绑定手机号
确认绑定









智猩猩AI整理
编辑:宁宁
大模型推理能力不断提升,但也带来一个关键问题:当模型生成多个候选答案时,如何可靠判断哪个答案真正正确? 现有奖励模型大多仍停留在打分或单轮评价阶段,容易被表面合理但实际错误的推理过程误导;在数学、代码等复杂任务中,如果缺乏工具调用和外部验证,也容易出现误判。
针对这一问题,复旦大学、字节跳动 Seed、华中科技大学、香港大学等团队联合提出 AgentV-RL,将奖励建模从传统“静态打分”升级为 Agentic Verifier。该方法通过正向验证与反向验证两个智能体协同工作,让验证器能够拆解推理步骤、调用工具并进行多轮审查,从而给出更可靠、可解释的判断。
实验结果显示,Agentic-Verifier-Qwen3-4B 在多个数学推理基准上取得显著提升:在 MATH500 上最高达到 79.0%,在 AIME24 BoN@128 设置下达到 53.3%,并相较此前最优 outcome-level reward model 取得最高 25.2 个百分点提升,甚至超过参数规模更大的 INF-ORM-Llama3.1-70B。

论文标题:AgentV-RL: Scaling Reward Modeling with Agentic Verifier
论文链接:https://arxiv.org/abs/2604.16004
GitHub 仓库地址:https://github.com/JiazhengZhang/AgentV-RL
AgentV-RL 的核心思路很直接:验证答案不能只看最终结果,也不能只凭模型内部推理,而应该像人类审稿一样,从多个方向反复检查。
为此研究团队提出了 Agentic Verifier 框架。它包含两个互补的智能体:Forward Agent 和 Backward Agent。
(i)Forward Agent 负责正向验证。它从题目条件出发,沿着候选解法的推理过程一步步检查,判断每一步推导是否正确,前一步是否足以推出后一步。它主要解决的是“推理链是否成立”的问题。
(ii)Backward Agent 负责反向验证。它从最终答案或结论出发,反向追溯到题目条件,检查答案是否满足所有约束,是否遗漏必要证明,是否存在看起来合理但其实不符合题意的情况。它主要解决的是“结论是否真正站得住”的问题。
这两个智能体都遵循统一的 Plan-Validate-Verdict 流程:先将复杂解法拆解为可验证的原子步骤,形成明确检查计划;再逐步检查每个子步骤,并在涉及复杂计算、组合枚举或数值推导时调用 Python 等外部工具;最后综合所有检查证据,输出 True / False 判断,并用 True token 的 logits 作为置信分数。
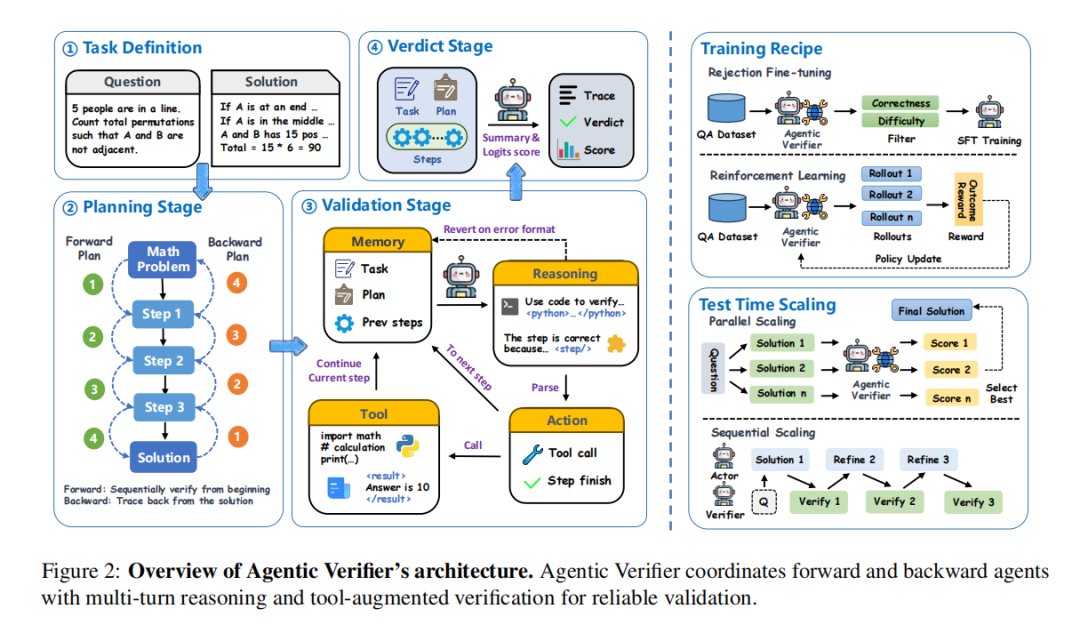
图注:Agentic Verifier 总体框架。方法由任务定义、规划阶段、验证阶段和最终裁决阶段组成,并结合训练流程与 Test-Time Scaling 场景。
在这个框架中,正向验证强调“充分性”,即推理是否能从条件推出结论;反向验证强调“必要性”,即结论是否真的满足题目要求。二者结合后,可以更有效地发现隐藏在中间步骤、计算细节和题目约束中的错误。
不过,直接部署多智能体框架会带来较高成本。为此研究团队进一步提出 AgentV-RL 训练流程,将这种多智能体验证能力蒸馏到一个单一 LLM verifier 中。
研究团队先基于 Polaris、DeepScaleR-40K、AReaL-boba-106k 等公开数学推理数据集构造候选解法,并过滤掉全部正确或全部错误的过易 / 过难样本。随后,让 LLM 扮演 Forward Agent 或 Backward Agent,自动生成带工具调用的验证轨迹;只有当最终判断与真实标签一致时,该轨迹才会被保留。
在训练阶段,模型先通过 SFT 学习高质量的多轮验证行为,再通过 GRPO 强化学习进一步优化验证策略。AgentV-RL 训练的不是一个简单打分器,而是一个具备规划、检查、工具调用和最终裁决能力的验证器。
研究团队主要围绕两类 Test-Time Scaling 场景展开实验:并行扩展和顺序扩展。
在并行扩展中,研究团队采用 Best-of-N 设置。Actor 模型先为同一个问题生成 N 个候选答案,Agentic Verifier 对每个候选答案进行验证和打分,最终选择置信度最高的答案作为输出。
实验数据集包括 GSM8K、MATH500、Gaokao2023 和 AIME24。对比对象涵盖普通文本推理模型、Outcome-level RM 和 Process-level RM。结果显示,Agentic-Verifier-Qwen3-4B 在多个数据集上表现突出,如下图所示。在 MATH500 上,BoN@32、@64、@128 分别达到 73.8%、76.2%、79.0%;在 Gaokao2023 上最高达到 57.4%;在 AIME24 上,BoN@128 达到 53.3%,明显优于多种更大规模模型和奖励模型基线。
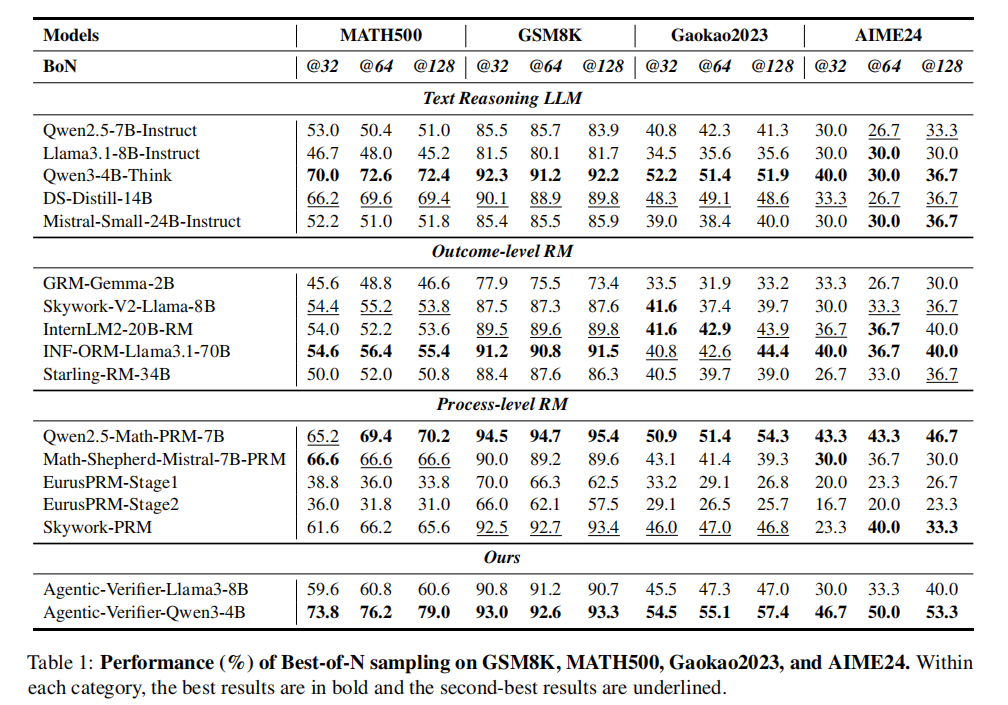
图注:Best-of-N 采样实验结果。Agentic-Verifier-Qwen3-4B 在 MATH500、GSM8K、Gaokao2023、AIME24 上取得强表现,其中 MATH500 BoN@128 达到 79.0%,AIME24 BoN@128 达到 53.3%。
这说明 Agentic Verifier 的提升并不是单纯来自模型参数规模,而是来自验证机制本身。它可以通过正反向检查和工具调用,识别普通 reward model 容易忽略的细微错误。
在顺序扩展中,研究团队测试 verifier 能否帮助 actor 修改答案。流程是:actor 先生成初始解法,verifier 给出 critique,actor 根据反馈进行修正,并可持续迭代多轮。
结果如下图显示,Agentic-Verifier-Qwen3-4B 在第一轮修正中就能带来明显提升。例如在 MATH500 上,第一轮修正后准确率达到 84.2%,错误答案被修正的比例达到 41.6%,而正确答案被错误修改的比例只有 0.6%。这说明它不仅能判断答案对错,还能给出对修改真正有帮助的反馈。
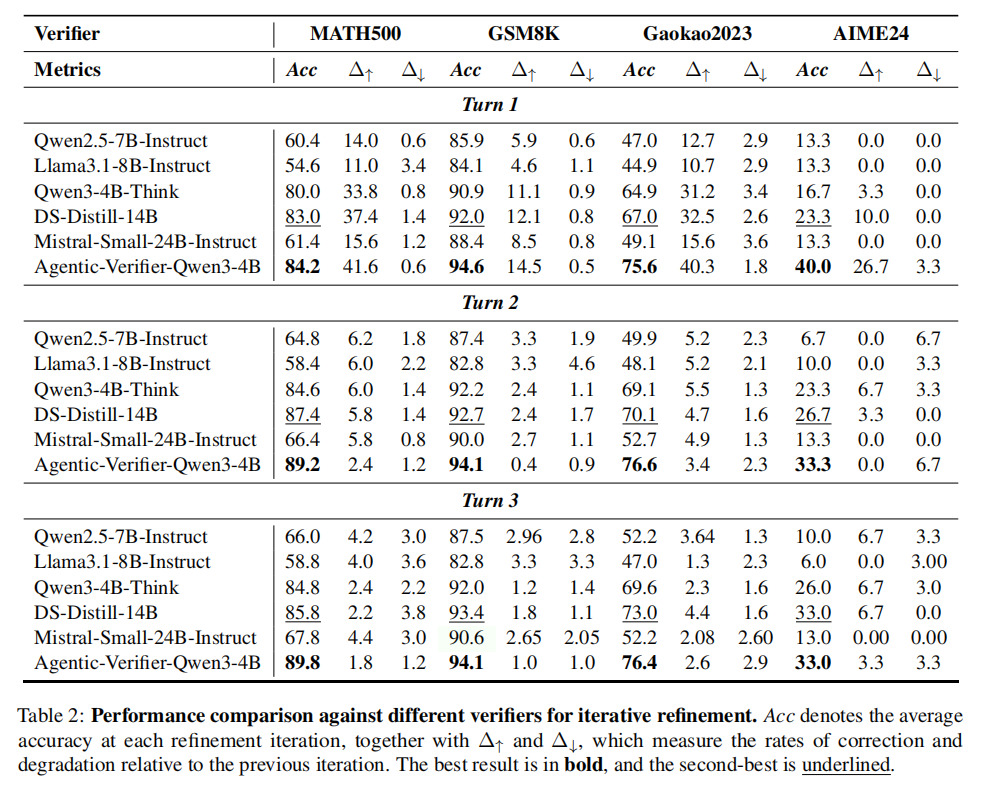
图注:多轮迭代修正实验结果。Agentic-Verifier-Qwen3-4B 在第一轮即可显著提升 actor 表现,例如 MATH500 准确率达到 84.2%,错误答案修正率达到 41.6%,错误改写率仅为 0.6%。
研究团队还进行了多组分析实验。
(1)双向结构消融。Forward-only 和 Backward-only 都能取得不错效果,但完整 Agentic Verifier 表现最好。这说明正向检查和反向追溯具有互补性:前者关注推理链是否成立,后者关注最终结论是否满足题目约束。
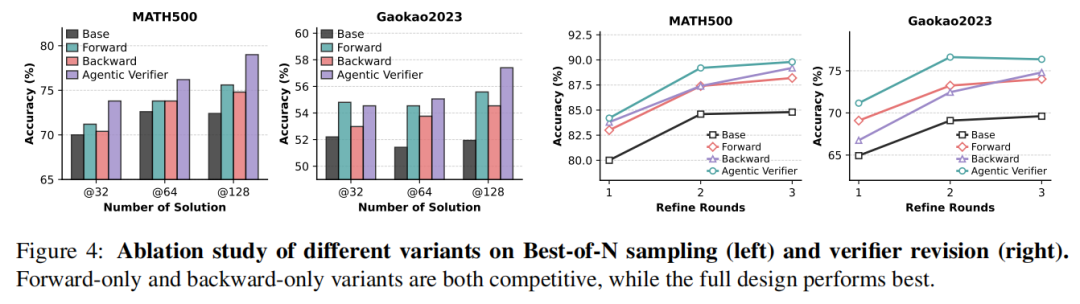
图注:双向结构消融实验。Forward-only 和 Backward-only 均有一定效果,但同时使用正向验证和反向验证的完整 Agentic Verifier 表现最好。
(2)训练流程分析。Train-free 版本已经能体现 agentic 框架的优势;SFT 带来进一步提升;SFT+RL 效果最好。这说明合成验证轨迹和强化学习都对模型能力提升有贡献。
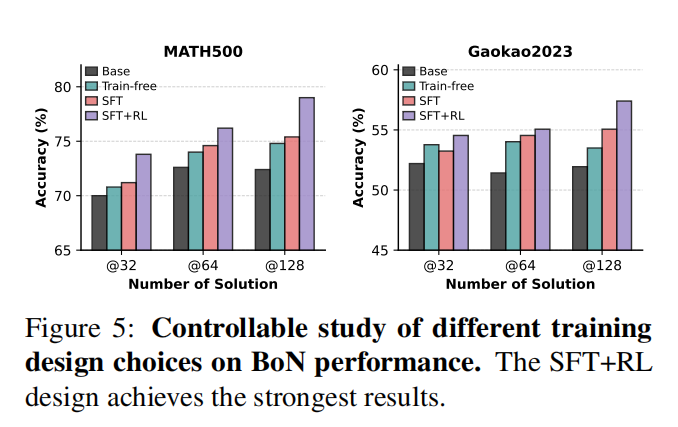
图注:训练流程消融实验。Train-free 已能带来提升,SFT 进一步增强验证能力,而 SFT+RL 效果最佳,说明合成轨迹训练与强化学习都发挥了作用。
研究团队还在 LiveCodeBench 和 HotpotQA 上测试泛化能力。结果显示,Agentic-Verifier-Qwen3-4B 在代码任务和多跳问答任务中同样取得较好表现,说明这种“正向验证 + 反向验证 + 工具增强”的范式不只适用于数学题,也有潜力迁移到更广泛的复杂推理任务中。
当然,该方法也存在代价。完整 Agentic Verifier 需要更多 token、更长验证轮次和更高推理延迟。因此,它更适合对可靠性要求较高的复杂推理场景,而不一定适合所有轻量级部署场景。
AgentV-RL 的核心价值不只是刷新 benchmark,而是将 Reward Model 从“静态打分器”推进到“智能体验证器”:它不再只是输入问题和答案后输出一个分数,而是能够先规划检查路径,再通过正向验证、反向追溯和工具调用逐步审查推理过程,最终给出有证据支撑的判断。尽管该方法仍面临推理成本较高、依赖合成数据和工具覆盖有限等问题,但它清楚表明,未来高可靠推理系统中的 verifier 将不再只是辅助模块,而可能成为连接生成、搜索、反思与修正的关键组件。










