绑定手机号
确认绑定









智猩猩AI整理
编辑:没方
交互式与自主型人工智能系统的快速发展标志着我们已迈入智能体时代(Agentic Era)。在软件工程、计算机使用等复杂智能体任务上对智能体进行训练和评估,不仅需要高效的模型计算能力,还需要能够协调大量智能体与环境交互的复杂基础设施。然而,目前尚无开源基础设施能有效支持此类复杂智能体任务的大规模训练与评估。
为此,阿里千问团队提出了面向智能体-环境工作负载的超大规模分布式编排系统MegaFlow,可实现高效调度、资源分配和细粒度任务管理。MegaFlow将智能体训练基础设施抽象为三个通过统一接口进行交互的独立服务:模型服务、智能体服务和环境服务,从而在不同的智能体-环境配置中实现独立扩展与灵活的资源分配。
在超过130,000 条生产任务记录上进行综合评估,与传统的集中式方法相比,MegaFlow成功突破了关键基础设施瓶颈,可降低 32% 的成本,并能稳定扩展至10,000 个并发任务,其生产环境有效性已在超过200万次智能体训练执行中得到验证。通过建立统一的 API 并消除编排层面的性能瓶颈,MegaFlow为超大规模智能体训练研究提供了可直接用于生产的基础平台,填补了新兴Agentic AI领域的关键基础设施空白,使得开发大规模的复杂AI智能体成为可能。

论文标题:MegaFlow: Large-Scale Distributed Orchestration System for the Agentic Era
论文链接: https://arxiv.org/pdf/2601.07526
01 方法
传统智能体训练方法在简单任务上表现良好,例如单轮函数调用和基础问答任务。然而,这些方法难以应对大规模复杂多步骤任务训练所必需的海量并发智能体-环境交互协调带来的挑战。核心挑战不仅在于计算能力(现代分布式计算框架已较好地解决了模型训练与推理的可扩展性问题),更在于大规模智能体训练工作负载所特有的动态且相互依赖的复杂流程协调问题。
研究团队在软件工程和计算机使用自动化等复杂任务上训练智能体,该经验揭示了大规模智能体训练可扩展性面临三大关键基础设施瓶颈:
安全隔离限制:复杂的智能体训练需要容器化环境来为智能体-环境交互提供安全隔离的执行上下文。然而,典型训练集群的安全策略禁止任意容器的执行,导致大规模智能体训练需求与现有计算基础设施之间存在根本性不兼容。
存储可扩展性瓶颈:每个复杂的智能体任务实例(task instance)都需要配套的容器化环境,其中包含特定的软件依赖和执行上下文。即便是规模相对较小的数据集,如 SWE-bench 和 SWE-Gym,其相关的容器镜像也需超过 25TB 的存储空间。随着训练任务集规模和多样性进一步扩大,存储需求将急剧增长,带来难以承受的基础设施成本和管理负担。
计算吞吐量瓶颈:容器化智能体-环境交互资源消耗极大,严重限制了并发训练的吞吐量,从而阻碍了大规模智能体训练所需的巨大并行能力。
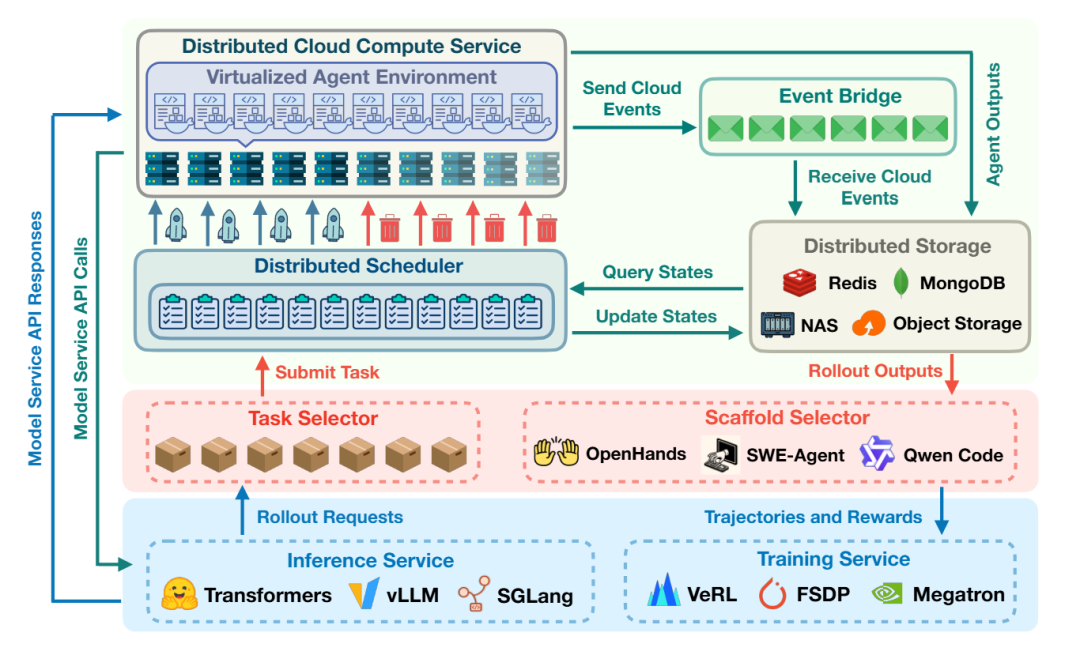
图2:MegaFlow 架构。(底部)模型服务通过多种推理引擎和分布式框架提供推理与训练能力。(中间)智能体服务负责协调执行策略、集成智能体框架,并管理经验反馈循环。(顶部)环境服务提供容器化执行环境并处理分布式任务调度。
如图2所示,研究团队提出的大规模分布式编排系统MegaFlow,通过解耦模型服务、智能体服务和环境服务的三层架构,有效应对了智能体训练基础设施可扩展性所面临的挑战。
1)环境服务是最耗资源的组件,负责智能体任务的实际执行。该服务在分布式系统中对任务进行排队,并采用智能调度机制监控资源可用性,将任务分发至云计算实例。每个实例通过容器化环境并行执行多项智能体任务,为智能体与环境的交互提供隔离的执行上下文。
2)智能体服务作为智能协调器,根据任务需求管理智能体的执行策略。它集成了多种智能体框架(如 OpenHands、SWE-Agent和Qwen Code),可适配不同任务类型(包括训练、评估或数据合成),并在指定数据集上协调 rollout 执行。该服务处理 rollout 输出,汇总评估指标,并将经验数据反馈给模型服务以进行训练迭代。
3)模型服务负责处理智能体的计算部分,通过多种推理引擎(如 Transformers、vLLM和 SGLang)提供推理能力,同时借助分布式训练框架(包括 VeRL、FSDP和 Megatron)支持训练操作。该服务专注于模型计算与参数更新,并对智能体-环境交互的复杂性进行抽象。
MegaFlow 的模块化架构允许各组件根据其特定的计算需求进行独立优化与扩展。
MegaFlow 通过统一的 API 编排这三个服务之间的交互,管理智能体训练的完整生命周期:从接收请求、配置环境、通过事件驱动更新监控训练进度以及收集结果以供下游处理。该系统利用云服务实现弹性计算、实时监控和分布式存储。
MegaFlow架构中涵盖五大核心组件,这些组件协同工作以提供可扩展、高容错的智能体训练工作负载编排能力。
(1)任务调度器
MegaFlow的核心是一个高性能异步调度器,支持大规模并发任务处理。系统采用先进先出(FIFO)调度策略,在保持简洁性与可预测性的同时,能够满足工作负载需求。
该调度器采用针对性资源分配策略智能处理两类任务:
对于临时任务,系统采用临时计算模式,接收到任务请求后立即分配专用计算实例,执行单一任务后立即释放资源,既消除资源争用又实现完全隔离;
对于持久任务,调度器维护一个持久计算实例池,通过池化分配机制高效复用资源,同时借助容器化技术保障任务间的隔离性。
(2)资源管理器
资源管理子系统采用分布式协调机制,实时维护系统状态与资源可用性的可见性。该部分设计未采用复杂的资源监控与分配算法,而是通过标准化计算实例实施统一资源分配策略。这种标准化不仅简化了调度决策、提升资源可预测性,而且与容器化工作负载特性高度契合,每个实例通常仅执行单一智能体任务。
系统通过三层限制机制实现精细的并发控制:
用户指定参数:限制模型服务 API 的调用频率,防止下游瓶颈;
分布式信号量:确保任务执行数量不会超出可用计算容量;
管理配额:控制资源使用,既防止系统滥用又保障公平的资源共享。
(3)环境管理器
通过将容器生命周期操作委托给成熟的开源智能体框架,使 MegaFlow 能专注于编排与协调。系统将所有必需容器镜像预先部署至云注册服务,借助高带宽内网实现快速部署。
环境隔离采用分层设计:每个计算实例提供资源隔离,而实例内的容器化则提供进程与文件系统隔离。这种双层隔离机制确保智能体操作(包括代码编辑、命令执行和文件系统修改)完全限定在指定环境内。
(4)事件驱动监控
MegaFlow利用云事件服务,通过两大关键事件流实现响应式系统行为:
实例生命周期事件:使系统能够追踪计算实例状态转换,确保任务仅被分派至完全就绪的实例;
任务完成事件:提供任务结果的实时通知,支持即时资源回收与结果处理。
该事件驱动架构消除了昂贵的轮询开销,同时对状态变化实现近乎即时的响应。系统还辅以直接 API 调用以获取详细的任务执行信息,在实时响应与全面监控之间取得最佳平衡。
(5)数据持久化
系统架构通过专用存储系统,将运行时数据与结果产物的关注点分离:
运行时元数据(包括任务定义、执行状态和计算实例信息)由具备模式校验与类型安全的文档数据库管理;
任务队列基于内存存储系统实现,利用高性能操作加速任务分发。
智能体执行产物持久化存储至云对象存储,为轨迹数据、评估结果和训练产物提供持久可扩展的存储。这种分离设计使得智能体服务能够异步获取结果,同时在执行高峰期保持系统响应能力。
02 评估
由于目前缺乏可比较的大规模智能体训练编排基础设施,研究团队通过系统比较以下执行策略建立基准:
高规格集中式(High-Spec Centralized):采用高配置机器(208核CPU、3TB内存、1 Gbps网络带宽),每个实例最高可持续并行处理50个并发任务。
MegaFlow 分布式(MegaFlow Distributed):采用标准化的 8 核 CPU、16GB 内存实例(每个实例网络带宽为 100 Mbps),配合动态弹性伸缩(dynamic elastic scaling),每个实例处理1个并发任务。
评估基于生产部署记录,包含超过13万个临时执行任务和超过200万个持久执行任务。实验中,集中式方法最多使用40个高规格实例,分布式方法最多使用10,000个标准化实例。性能指标采用自助采样法计算(每个数据点100次迭代)并给出95%置信区间。所有实验均在阿里云上进行,除非另有说明,高规格集中式方法使用ecs.re6.52xlarge实例,分布式方法使用ecs.c8a.2xlarge和ecs.c8i.2xlarge实例。
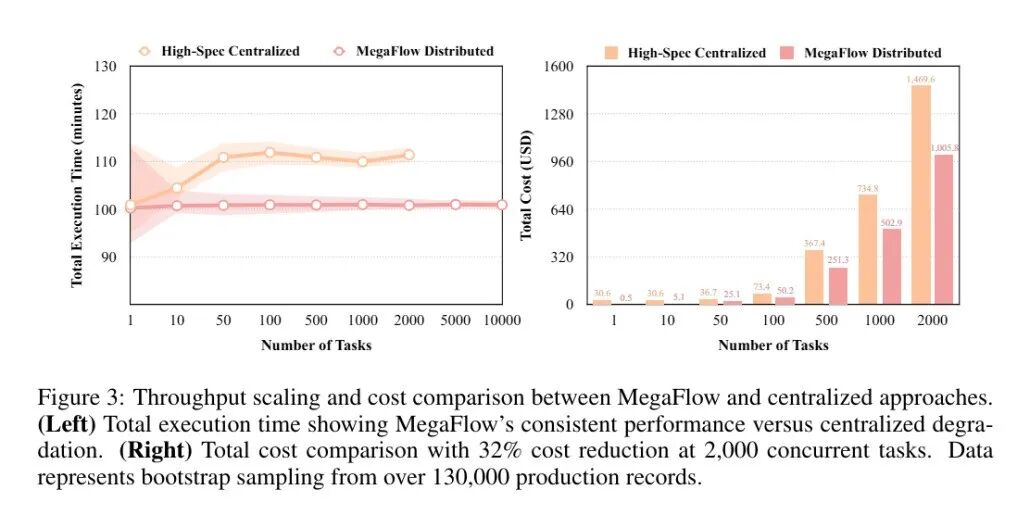
(1)性能与可扩展性
图3展示了 MegaFlow 相较于传统集中式方法的显著优势。MegaFlow 在任务数量从 1 到 10,000 的范围内,始终保持约 100 分钟的稳定执行时间;而高规格集中式方法因资源争用瓶颈导致执行时间从100分钟增加至110分钟。集中式方法在容器镜像拉取时面临网络带宽拥堵问题,并在初始化阶段遭遇资源竞争。MegaFlow的分布式架构通过为每个任务分配专用资源,有效消除了这些瓶颈。
集中式方法存在根本性的可扩展性限制:受限于实例可用性(最多40个高规格实例),其并发任务数被限制在2,000个以内。MegaFlow采用标准化实例,可实现最高10,000个实例配置,展现出更卓越的弹性扩展能力。
(2)成本效益
在处理2,000个任务时,MegaFlow实现了32%的成本降低(1,005美元对比1,470美元),且规模越大成本优势越显著。除直接节约成本外,MegaFlow还消除了传统方法因资源可用性限制而无法扩展至大规模工作负载的瓶颈。
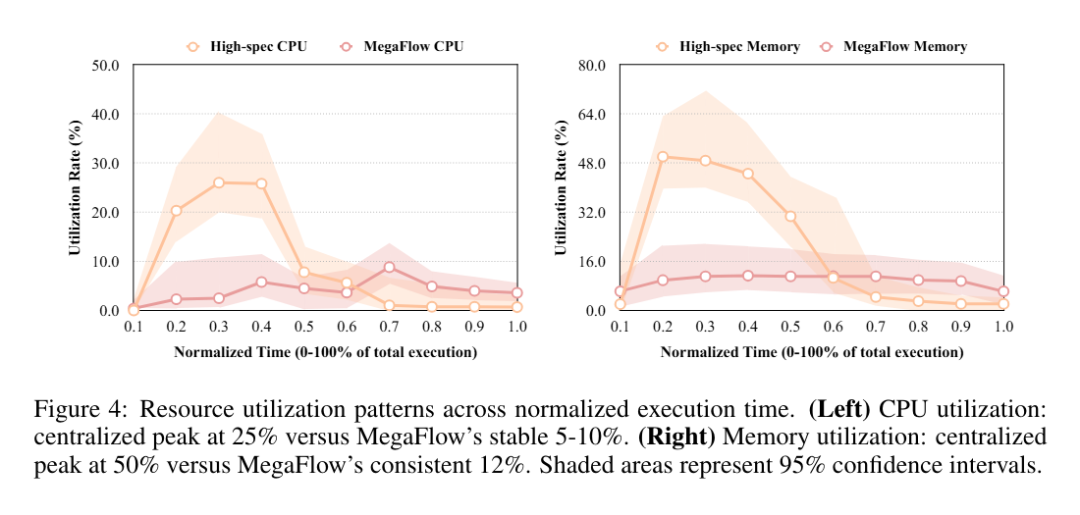
研究团队通过分析任务执行全生命周期中的资源利用模式,评估不同架构方法的效率。图4展示了两类方法在标准化执行时间内的CPU与内存利用率对比。
资源利用模式分析
资源利用模式揭示了集中式与分布式方法之间的根本差异。高规格集中式实例表现出明显的资源使用峰值:在执行初期(前30%时间段内)CPU 利用率最高达到25%,随后迅速下降至接近零的水平;内存利用率呈现类似趋势,在执行中期(总时长的20%–40%)达到50%的峰值,之后急剧下降。
相比之下,MegaFlow分布式架构在整个执行周期中保持稳定的资源利用。CPU利用率全程维持在5-10%的平稳区间,内存利用率则始终保持在12%左右,波动极小。
上述对比鲜明的利用模式展示了显著的效率差异。集中式方法呈现出典型的“突发性”资源消耗特征,并伴随大量空闲时段,尽管使用了高性能硬件,但整体资源效率仍然低下。此外,集中式方法较大的置信区间表明其资源需求波动剧烈,给容量规划带来挑战。
MegaFlow 稳定的资源利用模式配合较窄的置信区间,体现出可预测的资源消耗行为,从而支持更高效的容量规划与资源分配。虽然单个实例的峰值利用率较低,但分布式模型通过在整个执行生命周期中保持一致的资源使用,实现了更优的整体资源效率。
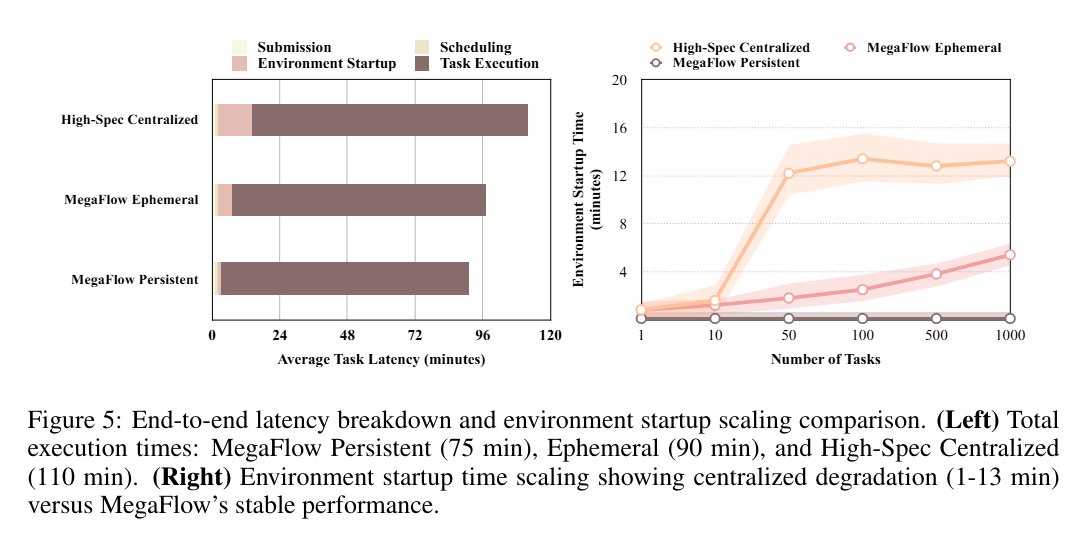
研究团队通过完整任务执行流程分析来识别性能瓶颈,并验证混合执行模型设计。图5展示了不同执行阶段的延迟分解(latency breakdown)与环境启动的扩展特性。
延迟分解分析
MegaFlow持久执行模式以约75分钟的总延迟实现最优性能,其基础设施开销极低。临时执行模式总耗时约90分钟,需额外承担环境启动成本;而高规格集中式方法因各执行阶段均存在资源争用,延迟最高达110分钟。
环境启动扩展性
环境启动时间展现了执行策略间关键可扩展性差异。高规格集中式方法的启动时间严重衰减:由于容器镜像拉取和初始化阶段的资源争用,单任务时仅需1分钟,但在1,000个并发任务下激增至13分钟。相比之下,MegaFlow 的临时执行模式启动时间仅从1分钟增长至6分钟,而持久执行通过环境复用,在所有并发级别下均保持低于1分钟的稳定低启动时间。
扩展模式揭示了多重瓶颈来源:MegaFlow临时模式启动时间的平缓增长表明云容器注册服务在高并发拉取时虽出现性能衰减,但仍保持相对稳定;而集中式方法启动时间的急剧攀升则说明主要瓶颈在于本地资源限制(高规格实例内部的网络带宽限制与资源竞争),而非云服务限制。此分析印证了MegaFlow分布式方法通过为任务分配专用资源,以规避本地资源瓶颈的有效性。
混合执行模型验证
上述结果验证了混合执行模型的设计原则。持久执行通过环境复用为持续性工作负载提供最优性能,而临时执行则在适度开销下提供更强的隔离保障。MegaFlow 能够根据任务特性灵活选择执行模式,从而根据具体工作负载需求,在性能与资源利用率之间实现最佳平衡。










