绑定手机号
确认绑定









智猩猩AI整理
编辑:六六
生成式世界模型的最新进展显著推动了开放世界游戏环境的创建,实现了从静态场景合成向动态交互式仿真的演进。然而,当前方法仍受限于僵化的动作模式与高昂的标注成本,难以建模多样化的游戏内交互行为及玩家驱动的动态场景。
生成式世界模型的最新进展显著推动了开放世界游戏环境的创建,实现了从静态场景合成向动态交互式仿真的演进。然而,当前方法仍受限于僵化的动作模式与高昂的标注成本,难以建模多样化的游戏内交互行为及玩家驱动的动态场景。
针对上述挑战,腾讯混元提出Hunyuan-GameCraft-2——一种面向生成式游戏世界建模的指令驱动交互新范式。该方法摒弃传统固定键盘输入的局限,支持用户通过自然语言指令、键盘或鼠标信号控制生成游戏视频内容,在虚拟世界中实现灵活且语义丰富的交互。目前,该项目已开放线上实时交互体验。




论文标题:Hunyuan-GameCraft-2: Instruction-following Interactive Game World Model
论文链接:https://arxiv.org/pdf/2511.23429
项目主页:https://hunyuan-gamecraft-2.github.io/
demo:https://hunyuan.tencent.com/game/game-craft
01 Hunyuan-GameCraft-2模型架构
Hunyuan-GameCraft-2 整体框架如图 1 所示,该模型将自然动作注入的因果架构、图像条件的自回归长视频生成以及多样化的多提示交互整合为一个统一的框架。
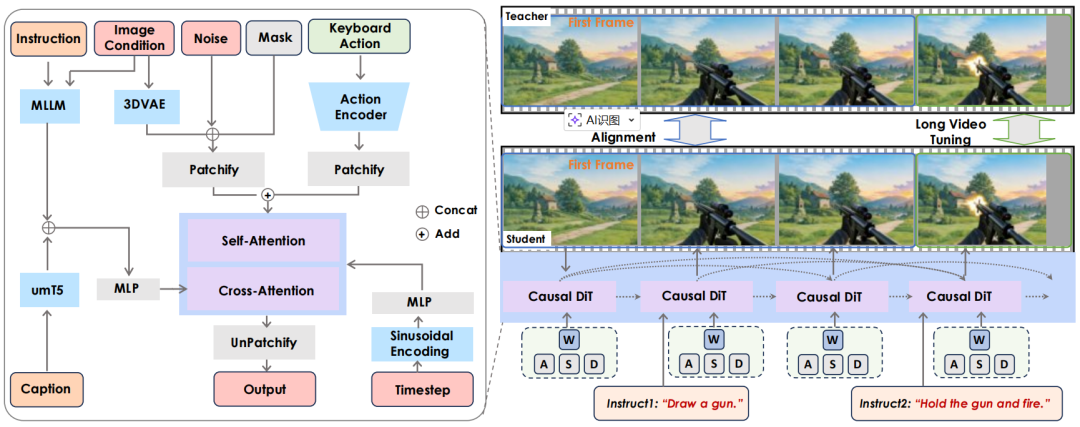
图 1 Hunyuan-GameCraft-2 的模型架构。
模型的主体架构基于一个 14B 参数的图像到视频混合专家基础视频生成模型。目标是将其扩展为动作可控的视频生成器,动作空间包括键盘输入与自由形式的文本提示。
对于键盘与鼠标信号的注入(如W、A、S、D、↑、←、↓、→、空格键等),采用 GameCraft-1 的方法,将离散的动作信号映射为连续的摄像机控制参数。训练阶段,带注释的摄像机参数被编码为普吕克嵌入(Plücker embeddings),并通过 token 添加的方式集成到模型中。推理阶段,则将用户输入转换为摄像机轨迹以推导相应参数。
02 训练流程
研究团队将自强制蒸馏技术扩展至 14B 混合专家模型,结合随机扩展调优,分四阶段训练:
1. 动作注入训练
研究团队采用流匹配与课程学习(45/81/149帧渐进训练),建立三维动态基础,拼接文本与交互指令增强感知。
2. 指令导向监督微调
基于15万合成样本,本阶段冻结摄像机编码器,仅微调混合专家模块,以增强模型对语义控制信号的响应能力。
3. 自回归生成器蒸馏
研究团队在高、低噪声混合专家架构及摄像机参数注入的基础上,对注意力机制和蒸馏方案进行了针对性改进,以优化自回归蒸馏过程的性能。
Sink Token 与块稀疏注意力:引入 Sink Token 永久保留于KV缓存,结合块稀疏注意力提升质量与速度;
蒸馏调度:按噪声层级分配差异化学习率,并根据区分高/低噪声专家的边界重新定义蒸馏去噪时间步,确保师生模型专家选择一致。
4. 随机化扩展长视频调优
基于 10 秒以上游戏视频数据集,令模型自回归生成 帧,均匀采样连续T帧窗口对齐预测分布与目标分布(真实分布或教师先验),并随机改变生成长度以增强时序鲁棒性。此外采用自强制与教师强制交错训练,增强状态恢复与时序稳定性。
03 多轮交互推理
自注意力KV缓存:推理过程采用固定长度自注意力 KV 缓存及滚动更新机制实现高效自回归生成,如图 2(a)所示。
Sink tokens 永久保留于缓存窗口起始,局部注意力通过块稀疏注意力维护前N帧上下文,兼顾自回归效率与质量稳定性。
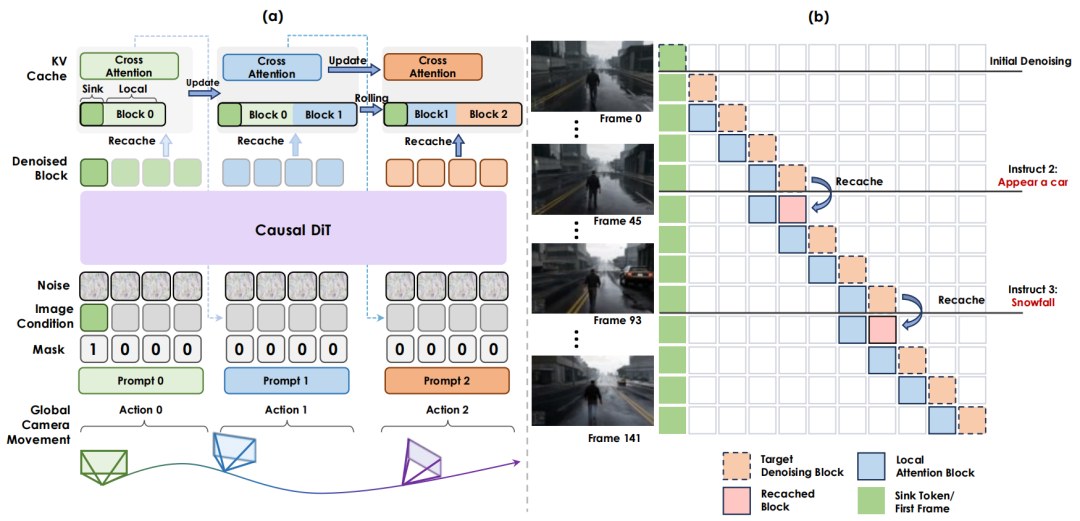
图 2 多轮交互推理。图(a)展示了用于长视频生成的分块自回归推理流程及相应的 KV 缓存更新机制。提示重缓存机制如图(b)所示。
重缓存机制:如图 2(b)所示,当接收到新交互提示时,重新计算最后一块并更新KV缓存,以最小开销保证多轮交互的准确性与稳定性。
04 实时交互加速
为进一步加速推理并最小化延迟,融入多项系统级优化:
FP8量化:在保持视觉质量的同时,减少内存带宽占用并利用GPU加速;
并行化VAE解码:支持潜帧的并行重建,缓解长序列解码中的瓶颈;
SageAttention:采用优化的量化注意力内核替代 FlashAttention,以加速Transformer计算;
序列并行:将视频 token 分布到多个GPU上,支持高效的长上下文生成。
上述技术共同将推理速度提升至16 FPS,实现了兼具稳定质量与低延迟的实时交互式视频生成。
05 交互式视频数据构建
1. 合成数据构建
为缓解交互视频数据稀缺与标注成本高的问题,研究团队提出可控的合成交互视频流水线,实现大规模自动化生产。该流水线基于初始帧,由视觉语言模型在高层指令引导下生成场景特定提示,并根据交互类型采用两种生成策略:
首尾帧策略:针对需显式状态转移的静态场景,由视觉语言模型引导图像编辑模型生成目标尾帧,实现对最终状态的强可控性。
首帧驱动策略:针对涉及显著摄像机运动的动态动作,模型仅从初始帧自由生成,避免图像扭曲,保证运动平滑与时间连续性。
针对特定交互所需初始帧的获取瓶颈,采用文本到图像模型按需合成,为流水线提供可扩展的高质量输入源。
2. 游戏场景数据整理
数据集基于 150 余款 3A 级游戏构建,涵盖环境、光照、艺术风格与摄像机视角的广泛多样性。
场景与动作感知划分:采用两阶段策略,先用 PySceneDetect 将长视频分割为6秒视觉连贯片段,再基于RAFT光流法定位细粒度动作边界,确保片段时间完整性。
数据过滤:执行三阶段过滤,基于学习的模型剔除低质量或含伪影帧;亮度过滤排除光照不佳场景;基于视觉语言模型的语义检查验证帧间一致性。
摄像机标注:采用VIPE重建6自由度轨迹,获取逐帧平移旋转估计,为摄像机感知模型训练提供精确元数据。
结构化描述:设计双组件方案:标准描述 由视觉语言模型生成,描述静态内容;交互描述 捕获相邻片段状态转移,计算为语义差异:
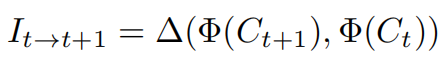
06 评估
为全面评估可控视频生成性能,研究团队构建了一个围绕环境交互、主体动作、实体与对象出现三个核心交互维度组织的测试集。
研究团队还提出了一个基于视觉语言模型的六维度自动评估协议 InterBench:交互触发率(Trigger)评估动作是否成功启动;提示-视频对齐(Align)评估静态场景和动态动作与完整提示之间语义保真度;交互流畅性(Fluency)度量交互过程的时间自然度与视觉连贯性;交互范围准确性(Scope)检验效果空间范围是否恰当;终态一致性(EndState)评估是否收敛至稳定正确状态并持续;对象物理正确性(Physics)评估交互主体与对象的物理合理性。
表 1 在InterBench协议框架下,与当前最先进的对比方法进行的定量性能评估结果。
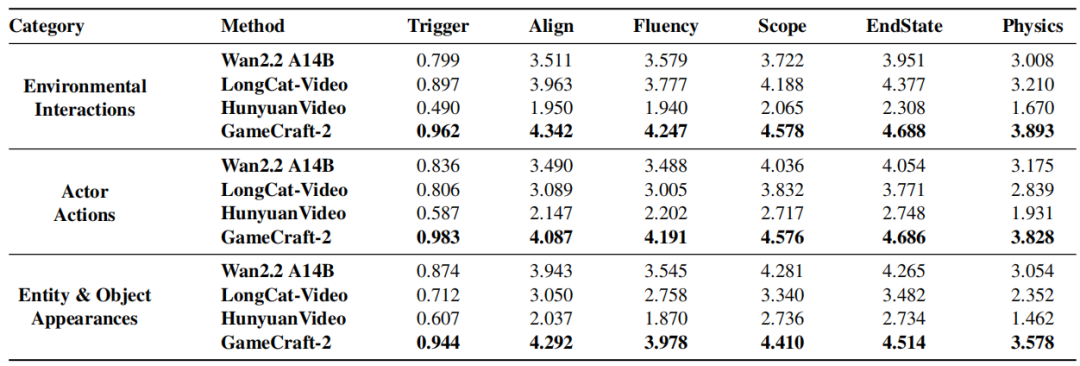
表 1 展示了三个交互类别的定量结果。按类别分析显示,GameCraft-2 的优越性首先体现在极高的交互启动成功率:环境交互触发率达0.962,主体动作达0.983,显著超越所有基线。在交互保真度方面,模型在物理真实感上表现突出,环境交互物理性维度领先次优模型0.683分,实体与对象出现类别领先超0.52分。同时,在时间连贯性与终态稳定性上也有显著提升,主体动作的流畅性与终态得分分别提高+0.70和+0.63。综上,GameCraft-2不仅能可靠触发交互,还能以高保真的语义、动态和物理一致性进行渲染。如图 3 所示,针对每个维度,通过 GameCraft-2 的高分示例(右侧)与基线模型的低分示例(左侧)进行对比,直观展示评分标准。

图 3 InterBench 六个维度的定性示例。
图 4 显示,基线模型在复杂交互中缺陷明显,相比之下,Hunyuan-GameCraft-2在所有类别中保持高保真度与一致性;角色动作连贯,抓取操作精准,状态稳定;新物体结构完整、融合自然。模型还能泛化至训练外概念,验证其强大泛化能力。
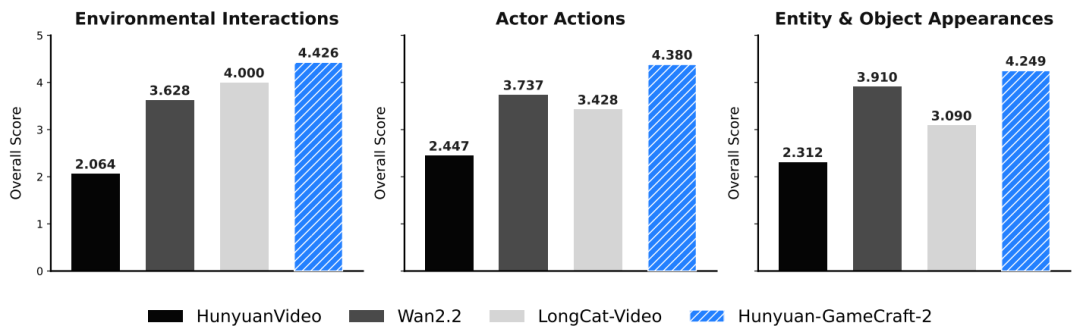
图 4 与基线模型在交互方面的对比结果。










