绑定手机号
确认绑定









智猩猩AI整理
编辑:六六
近年来,生成式人工智能正朝着能够进行“交错生成”(interleaved generation)的统一多模态模型发展。这类模型能够在同一框架内同时完成文本生成与图像生成,并支持二者之间的交替交互。
字节Seed研究团队提出一种专为交错生成设计的统一强化学习框架——UniGRPO,将“提示词→思考→图像”序列建模为单一马尔可夫决策过程(Markov Decision Process)。遵循极简原则,集成成熟方案:推理部分采用标准 GRPO,视觉合成部分采用 FlowGRPO。该统一训练方案通过推理机制显著提升了图像生成质量,为未来完整交错模型的后续训练建立了稳健且可扩展的基线。

论文标题:UniGRPO: Unified Policy Optimization for Reasoning-Driven Visual Generation
论文链接:https://arxiv.org/pdf/2603.23500v1
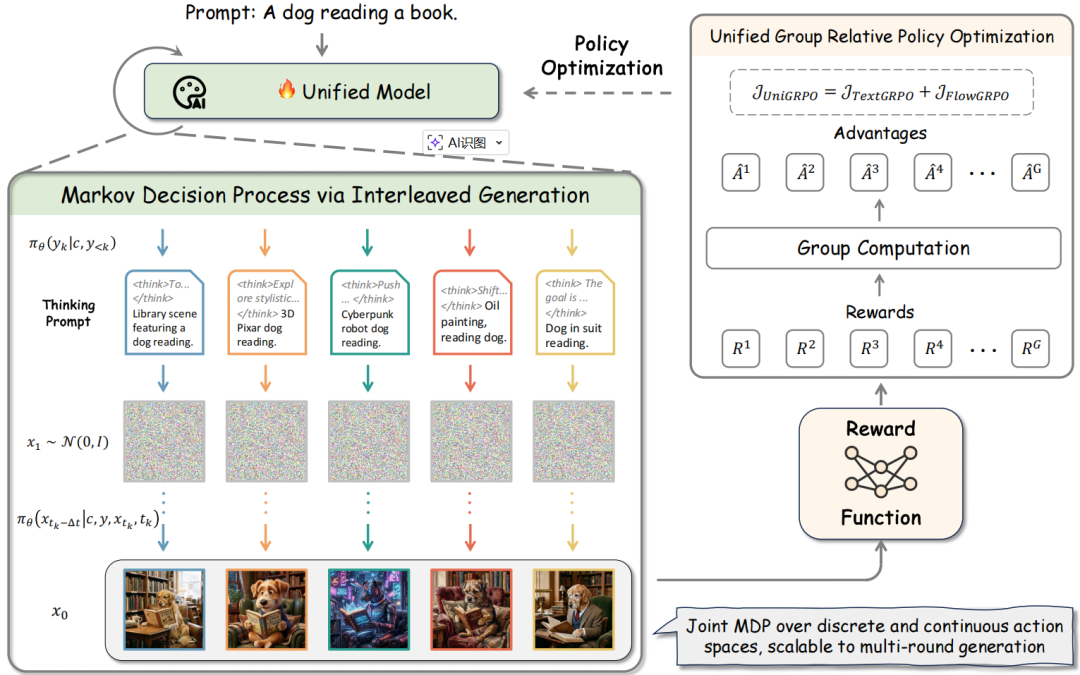
图 1 UniGRPO概述
1. 多模态生成作为马尔可夫决策过程
将交错生成建模为连续马尔可夫决策过程,每个决策步在文本阶段对应单个词元预测,在图像阶段对应单个去噪步。
2. UniGRPO 框架
给定一个执行交错生成的统一模型,UniGRPO 将完整生成过程建模为马尔可夫决策过程,并通过 GRPO 进行更新。
具体而言,对于给定提示,首先生成多条推理链,每条推理链再生成对应的图像轨迹。基于完整多模态轨迹的终端奖励计算组相对优势,并利用这些优势通过统一目标函数对模型进行更新。
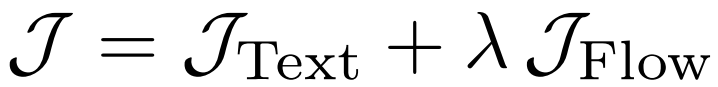
为提升框架对多轮交错生成的可扩展性,在训练方案中引入两项关键改进:
消除无分类器引导:在训练阶段,完全移除无分类器引导,采用无分支的线性展开轨迹,以确保计算图简洁、梯度估计稳定。
虽然移除引导通常会导致模型对提示的响应有所下降,但通过强化学习直接优化文本-图像对齐与图像质量的奖励信号,模型能够将对齐能力逐步内化至自身参数中。由此在保持高效训练的同时,也为后续扩展至多轮交互与多条件生成任务奠定了基础。
基于速度的正则化:防止奖励破解是视觉生成强化学习中的核心挑战。为获得更稳健的约束,对所有噪声水平施加一致的速度场约束,即直接在未加权的速度场上计算均方误差惩罚。
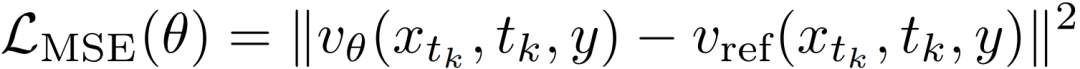
这使得优化后的模型在所有噪声水平下都与原始模型保持接近,从而减少策略钻空子的可能,在有效缓解奖励破解的同时,也保留了基座模型原有的生成先验。
表 1 结果表明,有监督微调显著提升了 Bagel 的基础能力。在所有强化学习方法中,UniGRPO 取得最优性能,文本对齐基准得分 0.8381,GenEval 得分 0.90。UniGRPO、FlowGRPO 与 TextGRPO 的对比表明,联合优化推理与生成策略优于单独优化任一组件。此外,在 Bagel 上启用显式推理链并未持续提升 GenEval 得分,这与其推理模块主要针对知识推理训练有关,不完全适用于简短提示改写任务。然而,UniGRPO 成功利用推理链实现了最先进性能。
表 1 在 TA 与 GenEval 上的主要结果。所有强化学习方法均从经过有监督微调后的 Bagel 检查点开始初始化。“Thinking” 表示该方法是否显式生成中间推理词元。“-” 表示训练崩溃。
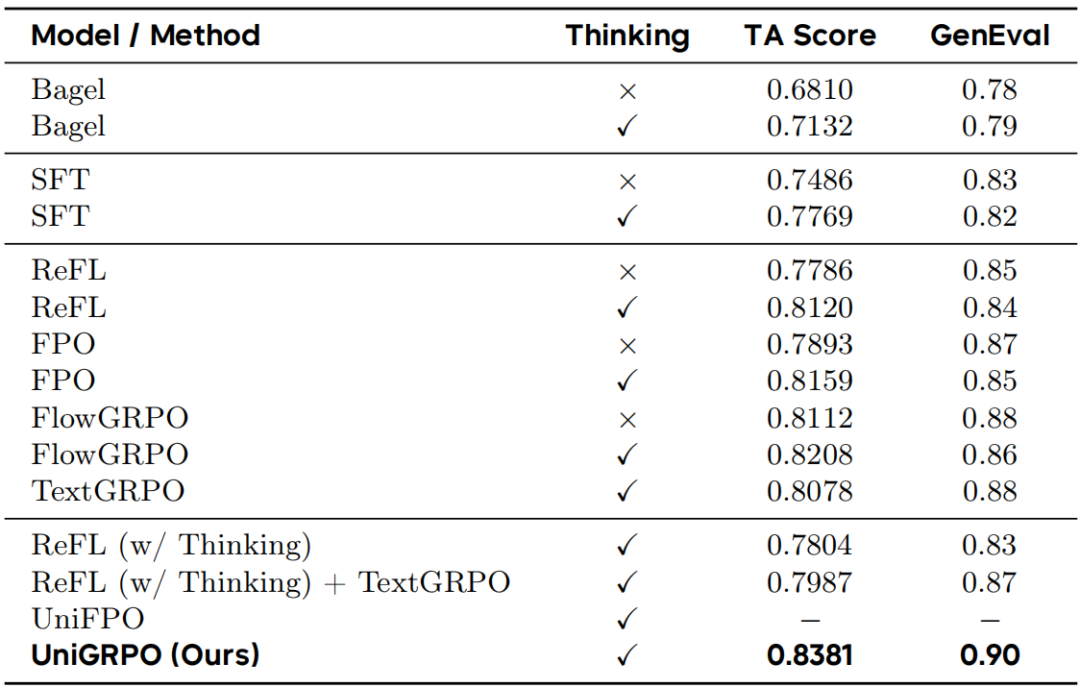

图 2 UniGRPO 的推理与视觉输出。联合强化学习优化产生了任务导向的推理,从而引导合成策略生成忠实、逼真的图像。
定性分析:如图 3 所示,原始 Bagel 生成的图像存在颜色过饱和及明显的人工伪影。有监督微调虽有助于减轻人工伪影,但会降低图像锐度,导致细看时出现明显模糊。所提出的 UniGRPO 克服了这一局限,显著提升了图像美学质量与文本-图像对齐能力,生成的照片级真实感图像细节丰富,且忠实反映了复杂的用户提示。
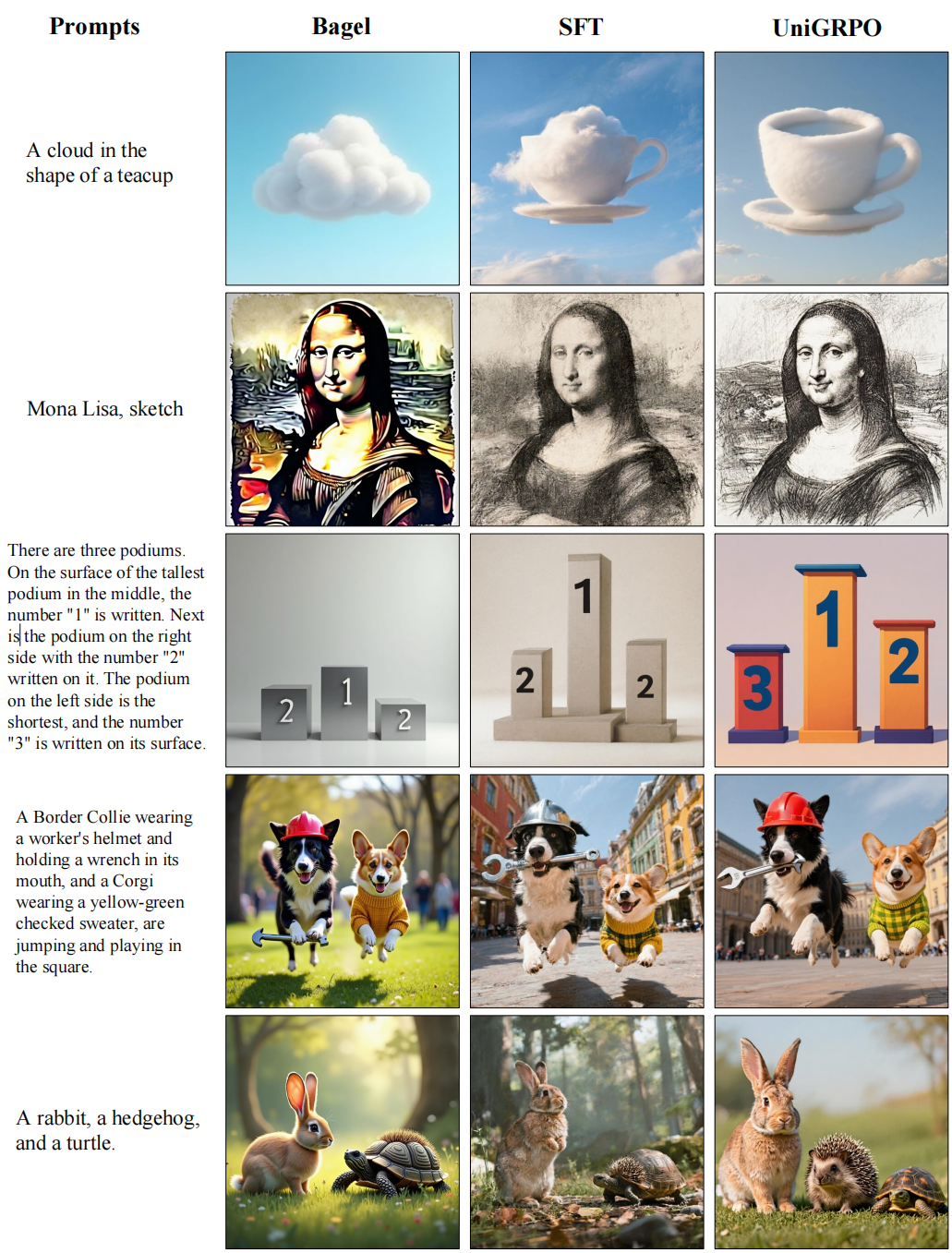
图 3 T2I 定性比较










