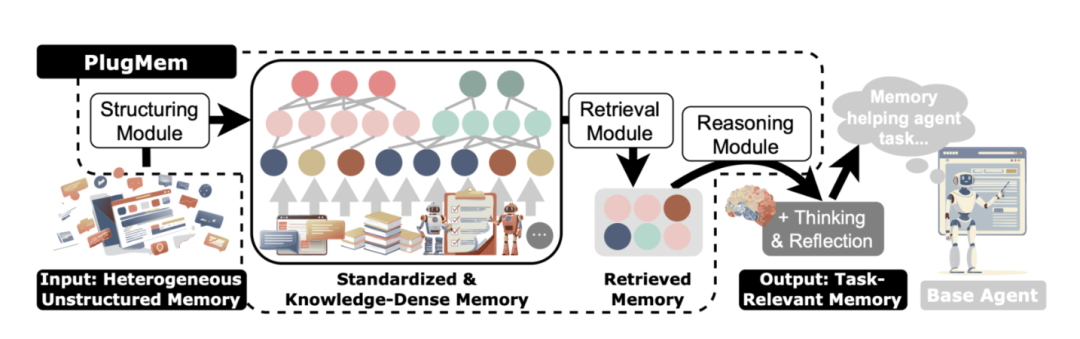
研究团队把整个系统拆成了三个核心模块:
(1)Structuring Module:把“经历”变成“知识”
这是 PlugMem 最核心的一步。它不是直接存原始交互,而是先对原始交互做标准化,再进一步抽取两类知识:
semantic memory:例如事实命题、用户偏好、世界知识
procedural memory:例如可复用的策略、工作流、操作步骤
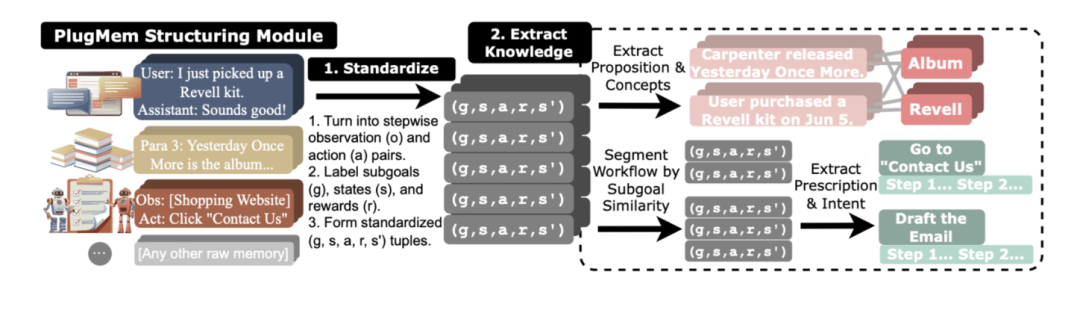
研究团队进一步把三类记忆映射成三种不同的知识单元:
semantic memory对应proposition,procedural memory对应prescription,episodic memory则作为可追溯、可验证的source trace 存在。
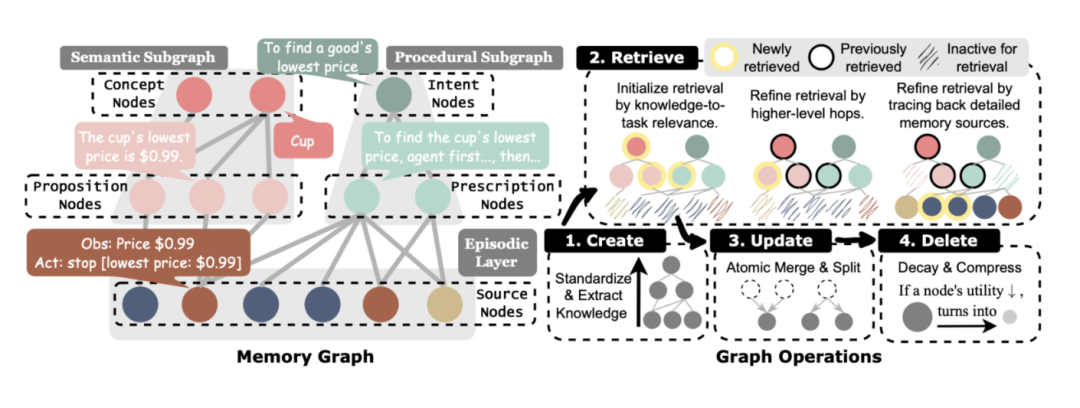
这背后的关键思想是:episodic memory是证据层,semantic / procedural memory才是决策层。
(2)Retrieval Module:不是捞文本,而是捞知识
PlugMem会根据任务类型判断应该更强调 episodic、semantic 还是 procedural memory,然后在 memory graph 里做多跳检索:低层节点用于匹配,高层概念或意图节点则承担路由作用,最终把真正相关的知识块激活出来。
这意味着它检索的不是一堆零散句子,而是更接近决策所需的知识结构。
(3)Reasoning Module:把检索结果压成行动指南
即便检索到了相关知识,也不代表能直接喂给 Agent。因为多个相关记忆之间往往会有重叠、冗余甚至噪音。
所以 PlugMem 还有一层 reasoning module,会把检索结果进一步凝练成更短、更贴近当前任务的 actionable guidance。论文提到,这一模块能把 memory token 使用量降低 1 到 2 个数量级,让 Agent 在紧张的上下文预算下依然拿到高密度信息。
这点非常重要。 因为对 Agent 来说,Memory 的价值从来不只是“有没有”,而是单位 token 里到底装了多少真正对决策有用的信息。
03 不是只在一个任务上好用,而是跨任务成绩亮眼
PlugMem 一个很重要的特点,是它在三类异构 Agent 任务中都采用了同一套 memory module,并完成了跨任务验证:
长周期对话记忆:LongMemEval
多跳知识检索:HotpotQA
网页智能体任务:WebArena
PlugMem 在这三类 benchmark 上保持了统一的核心设计,也就是说,这套方法可以直接在不同场景中复用,不需要针对每个任务重新设计一套专门的 memory 机制。
具体结果也很亮眼:无论是在长程记忆评测、知识问答还是网页交互任务中,PlugMem 都展现出更优的整体表现;更重要的是,它在提升准确率和成功率的同时,把 memory token 成本压到了明显更低的水平。
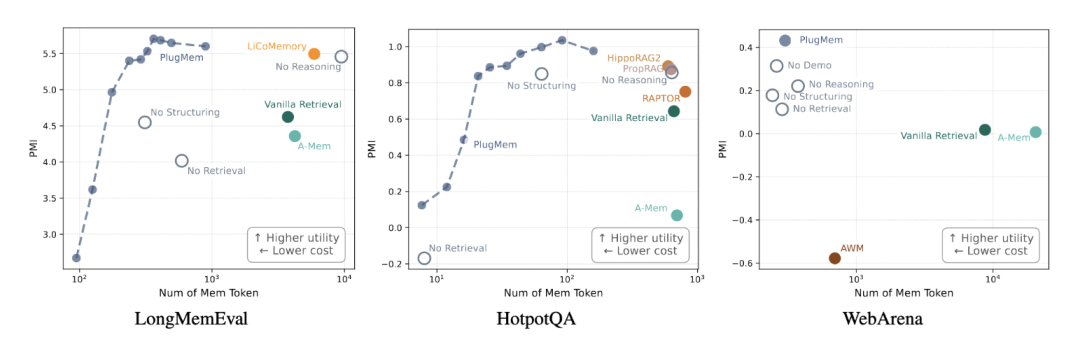
如果只看“效果好”还不够,研究团队还专门提出了一个统一的 utility-cost analysis 框架,用 information density 去衡量“每个 memory token 带来了多少决策相关信息收益”。实验结论是,PlugMem 在三个 benchmark 上都处在更优的 utility-cost trade-off 区间,也就是:更高 utility,更低 cost。
这些结果说明,Agent memory 的问题不只是“能不能存下来”,还包括“能不能以更紧凑、更有效的方式被重新调用”。PlugMem 的价值,也主要体现在这里。
04 它真正重要的地方,是在给Agent Memory换了组织单位
PlugMem 的意义,不仅在于提出了一个新的 memory module,也在于它对 Agent memory 的组织方式给出了一种更明确的抽象。
论文中一个值得注意的观点是,PlugMem 并不把记忆简单理解为待检索的原始文本或历史轨迹,而是进一步区分出更适合决策使用的知识类型。具体来说,研究团队将 memory 中可复用的内容组织为 propositional knowledge 和 prescriptive knowledge,并据此构建面向任务调用的 memory representation。论文也将这一点与 GraphRAG 作了区分:后者更多以实体或文本块为基本组织单位,而 PlugMem 更强调以知识单元作为访问和组织的基础。
从这个角度看,PlugMem 讨论的已经不只是“如何存储更多历史信息”,而是“如何把交互经验转化为后续任务中更容易调用的知识结构”。这一点也解释了它为什么能够在长期对话、多跳知识检索和网页任务三类场景中使用同一套核心设计完成验证。
结合论文中的任务设置和实验结果,这种记忆组织方式与几类当前较受关注的 Agent 场景都有较强相关性:
(1)长期个性化助手
在长期交互场景中,Agent 往往需要持续利用用户偏好、历史约束和阶段性目标。如果这部分信息始终以原始对话记录的形式保留,后续调用的成本会随着上下文增长而不断上升。将其中稳定、可复用的内容提炼为结构化知识,会更符合这类场景的实际需求。
(2)企业知识工作流 Agent
在企业知识检索、研究辅助和复杂问答等任务中,Agent 往往需要跨文档整合信息,并在多轮推理中持续调用已有知识。此时,memory 的组织方式会直接影响检索效率和推理质量。PlugMem 在 HotpotQA 这类多跳知识检索任务中的结果,说明它对知识整合和后续调用具有一定优势。
(3)浏览器代理与 Web Agent
网页任务通常包含较长的操作链条和较复杂的中间状态,原始轨迹虽然完整,但并不一定适合在后续任务中直接复用。对于这类场景,更有价值的往往是从过往执行过程中沉淀出可迁移的操作经验和策略。PlugMem 在 WebArena 上对 procedural knowledge 的建模,正与这一类需求高度相关。
(4)跨任务复用的 Agent 系统
PlugMem 的定位是一个 task-agnostic plugin memory module,这意味着它关注的是更通用的 memory backbone,而不是针对某一类任务进行特定优化。
整体来看,PlugMem 提出的重点,在于为 Agent memory 提供了一种更适合长期复用和跨任务迁移的组织框架。对于当前正在走向长流程执行、持续交互和多场景部署的 Agent 系统来说,这样的抽象方式具有比较明确的现实意义。
05 为什么微软研究院会专门写博客介绍这项工作?
从更长的研究脉络来看,PlugMem 的价值并不只在于提出了一个性能更优的 memory module,更在于它把 Agent memory 的讨论从“如何保存历史信息”推进到了“如何组织可复用知识”这一层面。
这一问题之所以重要,是因为随着 Agent 从单轮生成走向持续交互、长程推理和复杂任务执行,memory 的作用已经逐渐超出上下文补充的范畴。它开始承担一种更基础的功能:连接过去的经验、当前的决策与未来的迁移能力。一个 Agent 能否在不同任务之间形成真正的经验积累,很大程度上取决于它如何表示、提炼和调用这些记忆。
从这个意义上说,PlugMem 所讨论的并不是一个局部优化问题,而是 Agent 系统走向长期运行之后必须面对的一项基础问题:历史经验究竟应当以什么形式存在,才能在后续任务中持续发挥作用。围绕这一问题展开的探索,可能会进一步影响 Agent memory research 在知识抽象、记忆压缩、跨任务迁移以及长期学习机制等方向上的发展。
微软研究院在此时专门发文介绍这项工作,也说明 Agent memory 的研究重点正在从“能否扩展上下文”转向“能否形成可复用的知识结构”。从这个角度看,PlugMem 所触及的,已经不只是单篇方法论工作的改进空间,而是 Agent 从“调用模型”走向“积累能力”过程中一个更核心的基础层问题。
对 Agent 来说,真正重要的也许从来不是记住了多少过去,而是过去能否进入未来。










