绑定手机号
确认绑定









RUC AIBox投稿
智猩猩AI整理
可验证奖励强化学习(RLVR)常被用于提升大语言模型(LLMs)的推理能力。在训练过程中,模型基于给定的输入进行探索获取经验,并根据经验进行学习和提升。然而,近期的研究发现,模型如何进行有效探索是RLVR训练过程中存在的一个关键问题。对于难度较高的任务,模型难以仅依靠自身的多次探索获得正确的经验,从而限制了其从经验中有效学习的能力。
针对上述挑战,中国人民大学和字节跳动的研究者们提出了新的RLVR训练方法 。在该方法中,研究者通过采用不同的任务设置和RLVR 训练策略,分别训练得到一个拆解器(Decomposer)和一个推理器(Reasoner)。在给定问题时,Decomposer 能够将原始的复杂问题拆解为一系列更为简单的子问题,从而为 Reasoner 的探索过程提供额外的信息与思路引导,辅助其进行更高效的推理与探索。在这一框架下,由同一基座模型衍生得到的 Decomposer 与 Reasoner 可以相互促进,实现模型的自我演化,并进一步突破其原有的推理性能上限。

论文标题:Adaptive Ability Decomposing for Unlocking Large Reasoning Model Effective Reinforcement Learning
论文链接:https://arxiv.org/abs/2602.00759
01 方法
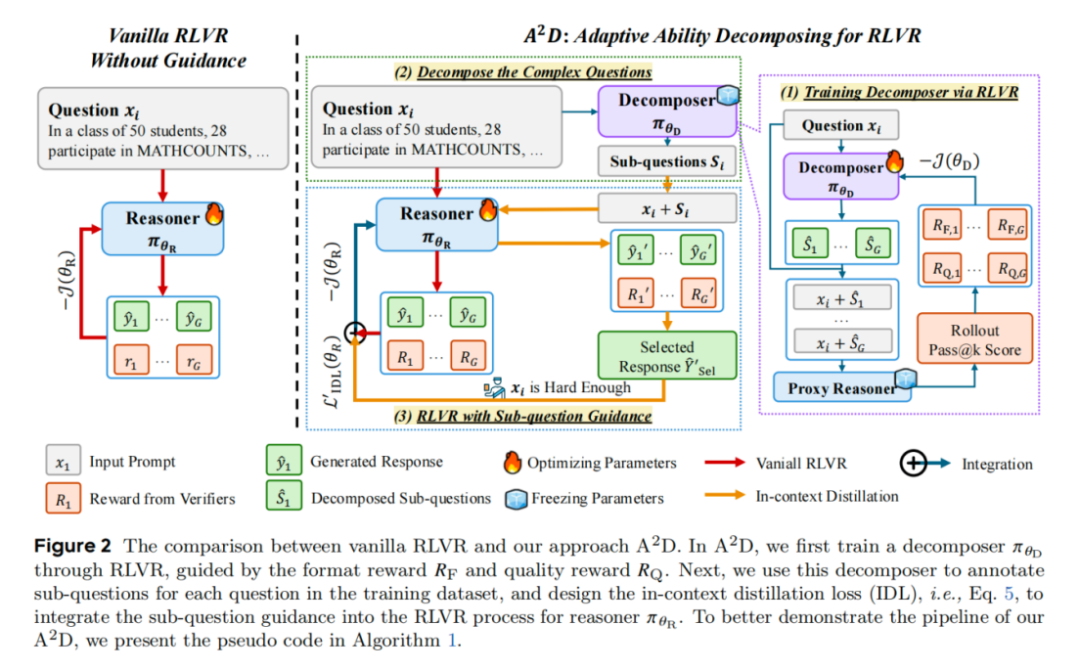
算法流程分为两个部分:Decomposer训练和Reasoner训练。首先,利用 RLVR 训练Decomposer,旨在将原始复杂问题拆解为若干简单的子问题。随后,引入了上下文蒸馏损失(In-Context Distillation Loss, IDL),引导Reasoner从子问题引导下的探索过程中所获得的经验中进行学习。在该方法中,无需对数据进行额外的标注。
1.1 Decomposer的训练过程
研究团队使用RLVR算法对Decomposer进行训练,使其能够将复杂的推理任务拆解为若干个简单的任务,以辅助后续Reasoner的训练过程。研究团队设计了RLVR训练过程的奖励函数,使其能够适配Decomposer的训练。奖励函数分为以下两个部分:
Format Reward:Decomposer生成的内容必须符合格式要求,以便于后续进行解析和为Reasoner提供提示。
Quality Reward:将问题和Decomposer生成的内容进行拼接后,输入到代理推理模型中(Proxy Reasoner),将其生成的解答的Pass@k指标作为奖励值。
得到两种奖励值后,将其相乘,作为最终Decomposer训练过程的奖励值。
1.2 Reasoner的训练过程
为了能够使研究团队的算法和现有RLVR算法进行结合,研究团队设计了上下文蒸馏损失(In-Context Distillation Loss,IDL),以引导模型基于子问题提示进行探索和学习。具体来说,IDL分为以下三个步骤:
将原问题和Decomposer拆解得到的子问题进行拼接,引导Reasoner基于拼接后的prompt生成解答,其中包括完整推理过程及最终答案。
对于简单的题目,Reasoner无需子问题提示就能做对。因此,IDL中需要使用难度较大的题目。此外,从所有生成的解答中筛选出正确的解答,用于后续的训练中。
得到题目以及解答后,将子问题提示去除,引导模型学习基于原始问题生成对应的解答。损失函数可以由下面的式子表示:
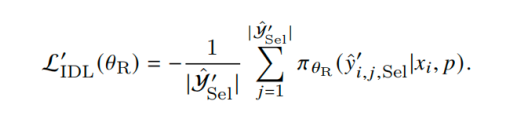
得到IDL之后,将其与RLVR的损失函数进行结合,共同对Reasoner进行训练。
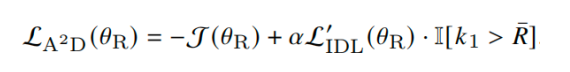
02 实验
2.1 主要实验结果
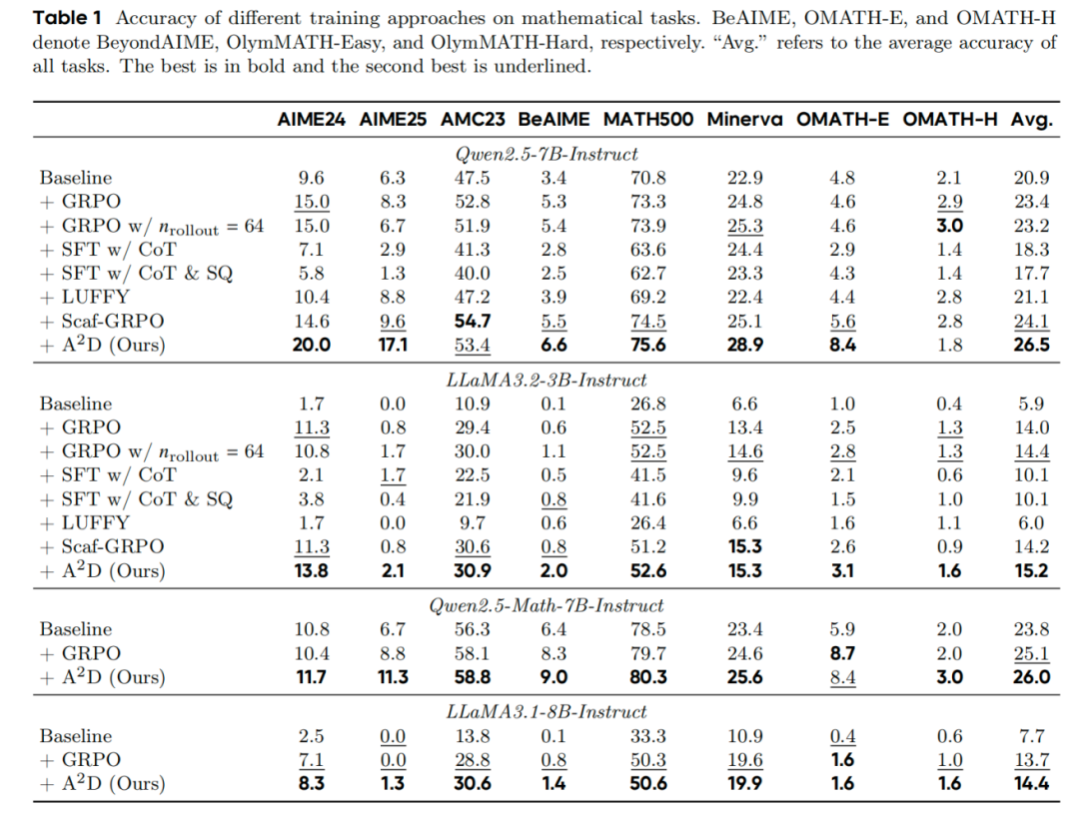
在不同的模型上应用了研究团队的算法,并和前人工作进行了比较,实验结果如上图所示。通过上述实验,分析得到以下结论:
相比于前人的方法, 能够进一步的提升模型在RLVR训练后的性能。
使用 训练得到的Decomposer,可以辅助任意模型的RLVR训练过程。
Decomposer拆解的子问题,可以辅助模型进行探索,但是无法直接提升模型推理能力。
使用外部教师模型的数据,可能会打破模型原始的推理范式,导致模型性能出现波动。
2.2 不同训练方法生成结果的Case Study

研究团队对Decomposer的训练过程进行了分析。在Quality Reward的部分,分别使用Proxy Reasoner的Pass@k指标和Pass@1指标作为奖励函数进行训练,并将其生成结果在上图中进行展示。可以总结得到以下结论:
当使用Pass@k指标作为奖励时,模型会将原问题拆解为子问题。说明子问题形式的提示,有利于提升Reasoner的探索能力(即Pass@k指标)。
当使用Pass@1指标作为奖励时,模型会生成完整的推理过程。说明完成解答形式的提示,有利于提升Reasoner的利用能力(即Pass@1指标)。
总结而言,抽象且粗粒度的提示有助于增强模型的探索能力,而具体且细粒度的提示更有利于提升模型的利用能力。
03 总结
研究团队提出的 能够提升RLVR 过程的有效性。具体而言,首先训练一个拆解器,将复杂问题拆解为多个子问题,并利用这些子问题辅助推理器的 RLVR 训练。在额外信息的引导下,推理器能够进行更有效的探索,从而在 RLVR 过程中持续提升其推理能力。
为深入理解拆解器的特性,研究团队对其训练方式及训练后的行为进行了系统分析。实验结果表明,抽象且粗粒度的提示(如子问题引导)有助于增强模型的探索能力,而具体且细粒度的提示更有利于提升模型的利用能力。总体而言,本工作探讨了如何有效引导模型进行更高效的探索。










