绑定手机号
确认绑定









智猩猩AI整理
编辑:六六
视觉逼真度的提升无疑是近期视频生成模型的一大亮点,但如何同时保证生成内容的语义、几何与身份一致性,依然是制约其发展的关键瓶颈。
为此,复旦大学联合腾讯研究团队提出了一种用于应对视频生成中一致性挑战的统一框架DCDM(Divide-and-Conquer Diffusion Model),该框架采用“分而治之”的理念,精准应对视频生成中的三大核心难题:片段内世界知识一致性、片段间相机一致性以及镜头间元素一致性。
DCDM 在 AAAI 2026 视频生成模型一致性挑战赛(CVM)的测试集上完成验证,实验结果验证了该框架有效提升了语义连贯性、相机稳定性与叙事连续性,同时也证实了系统级建模在实现可靠且可控的视频合成方面的潜力。相关成果助力团队Cinematrix荣获竞赛顶尖团队奖项。

论文链接:https://arxiv.org/pdf/2602.13637
论文标题:DCDM: Divide-and-Conquer Diffusion Models for Consistency-Preserving Video Generation
01 DCDM框架
DCDM并未将全部一致性约束强加于一个一个单体式扩散模型之中扩散模型之中,而是将问题分解为三个专用组件,每个组件明确设计用于处理一致性的一个关键维度,同时共享一个通用的视频扩散骨干网络,如图 1 所示。这样的设计使得 DCDM 能够将视频生成建立在明确的语义推理之上,从而减少片段内的矛盾与不合理的交互。
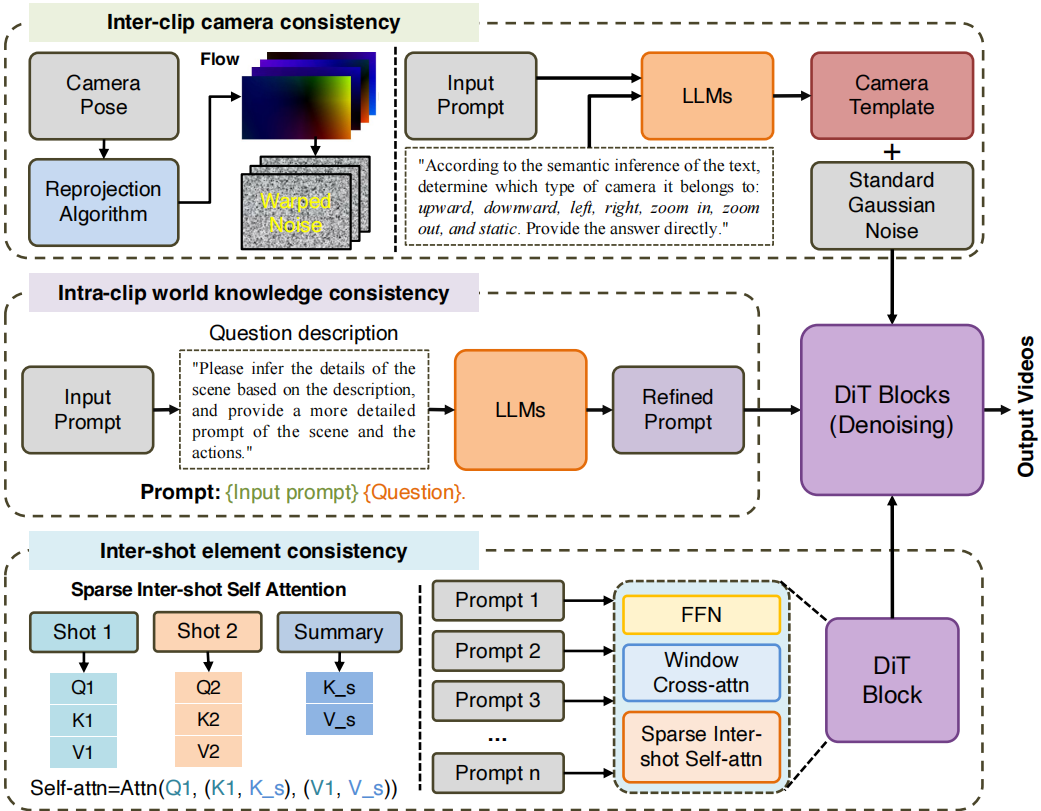
图 1 DCDM框架概览
1. 片段内世界知识一致性
片段内一致性要求视频片段中的物体、属性、动作及物理交互在语义和物理层面保持连贯。然而,用户提示常隐含关键世界知识,表述不充分。若依赖扩散模型隐式推断此类知识,易引发语义矛盾或动态不合理。
研究团队引入了显式语义提示扩展(PE)阶段,采用LLM(如Qwen3)。将输入提示 与固定指令配对,要求其详细推断场景内容与动作。大语言模型生成优化提示 :
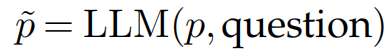
优化后的 经嵌入后作为文本条件输入DiT骨干网络。该模块将语义推理与视觉生成解耦,在不修改扩散架构的前提下,显著提升了片段内世界知识的一致性。
2. 基于相机控制的片段间相机一致性
相机运动一致性具有几何与时间双重属性,仅依靠文本控制相机行为通常效果弱且不稳定。为此,研究团队引入了时间连贯的噪声表示,在扩散采样初始化阶段依据给定相机参数进行注入。
具体而言,首先利用 Qwen3 将输入提示所描述的相机运动归类至预定义集合 (包括左移、右移、上移、下移、放大、缩小、静态等)。预测得到的运动类别 决定了相应的相机模板 ,该模板定义了标准的时域运动模式。
相机表示构建:通过在噪声空间中对高斯噪声进行时域扭曲来构建相机表示。以首帧的标准高斯噪声为起点,利用由相机内参和外参导出的重投影算子将噪声向前传播。
为保持随机性并防止噪声过度相关,将扭曲后的噪声与独立高斯噪声相混合:

其中参数 用于调节时间连贯性的强弱。整个扭曲过程及其参数均由相机模板 所指定。
噪声空间注入:与逐步施加条件的方式不同,所提相机表示仅在扩散采样初始化阶段通过替换初始噪声进行注入。此举将整个去噪轨迹锚定在一个时间连贯的噪声结构上,从而在不干扰后续扩散过程的前提下实现稳定、精准的相机运动控制。
参考图像条件化:为增强可控性,可选择使用文本到图像模型(如Z-Image)生成参考图像,并将其与相机表示一同作为条件输入至 DiT 骨干网络。该方法有效减少了外观歧义性,并提升了相机运动的执行精度。
3. 基于稀疏镜头间自注意力的镜头间元素一致性
镜头间一致性要求在多个镜头之间保持角色、环境与风格的连贯。与依赖密集时序建模的镜头内一致性不同,镜头间一致性只需选择性信息交换。对全部帧实施全注意力计算不仅冗余,且计算开销过大。
稀疏镜头间自注意力:每个镜头内部采用全双向自注意力,使查询能够关注本镜头的所有键值对,确保运动平滑与局部一致。为实现跨镜头信息交互,从每个镜头中选取少量代表性键值对(例如首帧的token)构成全局摘要,各镜头的查询同时关注本镜头的局部键值对与全局摘要:

复杂度分析:对于包含 个镜头、每镜头长度为 的视频,全注意力的复杂度为 。所提稀疏注意力将其降至约 ,其中 为每镜头的摘要token数且 。
在DiT中的集成:最终,将上述设计与用于镜头特定提示定位的窗口化交叉注意力相结合,集成至DiT模块中。该方案在确保叙事连贯性的同时,支持分钟级视频的高效生成。
02 定性结果
定性结果如图2所示,研究团队验证了DCDM在三种目标视频生成场景下的有效性。针对上述多样化任务,该模型均能持续生成具有强时间连贯性与连续性的高质量视频。

图 2 DCDM框架在片段内世界知识一致性(上方)、片段间相机一致性(中部)及镜头间元素一致性场景(下方)的定性结果。










