绑定手机号
确认绑定









智猩猩AI整理
编辑:卜圆、没方
随着语言模型能力不断增强,用户不仅期望它们提供准确的回答,还希望其行为能在各种场景下与多样化的人类偏好保持一致。为实现这一目标,强化学习(RL)训练流程开始引入多个奖励信号,每个奖励分别捕捉一种特定的偏好,以引导模型产生符合期望的行为。然而,近期的研究在多奖励设置下直接默认采用GRPO,未充分考察其适用性。直接将 GRPO 应用于对不同 rollout 奖励组合进行归一化会导致这些原本不同的奖励组合坍塌为相同的优势值(advantage values),从而降低训练信号的分辨能力,造成次优收敛,甚至在某些情况下引发训练早期失败。
为此,英伟达提出了一种新的策略优化方法GDPO ( Group reward-Decoupled Normalization Policy Optimization) 。GDPO 通过对各个奖励信号分别进行解耦的归一化处理,更真实地保留了不同奖励之间的相对差异,从而实现更精准的多奖励优化,并显著提升训练稳定性。研究团队在工具调用、数学推理和代码推理三项典型任务上对 GDPO 与 GRPO 进行了系统性对比,评估指标涵盖正确性维度和对约束条件的遵循程度(如输出格式的规范性、响应长度的合理性)。实验结果表明,在所有设置下,GDPO 均稳定优于 GRPO,充分验证了其在多奖励强化学习场景中的有效性与良好泛化能力。

论文标题:GDPO: Group reward-Decoupled NormalizationPolicy Optimization for Multi-reward RLOptimization
论文链接: https://arxiv.org/pdf/2601.05242
项目链接:https://nvlabs.github.io/GDPO/
01 方法
(1)GDPO
GDPO 并非像GRPO那样先将全部 n个奖励求和,再进行组内归一化以得到总优势值 Asum,而是针对第 i 个问题的第 j 次 rollout,分别计算每个奖励的归一化优势值:
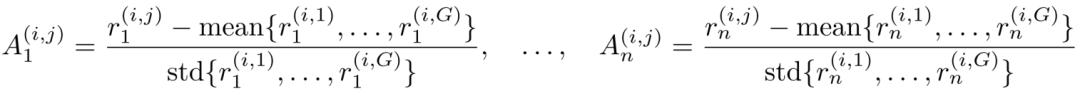
随后,对各奖励维度上已归一化的优势值求和得到用于策略更新的总体优势值:
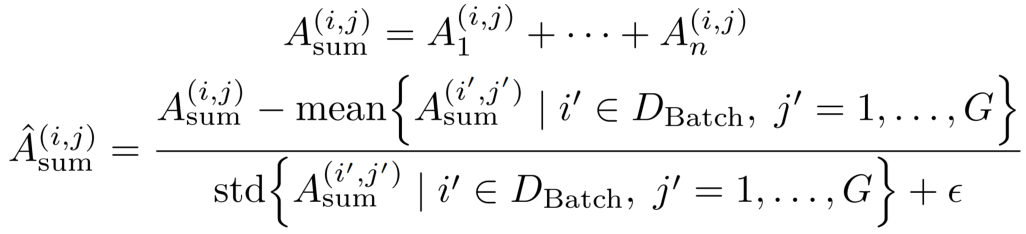
最后,对多奖励优势值的求和结果施加批级别优势归一化(batch-wise advantage normalization),以确保最终优势值 的数值尺度保持稳定,不会因引入更多奖励而不断增大。
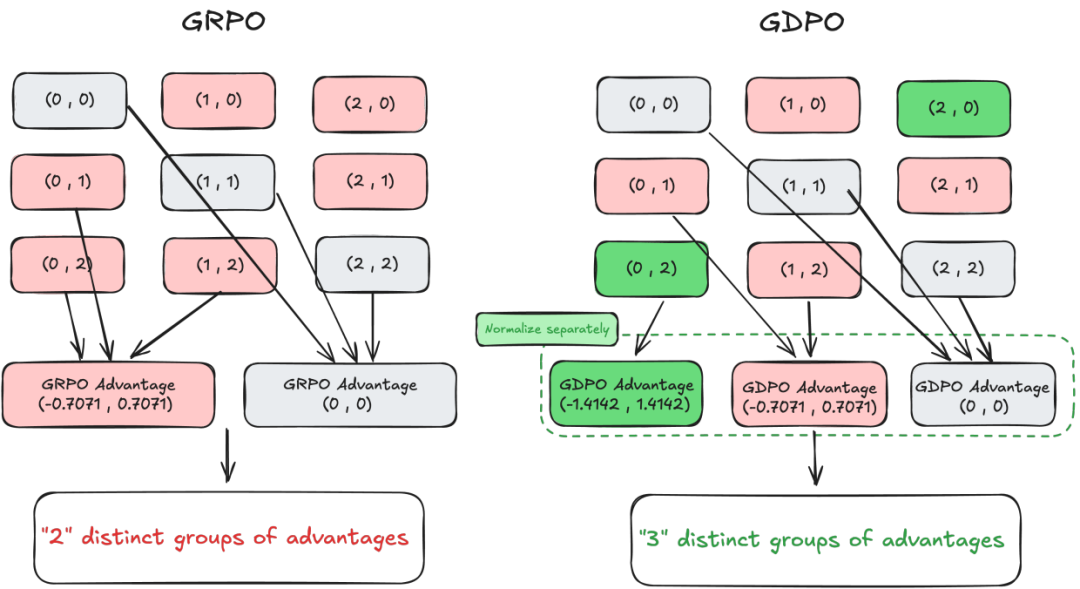
图2 在包含两个二元奖励、两个 rollout 的示例中,GRPO 与 GDPO 的优势值计算对比
通过为每个奖励单独进行归一化,GDPO 缓解了 GRPO 在优势值估计中的信息丢失问题,如图 2 所示。例如,在 GRPO 中,不同的奖励组合如 (0,1) 和 (0,2) 可能被映射为相同的优势值,掩盖了它们之间的细微差异;而 GDPO 则为它们分配不同的优势值(如 (−0.7071, 0.7071) 与 (−1.4142, 1.4142)),更合理地反映出 (0,2) 应提供更强的学习信号。相比之下,GDPO 会为不同对象分配差异化的优势值(例如 (−0.7071, 0.7071) 与 (−1.4142, 1.4142)),从而更合理地体现出取值为 (0,2) 的样本应当输出更强的学习信号这一特性。
类似地,当扩展到三个 rollout 时,GRPO 会将所有总和相同的组合(如来自不同奖励分布的 (1,1,0) 和 (0,0,1))统一归为优势值 (0,0,0),而 GDPO 能保留各维度的差异,生成非零且有区分度的优势值,从而更好地捕捉多奖励结构中的语义信息。
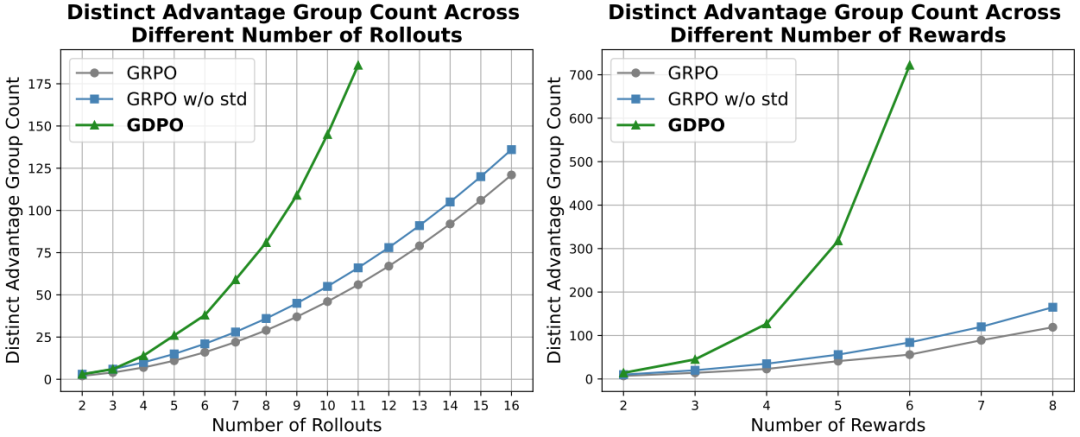
图4 不同方法生成的互异优势值组数量对比。随着 rollout 数量(左)或奖励维度数(右)增加,GDPO 始终显著优于 GRPO 及其变体(GRPO w/o std),保留更多优势值区分度,从而提供更具表达力的训练信号
进一步通过比较 GDPO、GRPO 以及不带标准差归一化的 GRPO(GRPO w/o std)在不同实验设置下所产生的互异优势值组数量,来量化 GDPO 的有效性,如图 3 所示。在双奖励场景中,随着 rollout 数量的增加,GDPO 始终能生成显著更多的互异优势值组,且这一差距随 rollout 数量增长而进一步扩大。另一方面,在固定 rollout 数量为4、逐步增加奖励数量的设置下,也呈现出类似趋势:随着优化目标(奖励维度)的增多,GDPO 表现出越来越精细的优势值粒度。
这表明,研究团队所提出的解耦归一化方法在各类强化学习设置中均能有效提升互异优势值组的数量,从而实现更精确的优势估计。
(2)有效整合优先级变化
研究团队系统地梳理了两类实现目标优先级的常见方法:一是调整不同目标对应奖励的权重,二是直接修改奖励函数。同时,分析了当各目标的基础奖励在优化难度上存在显著差异时,这两种方法在行为上的区别。
当底层目标的难度差异较大时,单纯调整奖励权重未必能实现预期效果:若某一目标显著更容易优化,模型往往会优先最大化其奖励,而忽略所分配的权重。因此,要使模型更关注更具挑战性的目标,权重差异需足够大以抵消难度差距。然而,即便如此,模型仍可能偏向优化简单目标,而非用户真正重视的目标
为应对多奖励强化学习中的奖励作弊(Reward Hacking)问题,近期工作提出将易优化的奖励 条件化于更关键但更难优化的奖励 。其中,
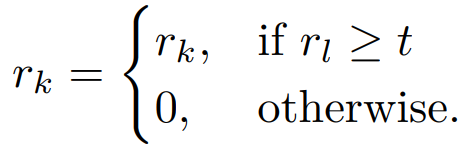
只有当 达到预设阈值t时,模型才能获得 的奖励;否则 被置为零。这种设计强制模型优先确保高优先级目标达标,之后才可能从次要目标中获益,从而有效避免模型“走捷径”,显著缓解因任务难度差异导致的优化偏差,使学习行为更好地对齐人类真实偏好。
02 评估
(1)工具调用能力
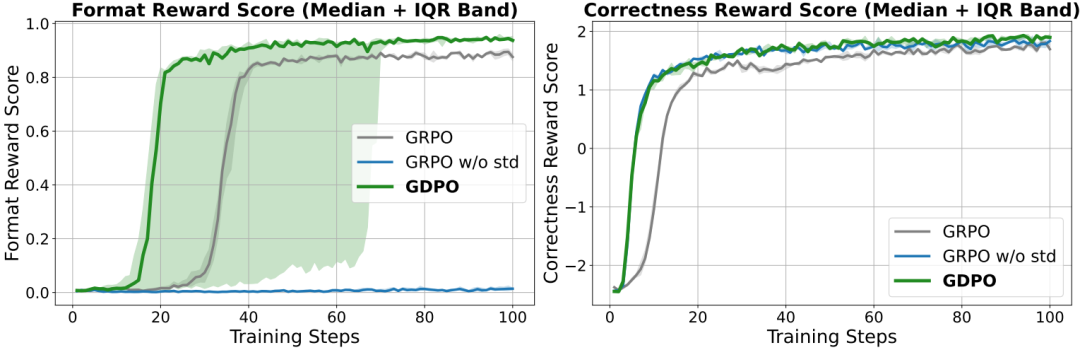
图4 在 Qwen2.5-1.5B 模型上进行五次独立运行工具调用任务的中位数及四分位距(IQR)奖励曲线
如图3所示,从训练曲线可以看出,在所有运行中,GDPO 在格式奖励和准确性奖励两个指标上均持续收敛到更高的值。尽管在训练过程中的收敛步数并不稳定,GDPO 在格式正确性上最终表现优于 GRPO。在正确性奖励方面,GDPO 在训练早期提升更快,并在后期达到比 GRPO 基线更高的奖励分数,这表明 GDPO 能提供更准确的优势估计,从而实现更优的策略优化。
表1 利用GDPO 与 GRPO 训练的 Qwen2.5-Instruct-1.5B/3B 模型在工具调用准确率与格式正确性对比

在 BFCL-v3 评测(见表 1)中,GDPO 在平均工具调用准确率和格式正确性方面也始终优于 GRPO 训练的对应模型。在 Qwen2.5-Instruct-1.5B 的训练中,GDPO 在 Live 与 non-Live 任务上分别提升了近 5% 和 3%,整体平均准确率提升约 2.7%,且格式正确率提高超过4%。在 3B 模型上也观察到类似提升:GDPO 在所有子任务中均持续超越 GRPO,准确率最高提升达 2%,同时实现了更高的格式正确率。

图5 GRPO 与 GDPO 在 DeepSeek-R1-1.5B 模型上的训练行为对比
从图 5 所示的 DeepSeek-R1-1.5B 模型上 GRPO 与 GDPO 的训练曲线可以看出,首先,无论采用哪种优化方法,模型都倾向于优先最大化更容易优化的奖励。在此任务中,长度奖励(length reward)更容易优化,因此 GRPO 和 GDPO 均在训练开始约 100 步内就达到了满分的长度得分。
同时可以观察到,长度奖励的快速上升与正确性奖励的早期下降同步发生,表明这两个奖励目标之间存在竞争关系。在训练初期,模型优先满足长度约束,往往以牺牲更具挑战性的正确性目标为代价。
此外,从正确性奖励的轨迹来看,GDPO 能比 GRPO 更有效地恢复并提升正确性得分,在相同训练步数下取得更高的正确性表现。此外,GRPO 的训练在约 400 步后开始出现不稳定迹象,其正确性得分逐渐下降;而 GDPO 则持续提升正确性得分,展现出更强的优化能力和训练稳定性。
尽管 GRPO 几乎达到了满分的长度奖励,但其最大响应长度在训练约 400 步后开始急剧上升;而 GDPO 的最大响应长度则持续下降,表明GDPO 始终能更好地遵循长度约束。
(2)数学推理能力
表3 GDPO 与 GRPO 训练的 DeepSeek-R1-1.5B/7B 模型在数学推理基准上的 Pass@1 准确率及超出长度约束的回答比例对比
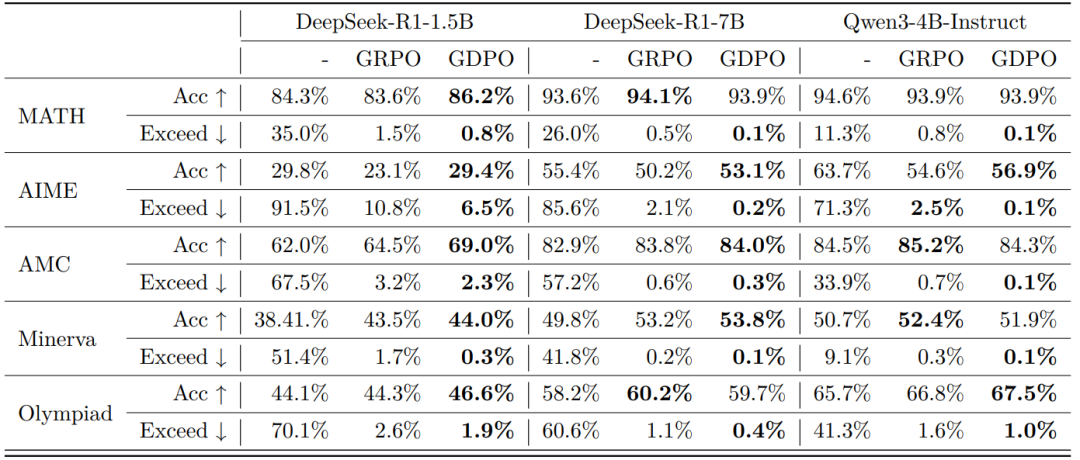
表3的基准结果表明,GDPO 训练的模型不仅在推理效率上显著优于原始模型(如在 AIME 上响应长度超限率最高降低 80%),还在多数任务上取得更高准确率。
在DeepSeek-R1-1.5B上,GDPO 在 MATH、AIME 和 Olympiad 上分别提升准确率 2.6%、6.7% 和 2.3%,同时全面降低响应长度超限率。类似趋势也出现在 DeepSeek-R1-7B 和 Qwen3-4B-Instruct 上,尤其在更具挑战性的 AIME 任务中,GDPO 将准确率提升近 3%,并将响应长度超限率降至 0.2% 和 0.1%,远优于 GRPO 的 2.1% 和 2.5%。
这些结果共同表明,GDPO 能在提升数学推理准确率的同时更有效地遵守长度约束,凸显其在多奖励优化中的优势。
为探究将较易优化的长度奖励以更具挑战性的正确性奖励为条件,是否有助于缓解两个目标之间的难度差异,并提升优先级对齐效果这一问题,将原始的长度奖励 替换为一个条件化的长度奖励 。
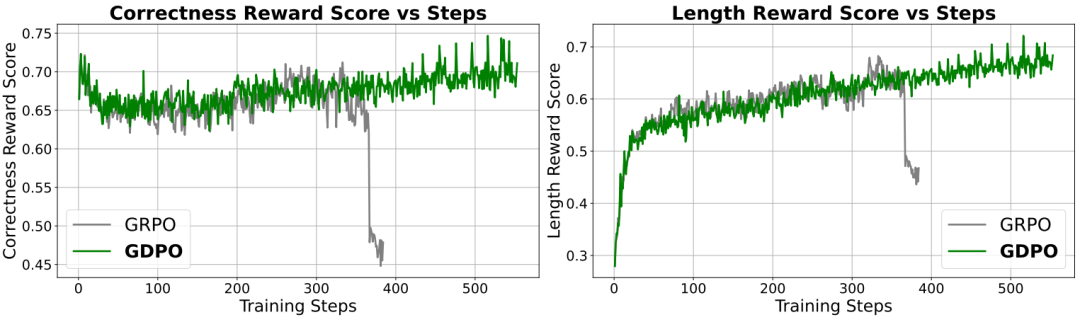
图7 在 DeepSeek-R1-7B 上使用条件化长度奖励时,GRPO 与 GDPO 的训练曲线
采用修改后的奖励函数能有效防止模型在训练初期过度追求长度奖励。这种奖励设计也有助于避免模型在满足长度约束时导致正确性奖励大幅下降。如图7所示,平均正确性奖励仅在训练早期轻微降低,随后逐步恢复。
表4 在数学推理基准上,采用与未采用条件化长度奖励GRPO 与 GDPO 训练的 DeepSeek-R1-7B 模型对比
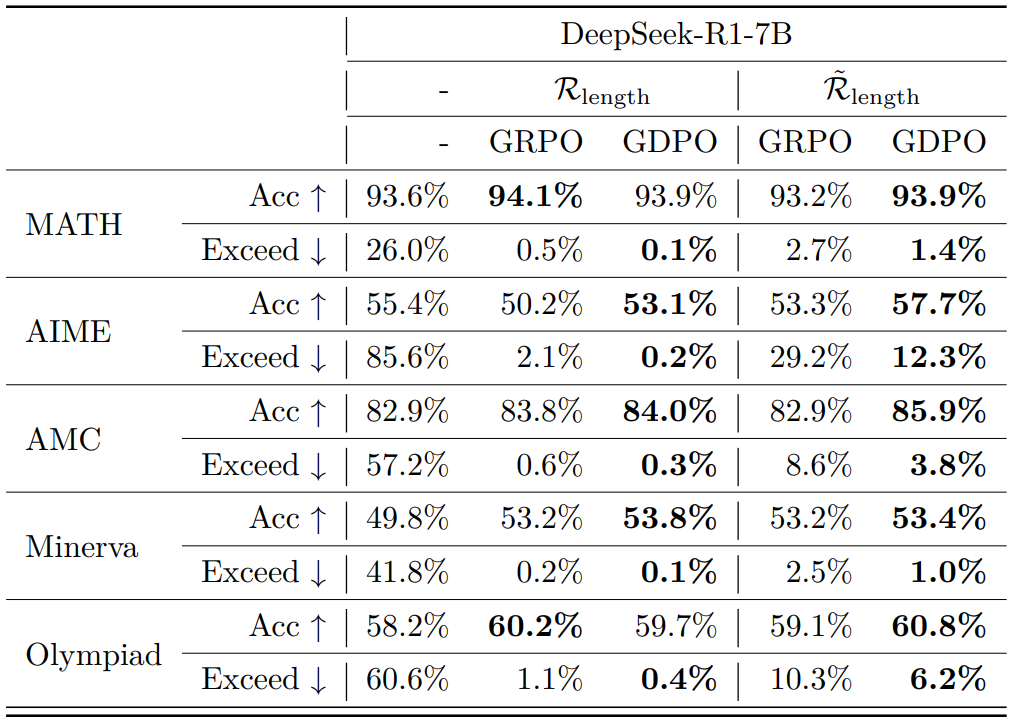
如表4所示,使用条件化长度奖励会导致 GRPO 和 GDPO 的平均长度超限率上升,表明该方法更有效地放松了长度约束。然而,GRPO 未能将这种约束放松转化为准确率提升。相比之下,GDPO 能更有效地优化准确性奖励,即使在未使用条件化奖励的情况下,其训练过程中的准确率提升也更为稳定,而引入条件化奖励后,其长度违规的增幅也显著更小。
(3)代码推理能力
表5 在代码推理基准上,对 GRPO 与 GDPO 训练的 DeepSeek-R1-7B 模型的对比结果
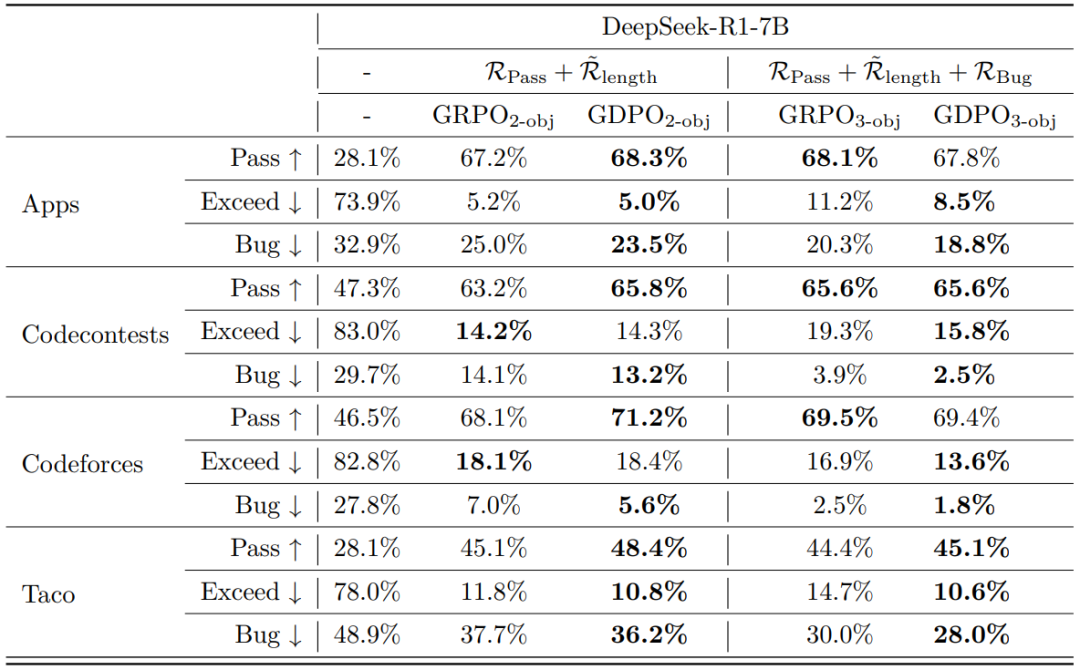
研究团队探究在代码推理任务中同时优化三个奖励时,GDPO 是否仍优于 GRPO,目标包括:提升代码正确性(通过率)、控制输出长度不超过预设限制,以及鼓励生成无缺陷(bug-free)的代码。三个目标对应的奖励分别为 , 和 。
如表 5 所示,在双奖励设置中,GDPO2-obj 在所有任务上均提升了通过率,同时长度超限率与 GRPO2-obj 相当。在三奖励设置中,GDPO3-obj 同样表现出更优的多目标平衡:其通过率与 GRPO3-obj 相当,但显著降低了长度超限率和缺陷率。总体而言,随着奖励信号数量的增加,GDPO 依然保持有效性,在双奖励和三奖励配置下均比 GRPO 实现更优的多目标权衡。










