绑定手机号
确认绑定









阿里巴巴高德投稿
智猩猩AI整理
世界模型被视为构建具身智能体的关键基础设施,能够模拟物理世界、预测未来,从而赋能机器人的规划与决策。而一个对机器人有用的世界模型,必须能预测遵循物理规律的未来。视频生成为此提供了一个极具吸引力的范式,它可作为视觉-语言-动作(VLA)策略的模拟器,为规划提供轨迹预览,或直接生成动作序列。
然而,现有包括Veo 3.1和Sora v2 Pro在内的顶尖模型,虽然视觉效果惊艳,但在机器人操控任务的物理一致性上却表现出明显不足。例如,机械臂穿透物体、物体在没有接触的情况下“吸附”在末端执行器上、刚性部件在交互中发生不应有的形变等,这极大地限制了其在真实场景中的应用价值。
导致这些问题的两大根本原因在于:1)数据偏差,现有模型大多在缺乏具身交互内容的通用视觉数据上训练,对于摩擦、碰撞、接触动力学等机器人操控特有的物理约束,提供的监督信号非常有限。;2)训练范式局限,监督式微调(SFT)采用最大似然目标,无法区分物理正确与错误的预测,更不会主动惩罚穿模、反重力等物理违规行为。
为了弥合视觉-物理的鸿沟,阿里巴巴高德构建了一个物理对齐的、动作可控的交互式世界模型ABot-PhysWorld,基于140亿参数Diffusion Transformer 。该模型的主要创新点如下:
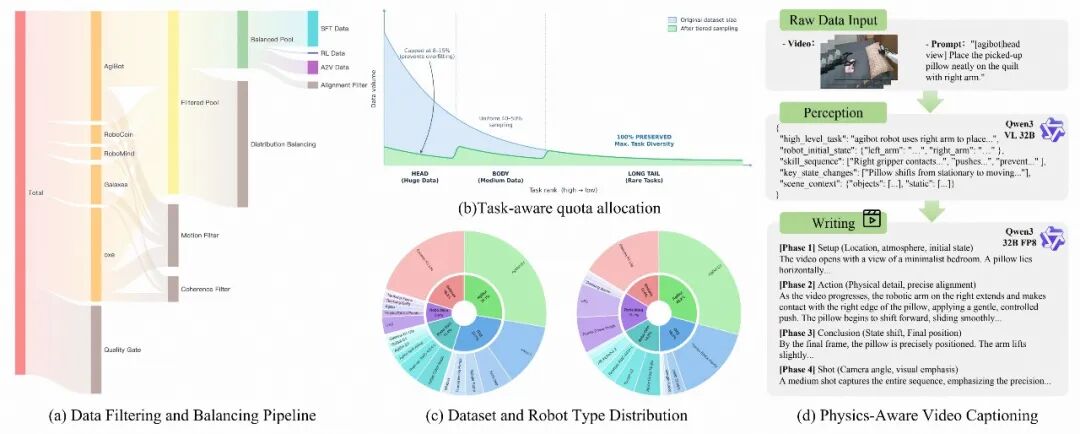
精心构建的数据基础:打造了一个包含三百万个真实世界操控视频的精选数据集,并通过分层分布均衡策略确保了数据的多样性与稀有场景的覆盖。
物理偏好对齐:首创性地提出一种自动化物理偏好对齐流程,利用解耦的视觉语言模型(VLM)判别器进行物理规则的“出题”与“打分”,并通过内存高效的Diffusion-DPO算法,引导模型生成更符合物理规律的视频。
高保真动作注入:设计了一种并行上下文块机制,将机器人动作指令编码为空间动作图谱,并以残差方式注入主干网络,实现了跨形态机器人的精准控制,同时有效避免了对预训练物理知识的“灾难性遗忘”。
严苛的零样本评测:提出了全新的具身视频生成零样本评测基准 EZSbench,通过组合合成的分布外(OOD)场景和解耦的双模型评测协议,为评估模型的物理泛化能力提供了严谨的标尺。
实验结果表明,ABot-PhysWorld在物理真实性上树立了新的SOTA标准,在PBench和EZSbench上的领域得分(Domain Score)分别达到了 0.9306 和 0.8366,显著超越了Veo 3.1和Sora v2 Pro等顶尖模型,同时在动作条件生成任务中展现了最高的轨迹一致性。

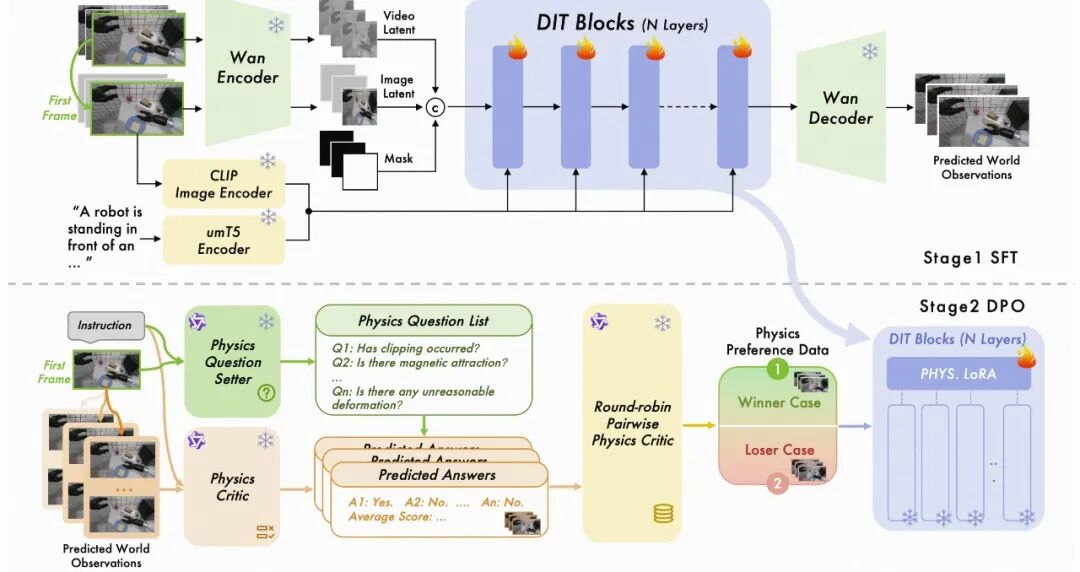
ABot-PhysWorld从数据、训练、控制、评测四个维度系统性地构建了一个物理对齐的、动作可控的交互式世界模型。该模型建立在一个140亿参数的Diffusion Transformer(Wan2.1-I2V-14B)之上。
1. 数据构建:从源头注入物理知识
高质量、多样化的数据是模型泛化能力的基础。研究团队构建了一个系统化的数据处理管线,包含三个核心阶段:
具身专用数据筛选:整合AgiBot、RoboCoin、OXE等五个公开数据集,构建了近三百万个真实世界机器人操控视频的原始数据池。随后,通过视频质量门控、基于光流的运动滤波、基于CLIP的时间一致性评估以及视觉-动作对齐验证,剔除了包含静态画面、视觉伪影和控制信号失配的低质量数据。
分层分布均衡:为避免模型对常见任务的“过拟合”而忽视稀有但关键的交互模式,研究团队设计了一套精细的四级采样策略:
i.子数据集内多样性保留:完整保留小规模子数据集,以保护独特的交互模式。
ii.跨机器人形态重平衡:对稀有机器人类型进行上采样,增强模型的跨平台泛化能力。
iii.任务感知的配额分配:将任务按数据量分为头部、中部和长尾三类,分别进行不同比例的采样(头部8-15%,中部40-50%,长尾100%保留),最大化任务多样性。
iv.宏观数据集规模调控:对超大规模数据集进行上限约束,防止其主导训练分布。
物理感知的视频字幕生成:为了给模型提供更深层次的语言监督,研究团队设计了一套多层次、物理感知的字幕生成系统。它不仅描述“机器人做了什么”,更解释“如何交互”以及“为何发生”。字幕内容涵盖宏观任务意图、微观动作细节(如笛卡尔轨迹、接触状态)、物理因果关系(如重力、形变)和场景上下文,为训练具备因果推理能力的世界模型奠定了语义基础。
2. 物理偏好对齐:用DPO纠正物理谬误
为解决SFT无法主动惩罚物理错误的局限,研究团队引入了基于直接偏好优化(DPO)的物理对齐框架。
解耦的VLM判别器:这是一个巧妙的自动化偏好数据生成流程。
i.物理法则提议者 (Proposer):使用一个VLM(Qwen3-VL 32B),根据初始帧和指令,动态生成一个任务相关的物理问题清单。例如,对于“把苹果放进袋子”的任务,它会提问“机械臂是否穿透了苹果?”、“苹果是否被牢固抓取而非磁力吸附?”等。该提议者还会刻意生成部分否定性问题,防止评分模型“抄近道”。
ii.物理保真度评分者 (Scorer):使用另一个更强的VLM(Gemini 3 Pro),通过思维链(Chain-of-Thought)推理,回答上述问题清单,并对多个候选视频进行打分。
iii.锦标赛采样:通过淘汰赛和复活赛机制,高效地从N个候选视频中选出物理表现最优(winner)和最差(loser)的样本对,构成高区分度的DPO训练三元组 (x,y_w,y-1)。
基于DPO的强化学习训练:将Diffusion-DPO框架应用于视频生成。通过优化一个特定的损失函数,使得模型在去噪的每一步都主动降低对物理正确视频的预测误差,同时增大对物理错误视频的预测误差。为了在140亿参数模型上实现这一过程,研究团队冻结了DiT主干,并利用低秩自适应(LoRA)技术进行内存高效的微调。
3. 动作条件生成:精准控制且不忘本
为了让世界模型能够根据未来的动作序列进行可控的预测,研究团队提出了一个高效的动作注入机制。
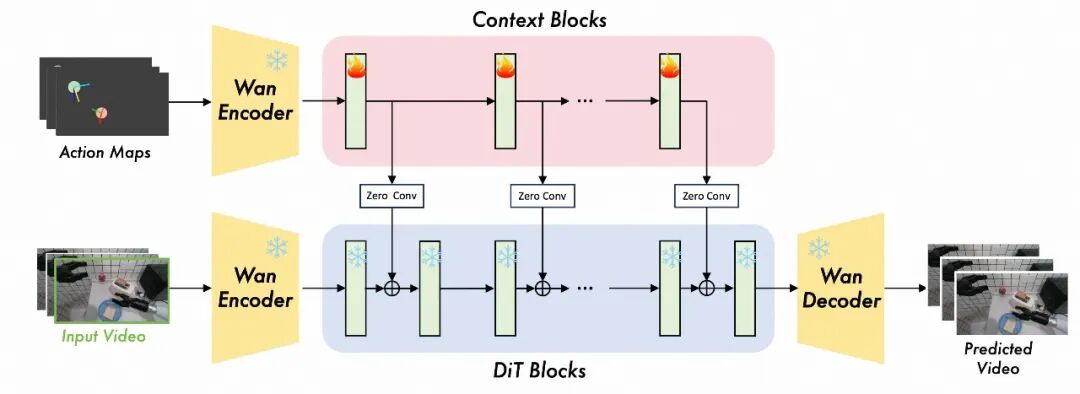
动作图谱构建:将7D(单臂)或14D(双臂)的动作向量(位置、姿态、夹爪状态)投影到图像空间,渲染成一个多通道的“动作图谱”。其中,位置映射为2D中心点,姿态编码为彩色箭头,夹爪状态则通过圆形掩码的不透明度表示。
并行上下文块注入:为避免在注入动作信息时破坏模型已学到的物理先验(即“灾难性遗忘”),该研究借鉴了VACE架构,设计了一种新颖的注入方式。
i.克隆主干DiT的部分模块,形成一个并行的上下文块(Context Blocks)分支,专门处理动作图谱。
ii.将上下文块的输出通过零初始化卷积层(Zero-Initialized Convolutions),以残差相加的方式注入到主干网络中。
这种设计确保了在训练初期,动作注入分支对主模型没有影响,使得模型可以在保留预训练知识的基础上,平滑地学习如何融合动作控制信号。
4. 评测基准:零样本物理泛化能力试金石
为严格评估模型在未见过场景中的物理泛化能力,研究团队构建了 Embodied-ZeroShot Benchmark (EZSbench)。
评测集构建:通过双分支策略生成初始观测图像:一支使用T2I模型(Nano Banana)合成全新的机器人-场景-任务组合;另一支使用VLM对真实图像进行可控编辑,动态改变背景。随后,通过一个三阶段的“物理启发式密集描述合成框架”,为每张图像生成高度逼真且物理细节丰富的文本描述。
评测方法:同样采用解耦的双模型范式。由Qwen3-VL-32B根据初始状态和指令动态生成物理检查清单,再由Qwen2.5-VL-72B作为独立的裁判进行回答和打分,从而客观、严谨地量化模型生成视频的物理一致性。
研究团队在两个权威基准PBench和自建的EZSbench上进行了广泛的定量和定性比较,对手包括Sora v2 Pro、Veo 3.1、GigaWorld-0等多个SOTA模型。
定量结果
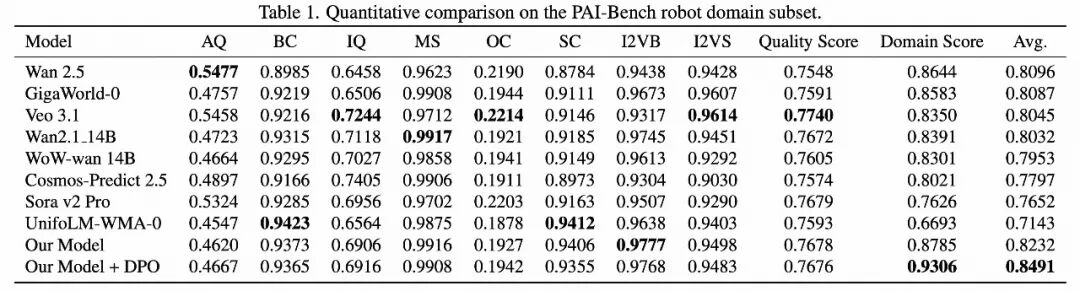
PBench评测:ABot-PhysWorld(DPO增强后)取得了 0.9306 的领域得分(Domain Score),在物理、空间、时间三个维度的逻辑一致性上全面领先。与之对比,Veo 3.1和Sora v2 Pro虽然视觉质量得分较高,但领域得分分别只有0.8350和0.7626,证实了它们在物理真实性上的短板。ABot-PhysWorld在保持高视觉质量(Quality Score: 0.7676)的同时,实现了最佳的物理保真度。

EZSbench评测:在更具挑战性的零样本泛化测试中,ABot-PhysWorld再次夺魁,领域得分达到 0.8366,总平均分也位列第一,证明了其强大的分布外泛化能力。
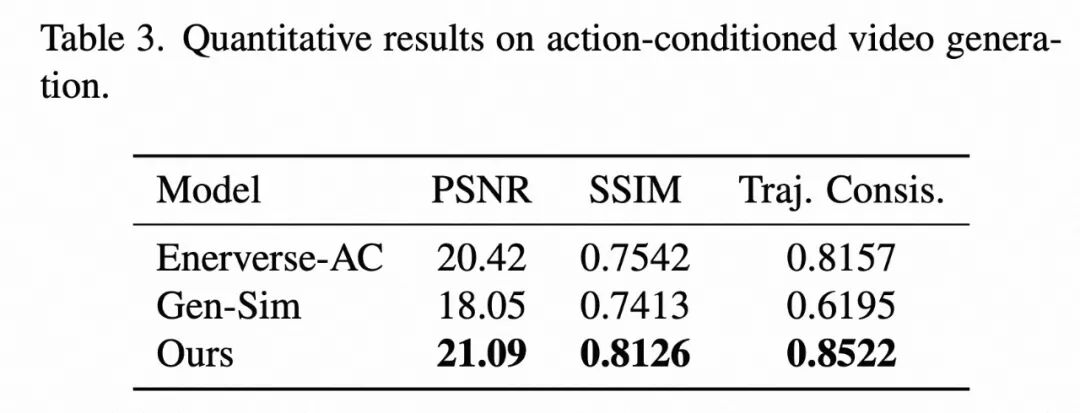
动作条件生成评测:在动作控制任务中,ABot-PhysWorld在PSNR、SSIM等视觉质量指标和轨迹一致性(nDTW)指标上均超越了Enerverse-AC和Gen-Sim等专门模型,实现了0.8522的最高轨迹一致性得分。
定性结果
定性比较结果直观地展示了ABot-PhysWorld的优越性。在其他模型频繁出现夹爪/物体形变、抓取穿透、目标识别错误或非接触式“吸附”等物理违规时,ABot-PhysWorld能够准确识别目标,生成时空连贯、无穿模、无形变的物理合理交互序列。

ABot-PhysWorld的提出,为构建物理对齐的具身世界模型迈出了坚实的一步。通过结合精选的具身交互数据、创新的物理偏好对齐框架、高保真的动作注入机制以及严苛的零样本评测基准,该研究成功地将一个140亿参数的视频生成模型塑造成了一个能够深刻理解并遵循物理规律的交互式世界模型。
这项工作不仅在技术上刷新了物理真实性的SOTA纪录,更重要的是,它为整个领域指明了一条弥合“视觉-物理鸿沟”的有效路径。虽然当前模型仍存在对固定视角的依赖等局限,但ABot-PhysWorld无疑为未来开发能够真正在物理世界中部署、规划和执行任务的通用机器人智能体奠定了重要的基础。










