绑定手机号
确认绑定









智猩猩AI整理
编辑:没方
强化学习推动了大型语言模型(LLM)在推理与智能体能力方面的进步,然而现有方法在探索(exploration)与利用(exploitation)两方面均面临挑战。在探索方面,现有方法在困难任务上的成功率较低,且从头开始反复执行完整推理轨迹(rollout)的成本高昂;在利用方面,存在信用分配粗糙和训练不稳定问题:轨迹级别的奖励机制会因后续错误而惩罚原本合理的前缀部分;而失败占主导的样本会淹没少数正向信号,导致优化过程缺乏建设性方向。
为此,阿里联合香港科技大学、苏州大学提出强化学习方法 R³L ,该方法引入了语言引导探索、关键点信用分配(Pivotal Credit Assignment)和正向信号增强(Positive Amplification)机制。在智能体任务和复杂推理任务上的实验表明,R³L 相较基线方法取得了 5% 至 52% 的相对性能提升,同时保持了训练的稳定性。

论文标题:R³L : Reflect-then-Retry Reinforcement Learning with Language-Guided Exploration, Pivotal Credit, and Positive Amplification
论文链接:https://arxiv.org/pdf/2601.03715
项目地址:https://github.com/shiweijiezero/R3L
01 方法
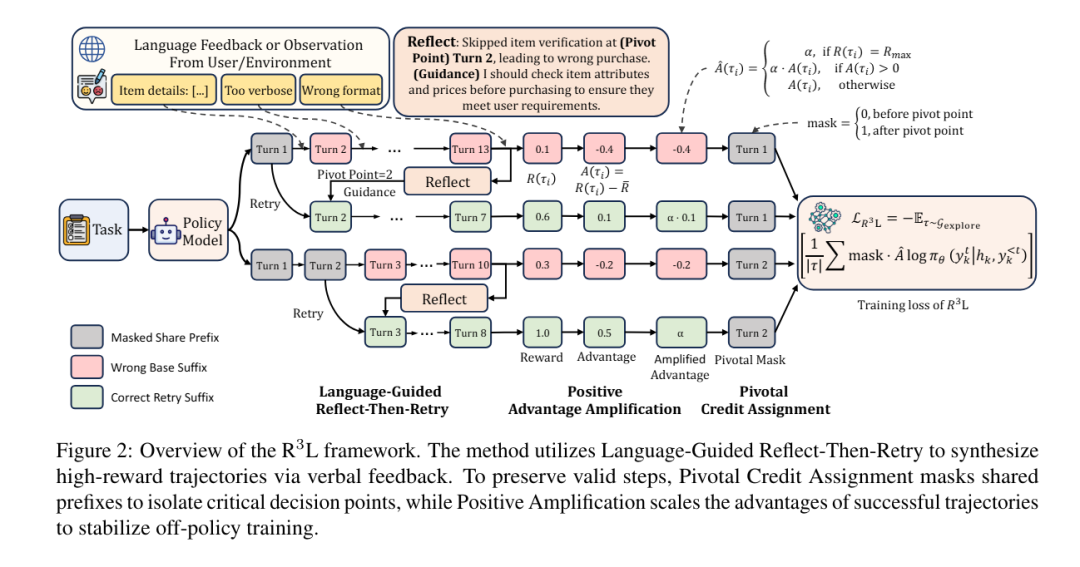
如图2所示,R³L 在轨迹合成与策略优化之间交替进行。
在合成阶段,采用“反思-重试”机制,利用语言反馈诊断失败原因,并从识别出的关键点(pivot points)重启生成过程,从而将失败尝试转化为成功轨迹。
在优化阶段,策略模型同时从原始轨迹(base trajectories)和重试轨迹(retry trajectories)中学习。研究团队引入关键点信用分配(Pivotal Credit Assignment),将梯度更新聚焦于存在对比信号的分歧后缀部分,通过增强正向信号对成功轨迹赋予更高权重,确保优化过程由正向信号主导,从而稳定off-policy训练过程。
完整的R³L训练流程如算法1所示:

(1)语言引导的反思-重试(Language-Guided Reflect-Then-Retry)
为克服随机采样成功率低的问题,R³L采用了一种“反思-重试”机制:利用语言反馈诊断失败轨迹中的错误并定位失败点,随后从这些关键点重新开启生成,并辅以修正性指导,从而以更低的 rollout 成本合成成功轨迹。值得注意的是,训练数据中会移除指导性描述,使模型在推理阶段能够内化这些修正策略。
研究团队构建了四类训练数据:
来自随机采样的基础轨迹
为了与标准强化学习方法进行公平比较,将采样预算的一半分配给标准探索,另一半用于重试样本,因此总采样量保持不变。给定一个查询 x ,从策略模型 中采样 N/2 条基础轨迹。这些轨迹既用于建立基线性能,也为后续的反思提供原始素材:
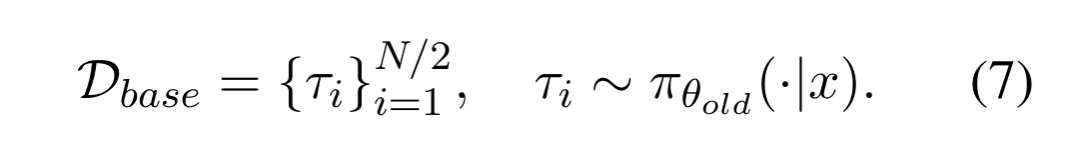
来自引导修正的蒸馏轨迹
对于每条基础样本,模型会对该轨迹进行反思并生成结构化诊断,包括结果分类(成功、成功但低效、失败)、根本原因分析、改进建议,以及问题首次显现的转折点kpivot。研究团队将转折点前的步骤称为前缀(τ<kpivot),转折点及之后的步骤称为后缀(τ≥kpivot),信用分配与轨迹拼接均在此步骤层级进行。
对于未被判定为完全成功的轨迹,该诊断结果会被嵌入到一个指导提示(guidance prompt)中,并以此为条件从转折点 kpivot重新开始生成,从而获得一个修正后的后缀。
关键的是,研究团队在构建训练样本时,将原始前缀与修正后的后缀拼接在一起,刻意省略了中间的指导提示。这一设计迫使模型内化修正逻辑,而非依赖显式的外部提示,从而确保所学能力能直接迁移到推理阶段:
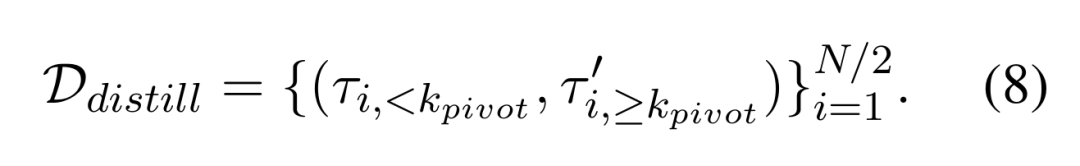
学习反思与重试
反思与重试是可学习的技能,需要在持续训练过程中通过显式监督来维持,因此研究团队设计了两项辅助任务。筛选出重试轨迹比原始尝试获得更高奖励的实例,作为经过验证的成功修正样本。
(i)反思任务训练模型在给定轨迹与环境反馈 f 的情况下生成结构化诊断 r ;
(ii)重试任务则训练模型在给定前缀与指导信息 g 拼接后(记作⊕)生成修正后缀。
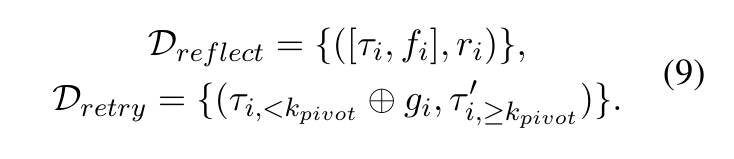
训练分组:数据集 Dbase和 Ddistill 组成用于强化学习优化的探索组Gexplore ,而 Dreflect 和 Dretry 则作为辅助的监督微调(SFT)目标,在整个训练过程中维持探索引擎。R³L将预算平均分配给基础轨迹与重试轨迹,从该组的所有样本中学习,并通过辅助任务显式维持反思与重试能力。
(2)关键信用分配
为了更精确地分配信用,研究团队有效利用探索组内部的对比结构。基础轨迹与蒸馏轨迹在转折点kpivot之前具有完全相同的前缀,该共享部分无法提供关于哪条路径更优的信息,只有在分歧的后缀部分才揭示哪个决策是正确的。
研究团队引入梯度掩码(gradient mask)将共享前缀从参数更新中排除。对于第 k 轮中的第 t 个 token,掩码定义如下:
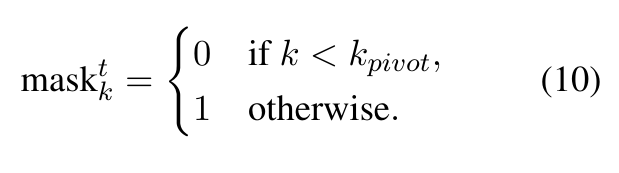
转折点之前的 token 在梯度计算中被赋予零权重,从而使优化聚焦于关键的分支决策。
(3)正向增强(Positive Amplification)
鉴于困难任务中失败样本占主导地位,且“反思-重试”会生成off-policy的数据,可能引发训练不稳定,R³L引入正向信号增强机制,只需引入统一的放大因子 α>1即可满足要求,轨迹优势定义为:
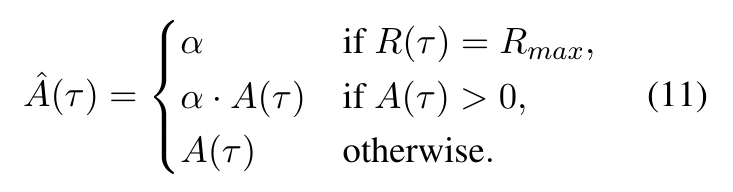
在组内获得最大奖励的轨迹将获得完整的放大因子 α ,其他具有正优势的轨迹按比例缩放,而负优势的轨迹保持不变。通过放大正向优势,建设性梯度变得足够强从而在组内占据主导地位,引导概率质量集中于已发现的有效解,而非任其分散。研究团队发现 α=3.0在多种任务上均表现良好。
结合关键点掩码与优势增强,R³L的目标函数为:
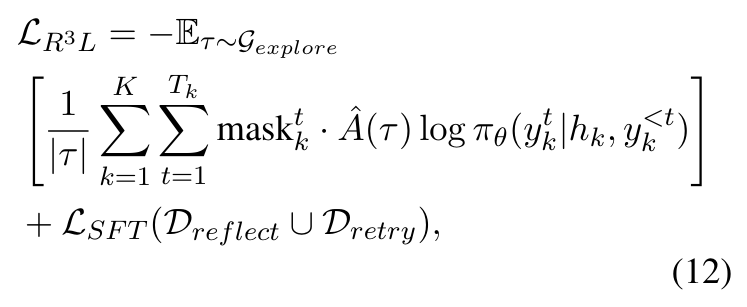
其中 ,LSFT 是在经过验证的成功修正样本上进行的辅助监督微调损失,用于在训练过程中维持模型的反思与重试能力。与标准 GRPO 不同,研究团队移除了重要性采样和 KL约束:
重要性采样在处理由指导生成的重试轨迹时不可靠,因为其行为分布与当前策略存在差异;
KL 约束不再必要,因为正向信号增强已能有效防止策略向高熵方向漂移。
这种简化降低了内存开销和计算成本,同时仍保持训练的稳定。
02 评估
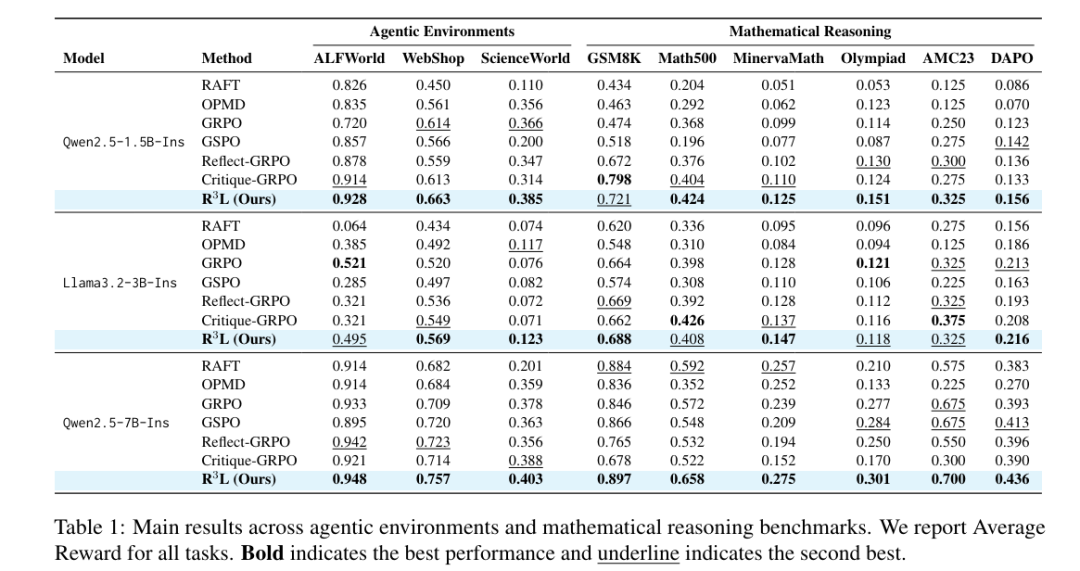
表1展示了R³L与不同强化学习方法,在智能体环境和数学推理基准上的评估结果。
在智能体环境中,R³L 在 9 项设置中 8 项排名第一。使用1.5B模型时,在ALFWorld、WebShop 和 ScienceWorld 上分别达到 0.928、0.663 和 0.385。其提升在 WebShop 和 ScienceWorld 上尤为显著,分别超越最强基线 8.0% 和 5.2%,这得益于关键点信用分配有效保护了正确前缀免受后续错误的惩罚。
在数学推理任务上,使用 7B 模型的R³L 在 GSM8K、Math500 和 OlympiadBench 上分别达到 0.897、0.658 和 0.301。未取得第一的是1.5B 模型在 GSM8K 上的表现,Critique-GRPO以0.798略胜R³L 0.721。原因在于 GSM8K 任务相对简单,随机采样已能产生足够多的成功轨迹。尽管如此,R³L 相较GRPO仍在GSM8K实现了52%的性能提升。而对于其他更复杂的基准任务,则需要精心设计的机制来实现高质量轨迹合成、细粒度信用分配以及从稀疏正向信号中稳定学习来实现突破。
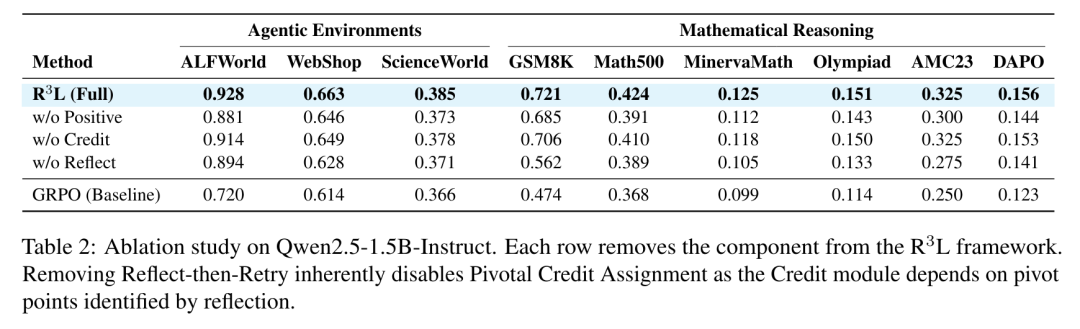
消融实验结果如表2所示。
移除反思-重试机制会导致严重的性能下降。在GSM8K上,从 0.721 降至 0.562;在WebShop上,从 0.663 降至 0.628。这表明仅靠随机采样无法有效探索稀疏奖励环境,而主动的轨迹合成对于发现有效解至关重要。
去除正向增强会导致所有基准的性能下降。在ALFWorld上,从 0.928 降至 0.881;在GSM8K上,从 0.721 降至 0.685。在以失败样本为主的场景,大量负样本会淹没稀少的正向信号;若无增强机制,梯度更新将聚焦于抑制错误,而非强化正确路径。
去除关键点信用分配带来的影响虽最小但保持一致,在ALFWorld上,从 0.928 降至 0.914;在GSM8K上 ,从 0.721 降至 0.706。该机制在长周期任务中效果最为显著,因为当错误发生时轨迹级奖励往往会惩罚原本有效的前缀步骤。










