绑定手机号
确认绑定









智猩猩AI整理
编辑:宁宁
过去一年,Agent 的主线几乎都围绕“深度推理”展开:怎么让模型更会分解任务,怎么让它走更长的思维链,怎么通过工具调用完成复杂问题。但研究团队提出了一个提醒:真实世界中的网页信息搜索,很多时候难点不只是“想得深不深”,而是能不能在大量异构网页中做大范围发现、交叉验证与结果综合。 一旦任务要求系统跨多个网页搜集证据、补齐结构化字段、避免遗漏关键实体,很多现有 LLM Agent 就会遇到三类典型问题:上下文迅速饱和、前面步骤的错误不断累积、整条执行链路耗时过高。因此研究团队指出单纯扩大上下文窗口或堆更强模型,并不能从根本上解决这类“宽信息综合”任务的结构性瓶颈。
针对这一痛点,华为诺亚方舟实验室、利物浦大学和伦敦大学学院的研究者联合提出了 InfoSeeker。一套面向 Web 信息搜索的可扩展层次化并行 Agent 框架。它基于 near-decomposability(近可分解性)思想,把系统拆分为负责全局规划的 Host、负责任务拆解与结果聚合的 Managers,以及负责具体工具执行的 Workers。实验表明这套框架不仅在 WideSearch 和 BrowseComp-zh 两个基准上取得了更好的效果,还在推理效率上显著领先商业 Deep Research 系统:在 WideSearch-en 上达到 8.4% success rate,在 BrowseComp-zh 上达到 52.9% accuracy,并带来明显的时间优势。

论文标题:InfoSeeker: A Scalable Hierarchical Parallel Agent Framework for Web Information Seeking
论文链接:https://arxiv.org/abs/2604.02971v1
GitHub 仓库地址:https://github.com/agent-on-the-fly/InfoSeeker
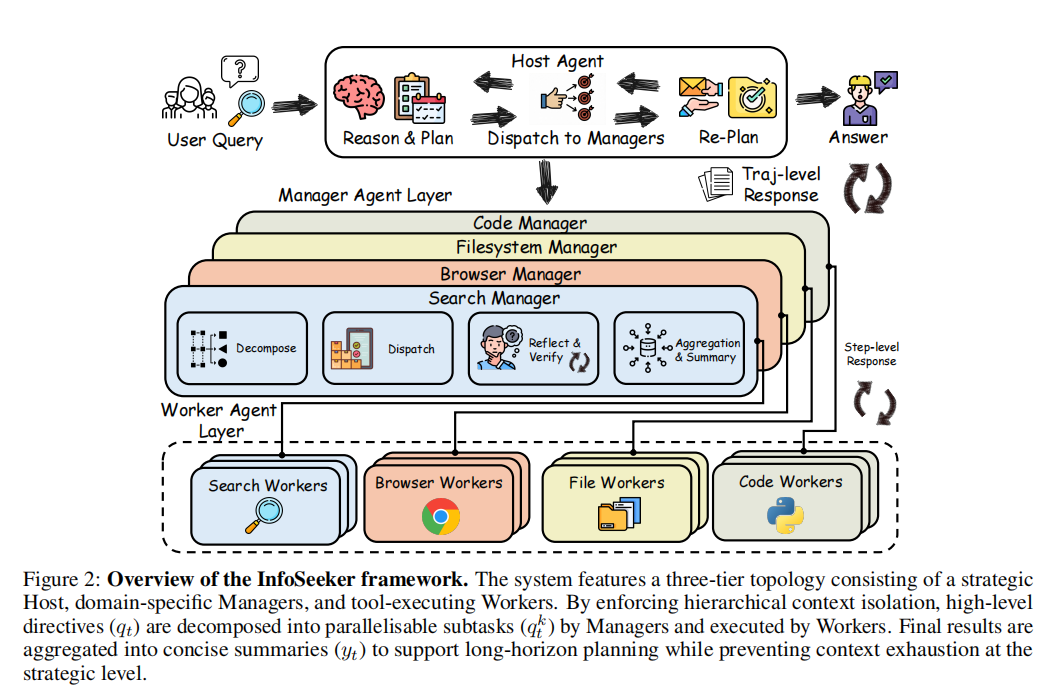
图1 InfoSeeker整体框架:通过 Host-Manager-Worker 的分层并行设计,将高层规划、中层调度和底层执行解耦。
InfoSeeker不是简单“多加几个 Agent”,而是把复杂搜索任务拆成了真正有分工边界的层次结构,如图1所示。最上层的 Host Agent 负责全局规划:理解用户问题、决定当前应该做什么、把任务交给合适的 Manager,并根据阶段性结果继续推进。它不会直接阅读底层所有网页内容,也不会处理每一次工具调用细节,而是始终只维护“高层步骤—摘要结果”这一层信息。这样高层上下文不会被海量中间过程迅速挤爆,系统也更容易在长链条任务中保持整体判断能力。
中间层的 Manager Agents 则是整套系统真正的组织中枢。某个 Manager 接到 Host 下发的任务后,会先把它拆成一组可并行执行的子任务,再分发给对应的 Worker 去完成。更关键的是,Manager 不是“只会分发”的中间人,它还承担了反思、验证和聚合的职责:如果某些结果不完整、互相冲突,或者没有回答当前步骤真正想解决的问题,Manager 会修订任务并重新派发,直到结果满足要求,最后再把这些信息压缩成一份适合高层继续推理的摘要。
最底层的 Worker Agents 专注于具体执行。每个 Worker 一次只执行一个明确子任务,并通过其所属域的 MCP 工具完成操作;不同类型的 Workers 分别服务于搜索、浏览器、文件系统和代码执行等不同任务域。Worker 会在本地保留完整执行轨迹,但向上只返回任务结果。这样,底层工具交互的复杂度就不会污染上层推理。InfoSeeker 把“会不会规划”“会不会组织”“会不会执行”拆成了三个层次来处理,而不是把所有复杂性都塞进同一个长上下文里。
从执行方式上看,InfoSeeker本质上采用了一种接近 MapReduce 的思路:高层顺序规划,中层拆解任务,底层并行执行,最后再把结果汇总回来。研究团队强调这种设计把推理深度和执行宽度分离开了。传统单Agent往往是一边想、一边查、一边记,最后所有细节都压在同一个上下文里;而InfoSeeker则让系统可以一边保持高层规划,一边把大量弱耦合子任务分散到多个 Worker 同时完成。
为了验证框架是否真的适用于“宽信息搜索”,研究团队选用了两个互补基准。
(i)WideSearch:要求系统从多个异构来源中找齐信息并填充表格,重点考察实体发现、属性核验和结构完整性;
(ii)BrowseComp-zh:聚焦中文互联网环境下的网页导航与多跳推理,更接近真实中文Web场景。前者偏“广度信息综合”,后者偏“中文浏览推理”,两者一起构成了对系统能力的完整检验。
实现上,InfoSeeker 采用了异构模型组合:Host 和 Managers 使用 gpt-5.1,以保证高质量规划与聚合;Worker pools 使用 gpt-5-mini,以兼顾大规模执行时的吞吐与成本效率。工具通过 MCP 接入 Firecrawl、Playwright、Python 和文件系统组件,其中浏览器环境专门配置了完整字体渲染,以支持更准确的中文 OCR。
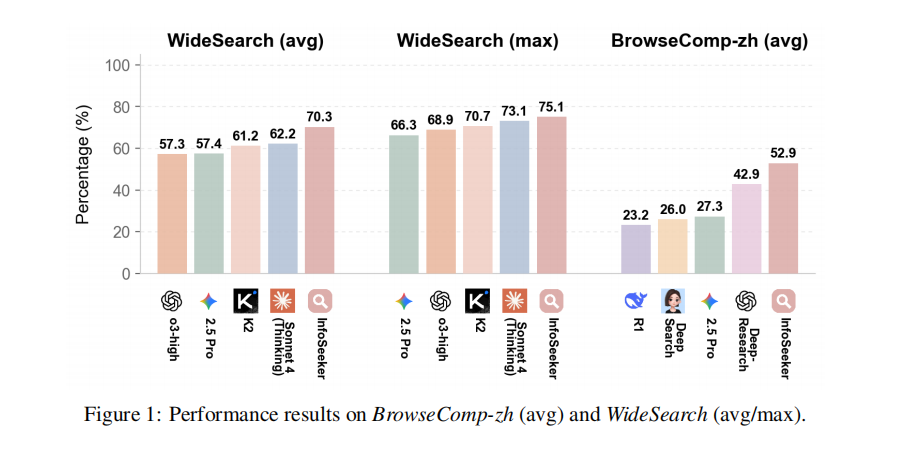
图2 InfoSeeker在 BrowseComp-zh 与 WideSearch 上的总体表现,对比商业 Deep Research 系统和多个强基线均有优势。
结果方面,InfoSeeker 在 WideSearch-en 上显著超过多类基线。在 Avg@4 Success Rate 上,InfoSeeker 相比最强基线 OpenAI o3-high Multi-Agent 提升约64%;同时,Row-level F1 达到 50.13%,Item-level F1 达到 70.27%。这表明层次化并行架构在宽域信息综合任务上,不仅更容易完成整题,也更擅长把结构化结果中的行和字段填对。
在 BrowseComp-zh 上,InfoSeeker取得 52.9% Accuracy,超过 OpenAI DeepResearch 的 42.9%,也高于 BrowseMaster 等开源浏览Agent框架,如图2所示。该框架的优势不局限于英文表格填充,而是在中文网页导航、跨页面证据对齐和多步推理场景中同样成立。研究团队认为这与其把高层推理和环境交互解耦的架构设计密切相关。
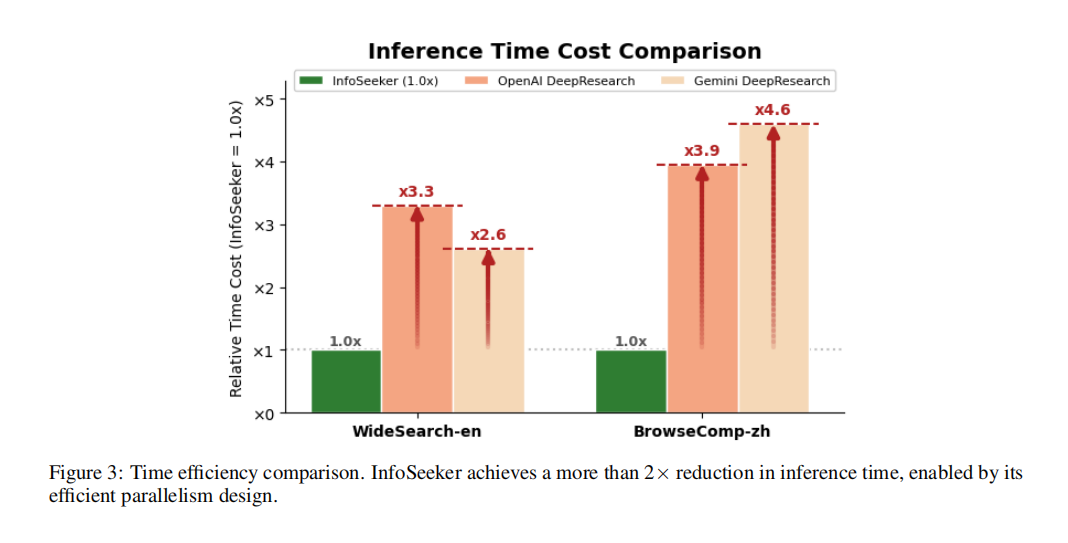
图3 时间效率对比:InfoSeeker 通过并行 worker 显著降低端到端推理耗时。
效率层面,InfoSeeker的优势更加直观,如图3所示。研究团队将自身耗时归一化为 1.0 后比较发现:在WideSearch-en 上,OpenAI Deep Research 和 Gemini Deep Research 分别需要 3.3倍 和 2.6倍 时间;在 BrowseComp-zh 上,这两个系统分别需要 3.9倍 和 4.6倍 时间。与此同时,消融实验显示当 Worker 数从 1 提升到 17 时,端到端时延可由 911秒降到162秒,达到约 5.7倍加速,如图4所示。这说明 InfoSeeker 的并行化不是概念层面的,而是切实转化成了真实可观的系统吞吐提升。
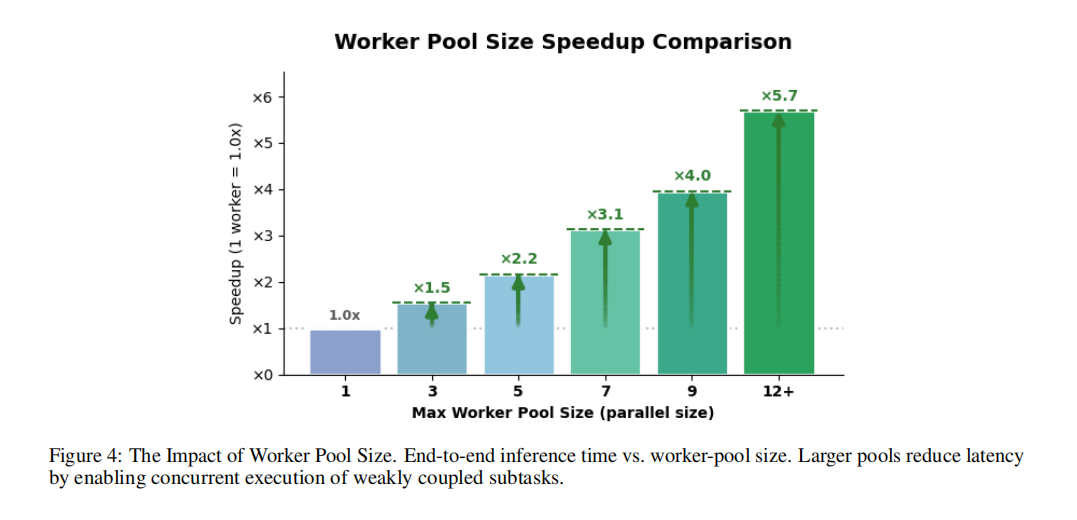
图4 Worker 数量消融:并行规模扩大后,InfoSeeker 的端到端延迟显著下降。
InfoSeeker 重新提醒我们:搜索型 Agent 的上限,不只取决于模型能否做更深的推理,也取决于系统能否在大规模异构网页中高效组织信息流。
InfoSeeker 最值得关注的地方,不只是提出了一个新框架,而是展示了一种更适合 Web 信息搜索的工程组织方式:用 Host、Manager、Worker 的层次化结构,把高层规划、中层调度、底层执行严格解耦,再通过上下文隔离、反思聚合和大规模并行,同时缓解上下文饱和、误差传播与端到端时延问题。










