绑定手机号
确认绑定









智猩猩AI整理
编辑:没方
执行复杂的终端(即命令行)任务对开源大语言模型(LLM)仍是一项重大挑战,其瓶颈主要来自两个根本限制:(i)高保真、可执行的训练环境极其稀缺:基于真实代码仓库构建的环境缺乏多样性与可扩展性,而由大语言模型合成的轨迹则容易产生幻觉。(ii)标准的指令微调方法通常依赖专家轨迹,这类轨迹极少包含小型模型常犯的简单错误。这导致分布偏差(distributional mismatch),使学生模型在面对自身运行错误时缺乏恢复能力。
为此,加州大学联合AMD等提出TermiGen,专为开发鲁棒终端智能体而设计的端到端数据生成方案。TermiGen 首先通过一个迭代式的多智能体优化循环,生成功能有效的任务及对应的 Docker 容器;随后采用生成器-评判器(Generator-Critic)协议,在轨迹收集过程中主动注入错误,合成包含错误修正环节的训练数据。研究团队基于 TermiGen 生成数据集微调得到 TermiGen-Qwen2.5-Coder-32B 模型,在 TerminalBench 上达到 31.3% 的通过率,实现32B规模新SOTA, 并超过 o4-mini 与 Codex CLI 的组合11.3%。此外,研究团队开源了 3500+ 个验证过的 Docker 训练环境。

论文标题:TermiGen: High-Fidelity Environment and Robust Trajectory Synthesis for Terminal Agents
论文链接:https://arxiv.org/pdf/2602.07274
项目地址:https://github.com/ucsb-mlsec/terminal-bench-env
01 方法
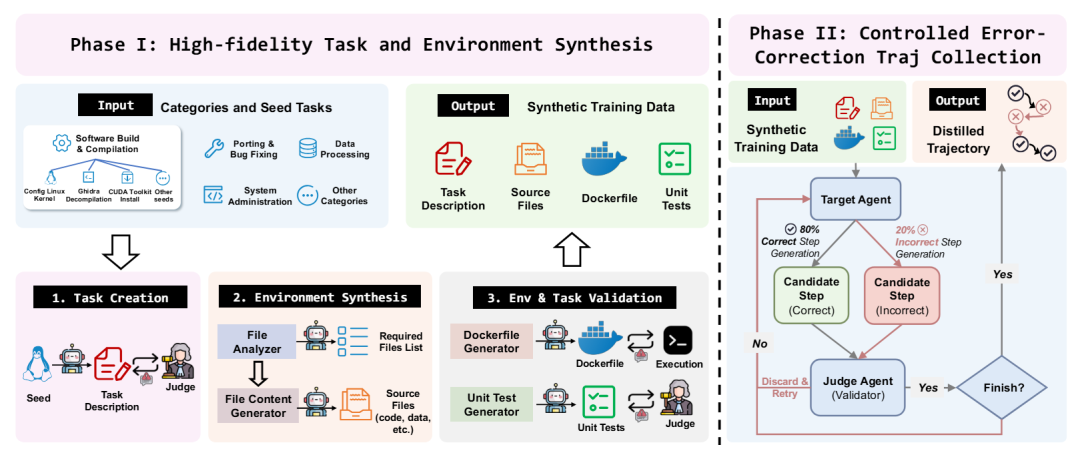
图2: TermiGen的整体流程。第一阶段通过迭代优化在Docker容器中生成多样且功能有效的任务。第二阶段通过在执行流程中主动注入错误,合成具有鲁棒性的专家轨迹,使模型能够学习错误诊断与恢复能力。
(1)TermiGen整体流程
TermiGen的整体架构如图2所示,旨在训练具备自我修正能力(self-refinement capability)的高效终端智能体。包含两个核心阶段:
第一阶段:高保真任务与环境合成
研究团队通过一个多智能体框架,将生成过程分解为多个可控阶段。
(i)在结构化任务分类体系(涵盖三个层级,共11个类别)的引导下,指示大语言模型生成多样化的任务种子(task seeds),以确保广泛覆盖各领域。这些种子是简洁、高层次的目标描述。
(ii)采用提议者-评估者(Proposer-Evaluator)架构,将这些种子扩展为完整规范的任务(例如,补充详细的输入/输出要求)。在此循环中,评估者依据预定义标准对生成内容进行验证,并提供反馈以引导迭代优化。
(iii)通过一个结构化工作流,将这些文本描述转化为可执行的 Dockerfile(构建 Docker 镜像的脚本文件)。鉴于这些任务领域的复杂性,要确保环境正确性与任务有效性并非易事。为此,研究团队构建了一个两阶段自动化验证流水线以保障数据质量:
为保证环境可执行性,研究团队实现了迭代式 Docker 构建循环:当构建失败时,系统会自动诊断错误并进行修正;
为验证任务可解性,采用生成器—裁判(Generator-Judge)框架:生成智能体负责合成初始单元测试,裁判智能体则对其进行迭代验证与优化,确保测试准确反映任务目标并能提供可靠执行反馈。
第二阶段:受控的错误—修正轨迹收集
环境验证完成后进入轨迹合成阶段。为应对标准蒸馏中学生模型在面对自身运行错误时缺乏恢复能力问题,研究团队引入主动错误注入机制。该机制采用生成器—评判器(Generator-Critic)架构,从包含五类常见失败模式的分类体系中随机采样,实现可控的错误注入。
生成智能体采用混合策略:每个步骤都以一定概率决定是要继续沿最优路径执行,还是主动偏离路径以触发特定错误(例如,在命令中调用不存在的参数)。
评判智能体则负责验证动作与意图之间的一致性,确保所注入的错误能触发具有信息量的反馈(如标准错误输出),同时正确步骤仍能有效推进任务。
关键的是,每当策略决定返回正确路径时,生成智能体会被强制要求诊断前一步的失败原因,并生成相应的修正方案。该过程生成的轨迹中嵌入了大量显式的“错误→诊断→恢复”循环,从而为模型提供丰富的学习信号。
(2)实现与数据统计
第一阶段和第二阶段均采用 Claude-4.5-Sonnet 作为智能体的主干模型。在轨迹收集过程中,研究团队基于 Terminus 架构,实现了一个极简的终端智能体 BashAgent。该智能体通过原生 bash shell 与 Docker 容器交互,每轮生成ReAct风格的响应(即推理轨迹后接bash命令)。
该合成流水线最终生成了超过 3,500 个经过验证的环境,各任务类别分布均衡。基于这些环境,研究团队构建了一个包含 3,291 条轨迹的语料库。该数据集既包含成功的解决方案,也包含未完成的尝试。值得注意的是,这些轨迹展现出长周期特性:平均每条轨迹包含 25.5 轮交互,总长度达 8,722 个 token,充分反映了真实系统任务的复杂性。
如图3所示,该数据集广泛覆盖各类终端操作,共使用420个命令行工具,涵盖16个功能。其中既包括标准工具集(如文件与文本处理),也涉及安全取证、网络运维、高性能计算等专业领域的专用软件。
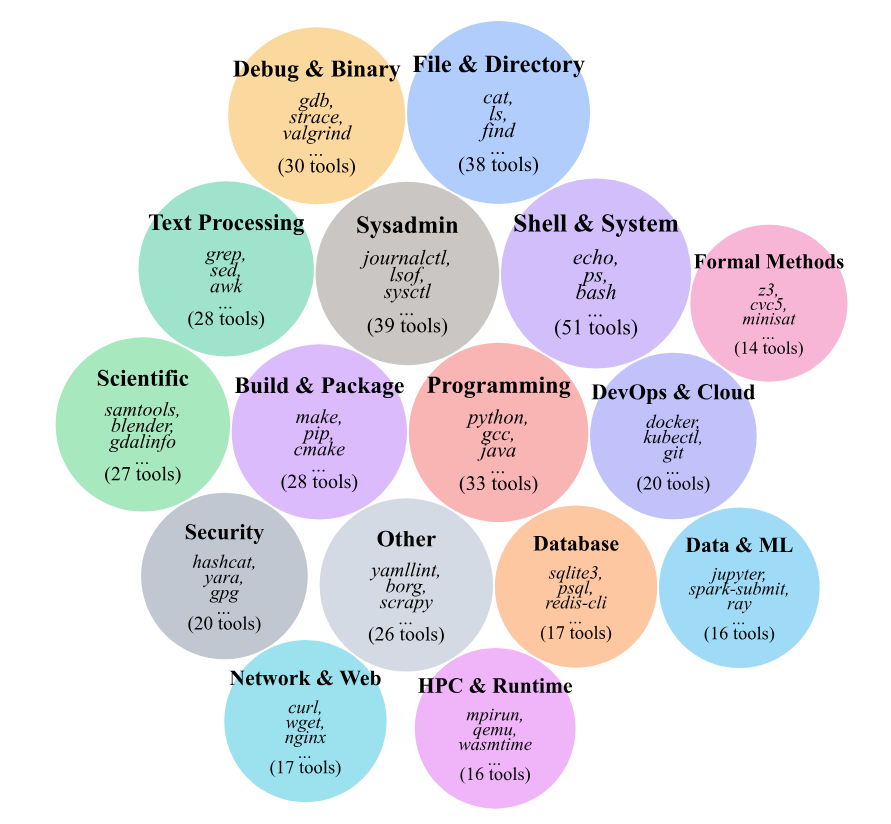
图3. 420 个命令行工具在 16 个功能类别中的分布情况。
02 评估
表1. TermiGen 与基线方法在 TerminalBench 1.0 上的对比。
结果按通过率(pass rate)从高到低排序。带 * 的结果为作者报告的数据。

表1将研究团队的框架与当前开源的 SOTA 模型以及闭源前沿模型进行了对比。TermiGen-Qwen2.5-32B 在 TerminalBench 上达到了 31.3% 的通过率,刷新了开源模型 SOTA 记录。显著超越了现有的微调智能体 Reptile(18.9%)和 TerminalAgent(15.5%)。
尤为关键的是,与未经微调的基础模型相比,TermiGen 带来近 25% 的性能提升。更值得注意的是,尽管研究团队的 32B 模型参数量远小于某些闭源模型,且未使用网页浏览、记忆等额外工具,其性能仍以 11.3% 的优势超越了能力较强的闭源模型o4-mini 与 Codex CLI 组合(20.0%)。
虽然与顶尖闭源推理模型(如采用 Claude-4.5-Sonnet 的 Apex2,达 64.5%)之间仍存在差距,但 TermiGen-Coder-32B 已达到 GPT-5-Codex 性能的 73.1%。这一结果表明,经过高保真错误修正数据训练的专用模型,能够媲美大规模前沿闭源模型的推理能力。










