绑定手机号
确认绑定









智猩猩AI整理
编辑:六六
世界模型旨在使人工智能系统能够以连贯且时序一致的方式表征、生成动态环境并与之交互。 尽管近期的视频生成模型已展现出令人印象深刻的视觉质量,但其在实时交互、长时程一致性以及对动态场景的持久记忆方面仍存在局限,阻碍了其演化为实用世界模型的进程。
中国电信人工智能研究院李学龙教授团队提出了一种实时多模态4D世界模型TeleWorld,其在闭环系统中将视频生成、动态场景重建与长期世界记忆相统一。TeleWorld 是一个拥有18B参数的模型,能够以每秒8帧的速率实时生成高分辨率视频(960×1760),并在WorldScores基准测试中位列第一。

论文标题:TeleWorld: Towards Dynamic Multimodal Synthesis with a 4D World Model
论文链接:https://arxiv.org/abs/2601.00051
TeleWorld 生成视频
01 方法
1. “生成-重建-引导”循环
研究团队提出了一种用于统一的四维时空建模的动态“生成-重建-引导”闭环框架,如图 1 所示。该框架构建了一个实时的、原生的四维世界表征,该表征随着每个新生成的视频片段持续更新,确保与不断演化的视觉内容完全同步。
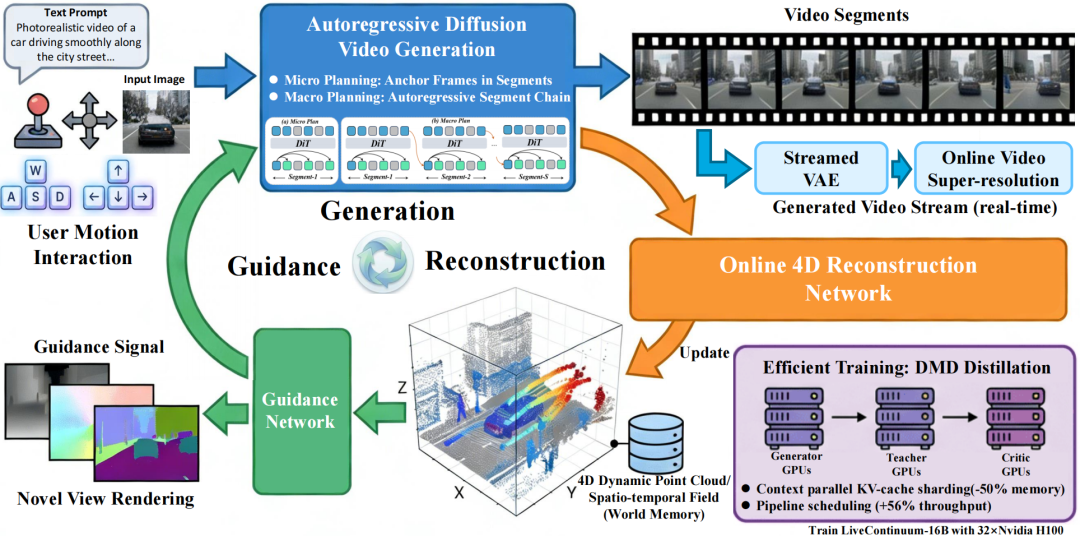
图 1 TeleWorld结构。该模型首先依据用户预定义的指令生成初始视频集,随后进入迭代循环。在每一轮迭代中,系统处理用户的实时输入指令,对上一轮输出的视频进行重建,并依据输入相机姿态进行渲染。渲染结果将作为引导信息,以指导当前轮次的视频生成与运动合成。此过程循环重复执行。
在此循环中,“重建”指从已生成帧中恢复出一致性四维场景表征的过程;而“引导”则指利用重建的四维场景与用户键盘指令共同指导下一轮视频生成。生成与重建步骤实时进行,引导与生成之间的延迟极低。
2. 长记忆自回归视频生成
(1)微规划与宏规划
研究团队将"宏微规划"方法引入 TeleWorld ,这是一种统一的规划方法,包含微规划与宏规划两个关键组成部分,如图 2 所示。
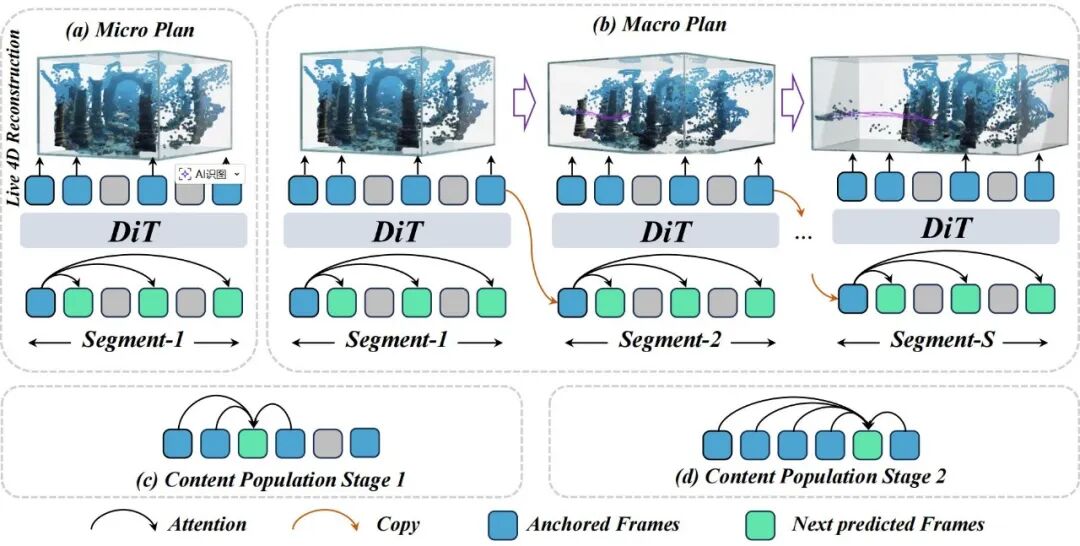
图 2 宏微规划框架由两个层次构成:(1) 微规划,在每个局部片段内生成一系列帧以约束误差传播;(2) 宏规划,通过自回归链连接各片段——每步的输出帧将引导后续预测,从而确保长程时间一致性。如图所示,绿色标记的三个预测帧对应初始预规划帧集合 ,这些关键帧在整个视频序列中起到维持长期记忆与稳定性的作用。
微规划:微规划 通过从初始帧 预测一组稀疏的关键帧 ,为第 个片段构建短期叙事。这些预规划帧作为后续合成的稳定锚点,其时间戳设定为 (早期邻近帧), (中点帧)和 (片段结束帧)。该过程形式化表述如下:
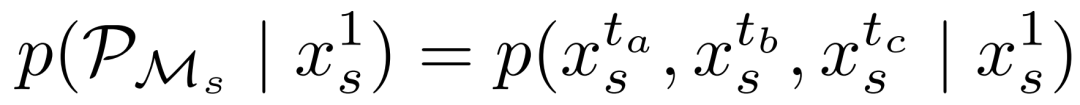
宏规划:该方法通过跨片段顺序链接重叠的微规划来构建全局叙事线。给定一个长度为 、被划分为 个片段的完整视频,令 为第 个片段的初始帧。由宏规划产生的规划帧集合记为 。该过程定义如下:
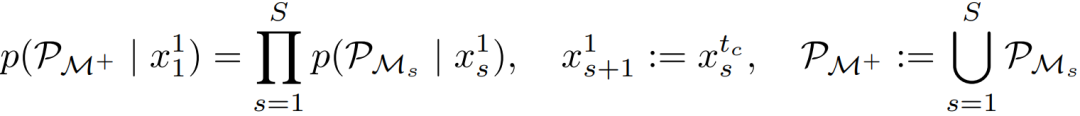
通过分层链接片段,宏规划将逐帧的自回归依赖关系转换为稀疏的片段级规划步骤序列。随后,通过对跨片段的锚定关键帧进行在线四维重建,将这些记忆锚定在一个连贯的时空场内,从而将所有关键帧嵌入其中。
模型采用了一种抗漂移的重编码与解码策略:从当前片段的初始与末端规划标记拼接重建一个短视频片段,从而实现稳定片段间的过渡。
为确保解码时的时间连续性,末端标记被复制并插入以形成连续的潜在序列。第二份副本经重编码后的潜在表示即作为下一片段的初始条件。
(2)基于MMPL的内容填充
微规划提供三种关键帧:早期帧 、中点帧 与终止帧 。受早期帧条件生成方法的启发,内容填充按两个顺序阶段执行:
第一阶段:以初始帧与早期规划帧作为起始,以中点规划帧作为结束,填充第一个子片段。
第二阶段:将以中点帧为止的所有帧作为新的起始,以终止帧作为结束,进而生成剩余内容。
该过程可形式化表达如下:
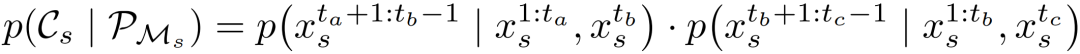
每个子片段内的内容填充仅取决于其对应的规划帧,这使得多个子片段在其内部规划帧准备就绪后即可并行优化。通过将片段级的优化任务分布至多个 GPU ,实现了并发执行,从而显著加速了长视频的合成。
3. 实时4D重建
(1)关键帧重建
TeleWorld 模型仅需对稀疏的预规划帧集合 进行 4D 重建。每个视频片段的开始、中间和结束部分将被用于记录信息到四维时空场中。在内容填充过程中,中间的运动将基于这些记录的线索进行补充。
(2)运动物体分割
模型采用跨帧的帧间滑动窗口策略: 。在此窗口内,并跨越三个层集合 (包括浅层、中层和深层,分别对应不同的层范围 ,其中 捕获语义显著性, 反映运动不稳定性, 提供空间先验以抑制离群值。
最终,通过阈值化获得每帧的动态掩码: ,随后进行特征聚类以细化。
框架中还实施了网络级的早期掩码策略,用于 4D 重建与堆叠。静态场景元素被合并并逐步扩展,而稀疏的动态组件则随时间分别渲染。
遵循 4D-VGGT 工作,为减轻动态像素引入的几何不一致性,也仅在浅层和中层(第 1~5 层)通过抑制其键向量来掩码动态图像标记。
4. 引导机制
(1)键盘控制
研究团队同样采用四个 WASD 键与方向键来模拟移动与视角变化,其映射关系如下所示:

这些输入被相应地映射为相机位姿参数,并以条件信号的形式引导模型生成。
TeleWorld 键盘控制效果
(2)视图条件引导
对处理后的键盘输入进行编码,沿帧维度将引导视频 token 与目标视频 token 进行拼接,其中 为 DiT 的输入:
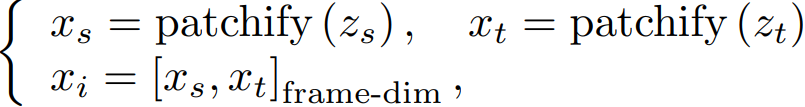
5. 分布匹配蒸馏
基于标准自强制流程,分布匹配蒸馏可直接应用于宏微规划之上,并部署于 TeleWorld 框架内。
结合并行化解码,最终系统实现了显著的推理加速:在 NVIDIA H100 GPU 上评估,TeleWorld-1.3B 模型生成长视频的持续吞吐量超过 32 FPS,TeleWorld-18B 模型则达到 8 FPS。
采用 Ray 进行模型权重的多 GPU 分布式存储,从而解决训练设置需同时协调三个扩散模型——自回归生成器、判别器与教师模型——导致所有组件无法同时驻留于单个 80GB 高带宽内存 GPU 中的限制。
研究团队设计了一种新颖的流水线训练调度方案,通过重叠生成器、判别器与教师模型的计算过程,从而最小化 GPU 空闲时间(即流水线气泡)。生成器与判别器步骤的执行调度如图 3 所示。
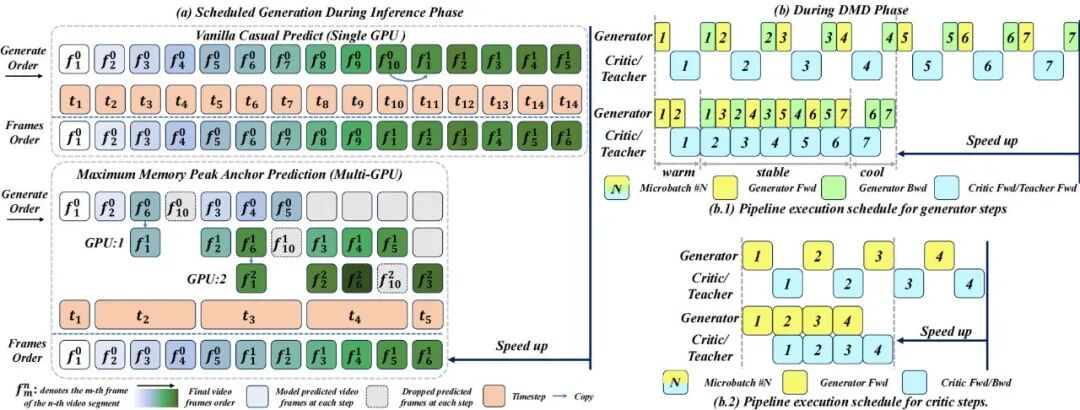
图 3 分布匹配蒸馏的流水线执行调度方案。(a) 生成器步骤流水线(包含 7 个微批次)。单元格长度表示执行时间。判别器与教师模型并行工作,为简化图示将其单元格合并,其单元格长度表示两者执行时间的最大值。图上半部分为非流水线基线方案,会产生大量GPU气泡(即GPU空闲时间)。下半部分为提出的流水线调度方案。在稳定阶段,微批次 的生成器反向阶段与微批次 的生成器前向阶段,同微批次 的判别器/教师前向阶段并发执行。通过为各组件分配适当数量的 GPU,精细平衡所有阶段的执行时间,从而实现近乎完美的计算重叠。该方法最大限度地减少了 GPU 气泡,在系统中实现了生成器、教师模型与判别器工作负载的高效并行化。(b) 判别器步骤流水线(包含 4 个微批次)。由于判别器更新期间生成器参数保持冻结,该流水线遵循更简单的生产者-消费者执行模式。
6. 流式与调度生成及在线视频超分辨率
(1)调度生成
研究团队提出一种自适应工作负载调度策略,该策略动态地安排微规划、宏规划与内容填充的执行顺序,以最大化并行度。
举例而言,设 , , ,当前片段的规划帧 将立即作为下一片段的初始帧 。因此,下一片段可在当前片段仍在填充其中间帧(例如 )时,开始其微规划。这种分段独立性自然实现了片段并行生成,其形式化表达如下所示:
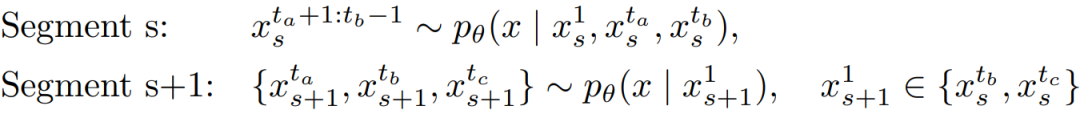
为保持实时实际生成,采用如下最大吞吐量预测策略:使用最小内存峰值预测策略尽可能降低延迟。当选用 作为 时,中间帧 被跳过,从而绕过了时间上下文最深、生成延迟最高的区域。
任何即时用户输入操作仅会在三个潜在块之后被渲染,导致约一秒的反馈延迟。因此,当前观察到的世界输出实际上对应于用户输入前一秒所捕获的预缓冲变化。
(2)流式VAE
基于 StreamDiffusionV2 的设计思想,研究团队提出了一种支持流式处理的 VAE 变体,从而实现实时流式视频生成。流式 VAE 并非一次性编码整个视频序列,而是对短而连续的视频块进行处理——模型实现中通常为 4 帧。
流式 VAE 的架构在其三维卷积层中采用了中间特征的策略性缓存机制。当每个新帧块输入模型时,网络会复用从前一帧块计算得到的时间相关特征,从而在无需重新编码长时历史的情况下,保持跨块边界的时间连贯性。这样的设计显著减少了冗余计算与内存开销,实现了高效的增量式编码与解码。
(3)视频超分辨率
模型引入了一种受 FlashVSR 启发的流式超分辨率模块,该模块负责将流式 VAE 解码的隐式表征实时上采样为高分辨率视频帧。
从 FlashVSR 借鉴的一项关键创新是其局部约束稀疏注意力机制。该机制将自注意力运算限制在局部时空窗口内,大幅降低了通常困扰视频超分辨率模型的计算复杂度。
此外,TeleWorld 模型利用了 FlashVSR 的轻量级条件解码器:解码器的上采样过程以从流式VAE输出中提取的特征为条件,在确保高保真结果的同时维持较低的计算开销。
关键在于,该超分辨率模块被设计为以完全流式的方式与流式 VAE 协同工作。它处理与 VAE 输出流对齐的短视频块(例如 5 帧),并在每个块可用时逐步应用超分辨率。
总而言之,通过集成调度生成、流式 VAE 与视频超分辨率技术,该系统使得 TeleWorld-18B 模型能够在四张 NVIDIA H100 GPU 的配置下实现稳定的 8 FPS 性能,并生成高质量的 960×1760 分辨率视频。
02 评估
1. 多模态数据集构建
为支持大规模训练与统一评估,研究团队构建了 TeleWorld-500K 数据集,这是一个专门针对可控相机运动与动态物体的、带有四维标注的视频精选数据集。
2. 定量分析
WorldScore 基准是目前衡量“世界生成”能力最全面的测评协议之一。WorldScore 评估模型是否能够在不同视角、场景转换及时间演进中构建并维持一个一致的世界。该基准包含静态与动态两种设定,以及一系列丰富的指标,用于评估可控性、一致性、感知质量与运动行为。
表 1 WorldScore 基准定量比较。 该表展示了 TeleWorld 与代表性基线模型在官方评估协议下的静态与动态世界生成排行榜分数,以及相应的可控性与一致性指标。所有指标均为数值越高代表性能越优。
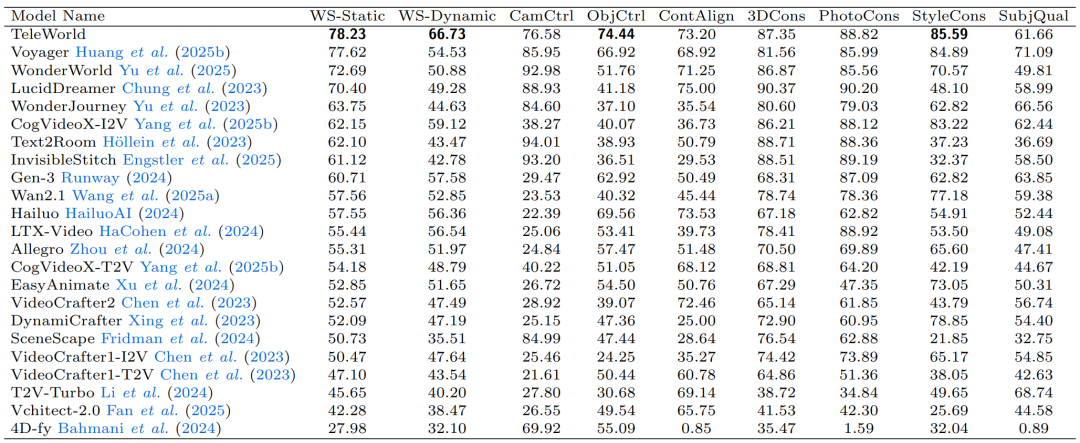
将 TeleWorld 与涵盖三维、四维及视频生成方法的 23 个基线模型进行比较,如表 1 所示。TeleWorld 在两项综合指标上均取得了最优性能,其 WS-Static 得分为 78.23,WS-Dynamic 得分为 66.73。次优模型在静态场景下得分为 77.62,在动态场景下得分为 59.12。因此,TeleWorld 在静态世界生成上优于最强基线 0.61 分,在动态世界生成上优于最强基线 7.61 分。值得注意的是,TeleWorld 是唯一同时在静态与动态两个赛道排名第一的方法,这表明其性能提升并非以牺牲某一方面的能力为代价。
在可控性方面,TeleWorld 在相机控制、物体控制与内容对齐三个维度均取得均衡且优异的分数,表明其能够在多个维度上满足用户的多模态约束,而非偏重单一维度。其出色的物体控制得分尤其表明,TeleWorld 能够维持一个隐式且持久的世界状态,在长序列中保持物体身份与布局的一致性,这与其生成-重建的闭环设计理念相符。
TeleWorld 在结构与感知一致性方面同样表现卓越,其三维一致性、光度一致性、风格一致性与主观质量得分均名列前茅。这些结果反映出,生成内容的行为类似于一个连贯内部四维表征的投影——这与本框架捕获并强化全局时空结构、同时保持视觉保真度的能力相一致。
动态性能进一步凸显了 TeleWorld 的优势。其 WorldScore-动态得分可分解为强劲的运动准确度、适中的运动幅度以及优异的运动平滑度。这一特征表明其生成的运动合理、有序且无时间不连续性,避免了基线系统中常见的运动不足或不稳定问题。这种稳定性源于 TeleWorld 利用学习到的内部状态来引导时间演化,而非仅在局部近似变化。
总而言之,实验结果表明 TeleWorld 提供了均衡、稳定且可扩展的世界生成能力。它不依赖于极端的指标优化或单一维度的专门化,而是证明了统一模型能够联合优化可控性、一致性、感知保真度与动态行为。在动态分数上的显著提升,结合其结构与语义的稳定性,表明 TeleWorld 特别适合长时程、多条件的生成任务。这些结果确立了 TeleWorld 作为未来研究方向的一个有力候选,这些方向涉及长视频合成、可控模拟、交互式环境以及需要连贯时空演化而非孤立视觉质量的世界建模任务。










