绑定手机号
确认绑定









智猩猩AI整理
编辑:六六
当前,视频生成正加速迈向音视频联合生成的新阶段,为沉浸式媒体内容创作带来全新可能。然而,将高质量视频生成模型扩展至同步音频生成仍面临多重挑战:自然音色生成难、多说话人唇形同步误差高、音视频数据处理流程缺失,以及评估标准滞后。
为解决上述挑战,字节跳动研究团队提出了统一音视频生成模型 Alive,将主流文本生成视频模型的能力拓展至音视频联合生成与动画任务。
在百万级高质量数据上进行持续预训练与微调后,Alive 模型展现出卓越性能,不仅稳定超越开源模型,更达到甚至领先于业界领先商业方法。研究所公开的详细技术方案与基准测试,也将为学术界高效推进音视频生成模型研究提供有力支撑。

论文标题:Animate Your World with Lifelike Audio-Video Generation
论文链接:https://arxiv.org/pdf/2602.08682
主页链接:https://foundationvision.github.io/Alive/
Github:https://github.com/FoundationVision/Alive
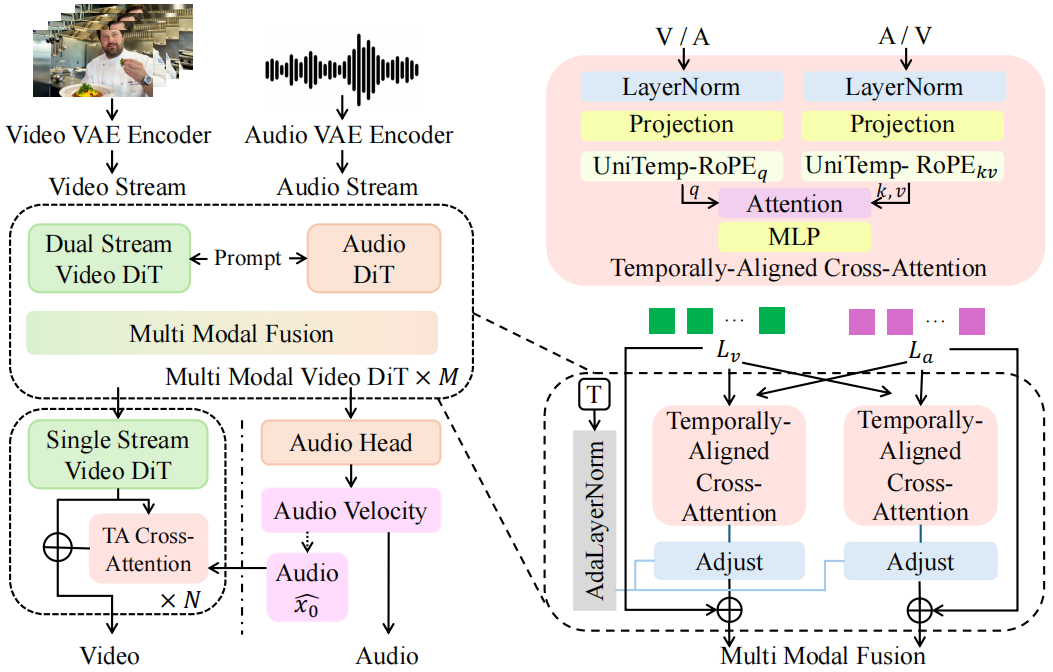
图 1 Alive 体系架构。
Alive 架构如图 1 所示,通过扩展的“双流+单流”范式将音频与视频 DiT 无缝集成。
1. 音视频联合建模
音频与视频隐空间主要通过时序对齐交叉注意力(TA-CrossAttn)进行交互。针对音视频精确同步难题,在 TA-CrossAttn 中引入统一时序旋转位置编码(UniTemp-RoPE),实现跨模态严格时序对齐,从而生成高保真同步音视频内容。
2. 音视频精炼器
在480p基础模型之上,通过引入级联音视频精炼器,实现1080p高分辨率生成,避免了直接训练高分辨率模型带来的巨大资源开销。该精炼器在提升视觉细节的同时,有效保持了原始内容与音视频同步性能。
视频方面:将1080p视频先降采样再升采样,模拟基础模型的低分辨率输出,随后经编码、加噪后送入精炼器的 Video DiT,以消除生成伪影。
音频方面:将干净音频隐空间直接送入冻结的 Audio DiT,不加噪声,从而有效保留原始音频保真度与基础模型已建立的同步性能。
1. 多阶段训练
文本生成视频(T2V)骨干网络继承自 Waver1.0-480p-SFT 预训练权重。文本生成音频(T2A)采用两阶段课程学习:
首先在 70 万小时转录语音上进行大规模文本生成语音(TTS)预训练,建立语音-声学对齐基础;
随后在融合语音与音视频标注数据(共11.6万小时)上进行多条件指令微调,实现从纯语音合成到复杂音视频场景生成的泛化。
联合生成训练(T2VA/I2VA/R2VA)流程包括:1)在 1100 万样本上进行联合训练;2)在 430 万类别均衡数据上进行持续训练(CT);3)引入高美学数据进行监督微调(SFT);4)利用 80 万配对样本进行参考联合微调(RJT),实现角色驱动生成。
2. 平衡音视频学习动态
研究团队采用非对称学习率策略:VideoDiT 使用较大学习率以更新视觉分布,AudioDiT 及跨注意力模块使用较小学习率以维持音频稳定性。该策略有效防止音频权重漂移,在提升视觉质量的同时保持音频保真度。
3. 推理方案
研究团队采用多条件分类器自由引导(CFG)控制,将文本提示与交叉注意力信号作为独立引导条件,增强音视频同步性。在多条件框架下适配非对称扰动引导(APG),分别设置音视频分支不同参数以提升真实感。提示工程方面,利用大语言模型进行零样本提示增强,将用户输入映射至训练结构化模式;通过检索增强精炼将模糊声音描述替换为规范术语,提升音效真实感。
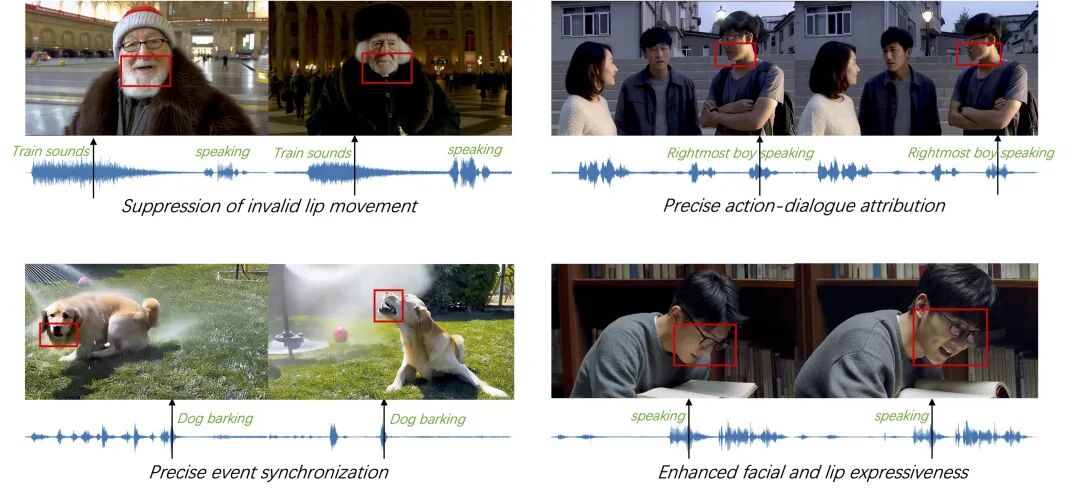
图 2 仅使用文本条件(左)与同时使用文本及相互交叉注意力信号条件(右)所生成结果的对比。
研究团队引入了一种交叉对流程和一种基于统一编辑的参考增强流程,以稳健地将身份信息与静态外观解耦,从而有效缓解复制粘贴偏差。此外,开发了一种多参考条件机制,结合专门的时序偏移与双条件分类器自由引导(CFG)策略,使模型能够将参考图像视为持久性的身份锚点而非时序帧,进而实现了优异的身份一致性与运动动态表现。
评估指标: 为人工评估定义了一套全面的指标,分为六大类别:运动质量(Motion Quality)、视觉美学(Visual Aesthetic)、视觉提示跟随(Visual Prompt Following)、音频质量(Audio Quality)、音频提示跟随(Audio Prompt Following)和音视频同步(Audio Video Synchronization)。图 3 展示了指标的详细分类。
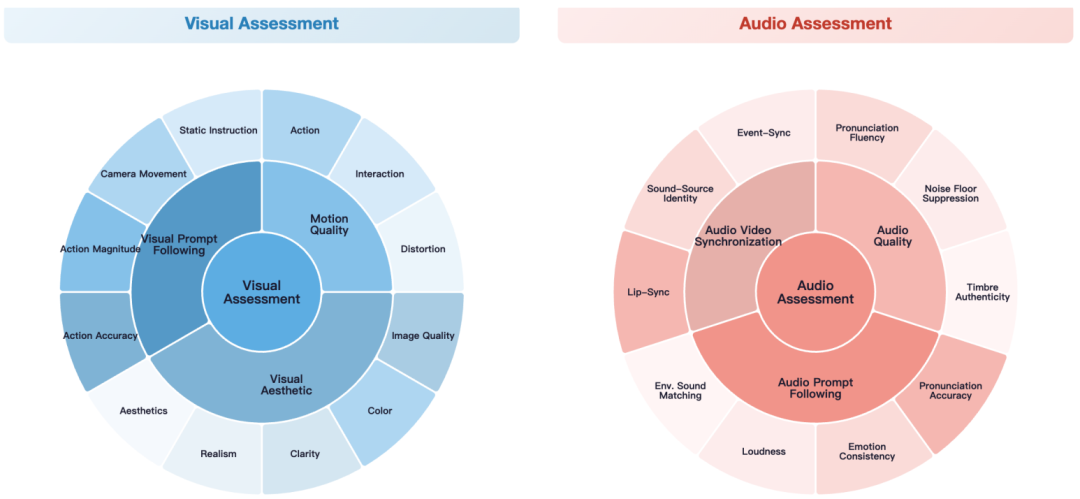
图 3 Alive-Bench 1.0 详细评估指标。
Alive-Bench 1.0:一个广泛的通用基准,包含 264 个样本,涵盖单人讲话、多人对话、运动、日常活动、动物、交通工具、超现实场景等多种场景。
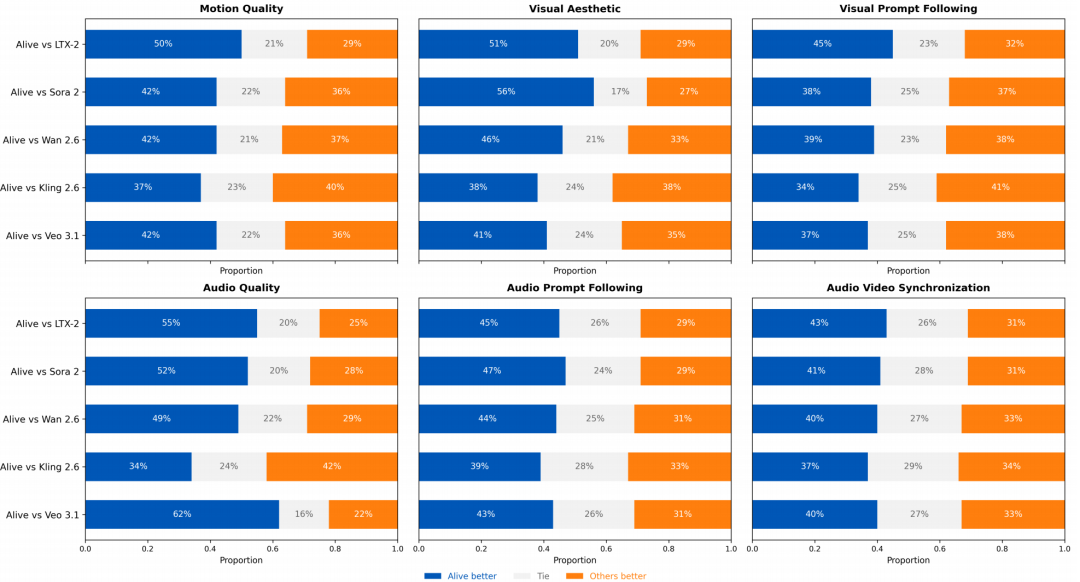
图 3 Alive-Bench 1.0 人工评估结果,展示了本模型(Alive)与领先模型的对比。
运动质量:Alive 的运动质量优于 Veo 3.1、Wan 2.6、Sora 2和LTX-2,略逊于 Kling 2.6。
视觉美学: Alive 展现出强大的视觉美学能力,显著优于 Veo 3.1、Wan 2.6、Sora 2 和 LTX-2,与 Kling 2.6 持平。
视觉提示跟随:Alive 在视觉提示跟随方面明显优于 LTX-2,与 Veo 3.1、Wan 2.6 和 Sora 2 水平相当,但落后于 Kling 2.6。
音频质量:Alive 的音频质量远超 Veo 3.1、Wan 2.6、Sora 2 和 LTX-2,但落后于 Kling 2.6。
Alive 在音频提示跟随和音视频同步方面表现最佳,显著优于其他对比模型,这体现了其在跨模态理解与对齐方面的强大优势,特别是在忠实反映音频指令以及保持音频事件与视觉内容紧密时序对应方面。
在所有指标上,Alive 均位列前列或接近前列,展现出均衡的能力分布而非单一指标优势。










