绑定手机号
确认绑定









论文一作投稿
智猩猩AI整理
金融研报、法律卷宗、学术长文这类超长、多源、嘈杂的文档,是长文档问答(Long-document QA)的核心应用场景,却也是AI落地的天堑。
直接让大模型对原始长文本推理,证据散落、幻觉频发、结果无追溯,金融、法律等高敏感领域完全无法使用;
依托GPT-4o、DeepSeek-R1等超大模型生成结构化数据,更是绕不开三大痛点:
推理延迟高、Token成本爆炸,难以规模化部署。
云端API调用,敏感数据(金融/法律)隐私无保障。
3B–7B小模型原生缺失Schema感知、实体归一化、记录对齐能力,直接替换效果极差。
一边是大模型的高成本、高延迟、隐私不可控,一边是小模型的低能力、低可靠,长文档QA始终没有兼顾性能与效率的最优解。
为此,来自香港科技大学(广州)、Evenup (USA) 的研究团队提出LiteCoST框架,创新性地将大模型的结构化思维「蒸馏」至轻量小模型,让3B/7B小模型媲美GPT-4o,推理速度还快2-4倍。该成果已被ICLR 2026接收,模型与代码已开源。

论文链接:https://arxiv.org/abs/2603.29232
代码地址:https://github.com/HKUSTDial/LiteCoST
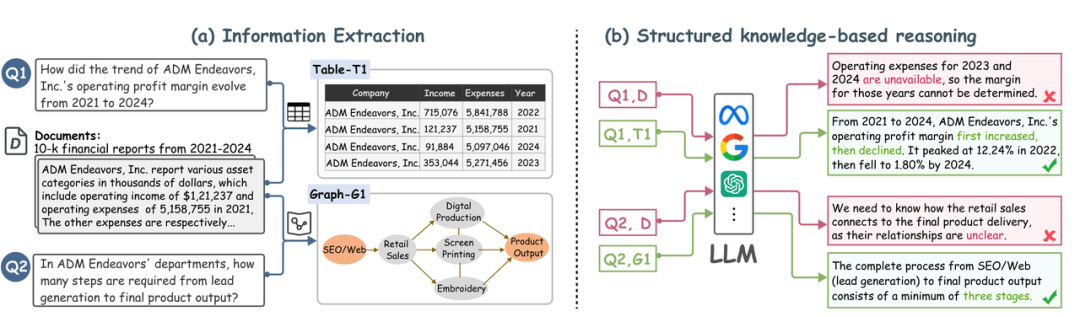
困境1:大模型落地,逃不开「三高」枷锁
依赖GPT-4o、DeepSeek-R1等大模型做结构化抽取,会陷入高成本、高延迟、高隐私风险的三重困境:
成本端:频繁调用大模型导致Token消耗与算力成本急剧攀升,产业落地性价比极低;
效率端:大模型推理速度慢,无法满足线上业务低延迟、高吞吐的核心需求;
安全端:云端API部署会泄露金融、法律等敏感数据,合规风险难以规避。
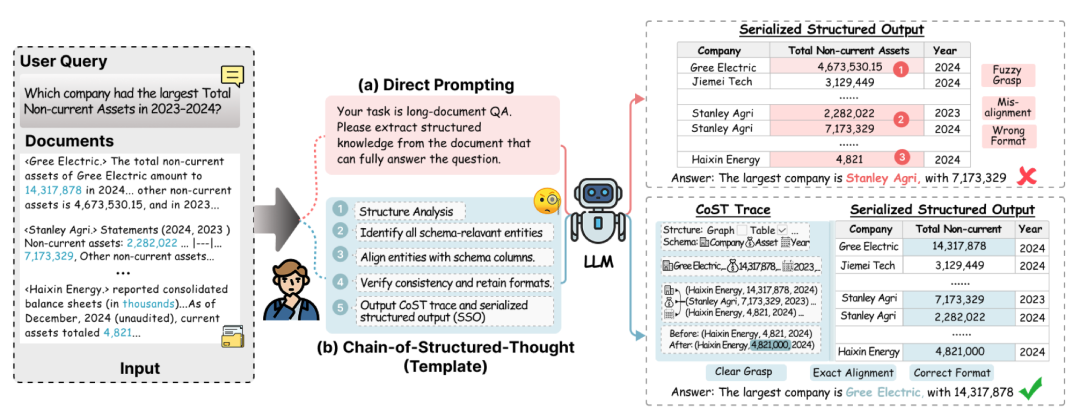
更关键的是,大模型直接生成结构化产物时,还存在证据遗漏、格式不统一、结构一致性缺失等问题,最终输出的结果缺乏可审计性,难以支撑专业场景应用。
困境2:小模型落地,缺核心「结构化能力」
3B–7B小模型是兼顾成本与隐私的最优解,但原生小模型不具备长文档结构化推理的核心技能——既无法感知复杂Schema、对齐多源实体信息,也不能生成标准化的结构化输出,短文本指令微调又无法覆盖长文档的复杂推理需求,直接导致落地效果大打折扣。
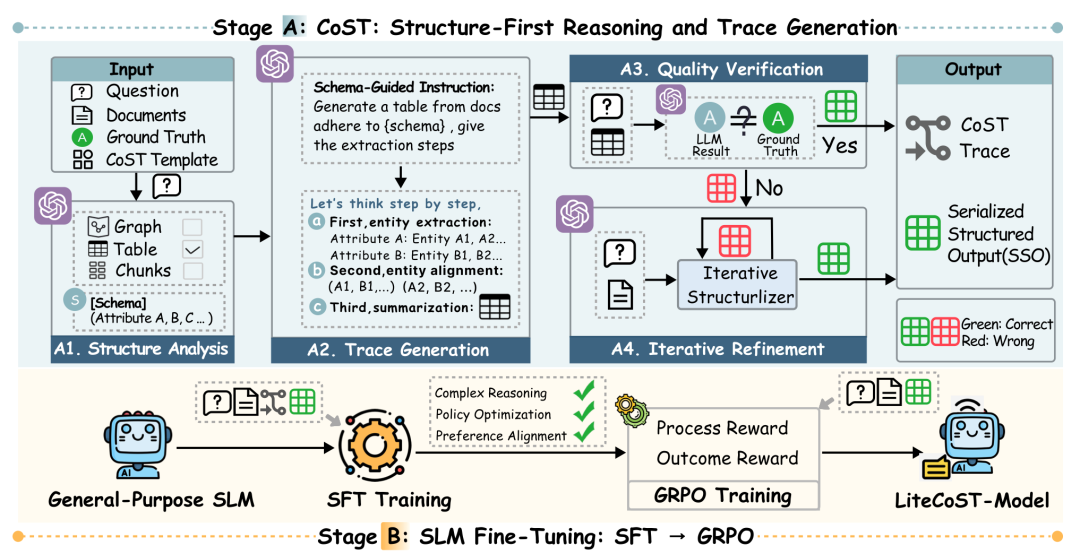
LiteCoST的核心思路,就是以大模型为「导师」输出高质量结构化监督信号,以小模型为「学生」高效吸收迁移,最终实现精准与轻量化的完美平衡。
作为双阶段框架,LiteCoST直击两大核心目标:
(1)用CoST结构思维链实现准确、可核验的长文档QA;
(2)用轻量小模型实现低延迟、私有化的高效推理。
结构化思维链(CoST,Chain-of-Structured-Thought) 是LiteCoST的核心引擎,由大模型完成一次性高质量推理,生成两大关键产物,为小模型学习提供纯净监督信号:
(1)可审计推理轨迹:完整留存「结构分析→证据对齐→实体归一→质量核验」的全流程,每一步推理都可追溯,彻底解决「结果可信但过程不可查」的问题;
(2)标准化结构化输出:支持表格、图谱、列表等多种格式,与源文档证据严格绑定,实现机器可校验、人工可复核。
大模型通过「四步闭环」生成高质量监督数据:
结构分析:动态匹配最优Schema,生成针对问题的最小化结构框架;
轨迹生成:同步输出推理记录与标准化结构化输出;
质量核验:通过LLM-as-Judge机制,过滤低质量样本,确保数据纯净度;
迭代优化:对不合格样本重新推理,打磨监督信号质量。
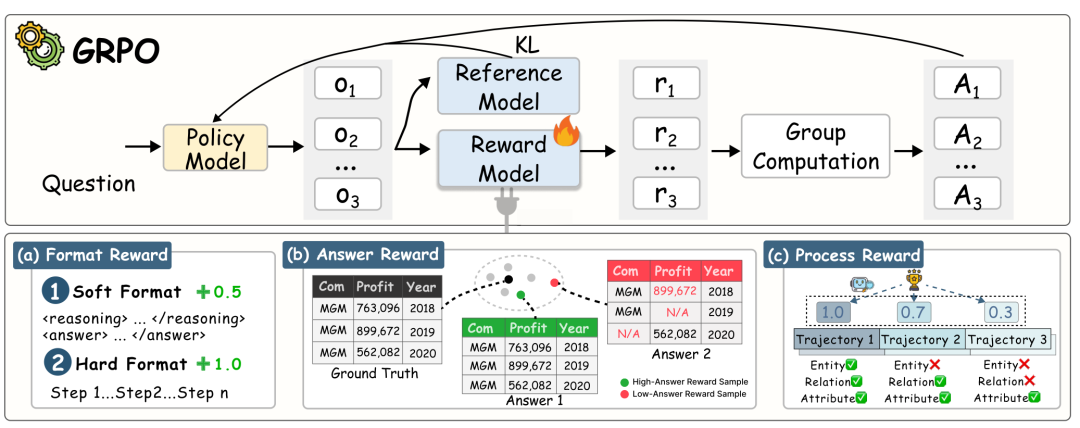
基于大模型生成的高质量数据,LiteCoST通过「双阶段轻量化微调」,将结构化思维高效迁移至小模型,彻底突破传统短文本微调的局限:
(1)监督微调(SFT):让小模型完成结构、格式、步骤三维对齐,掌握基础结构化生成能力。
(2)分组相对策略优化(GRPO):创新三重联合奖励,同时约束结果与过程。
格式合规奖励:保证输出严格遵循 CoST 范式
答案正确性奖励:从结构对齐与语义匹配校验准确性
推理过程一致性奖励:逐步骤监督推理,贴合原文证据
小模型不仅能输出正确结果,更能复刻大模型的可靠推理链路,实现结果精准 + 过程可信的双重目标。
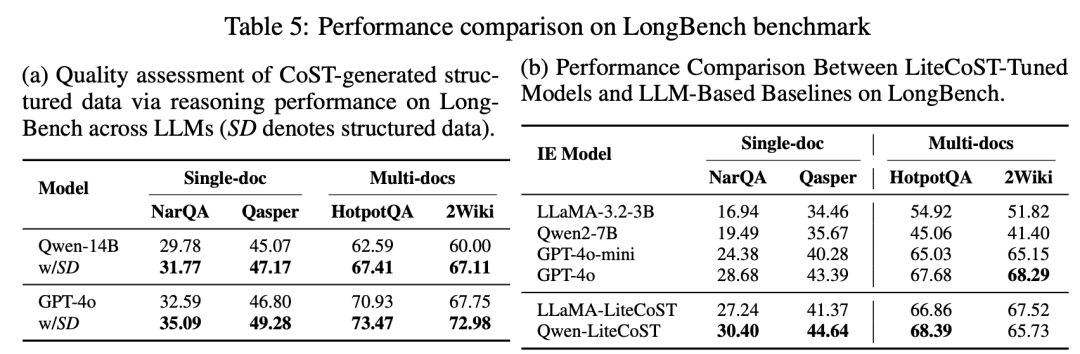
LiteCoST在两大权威长文档QA基准上完成全面评测:Loong 覆盖金融、法律、科研文献三大领域共 1600 条测试样本,LongBench 聚焦四大数据集的单文档与多文档 QA 任务,全面验证模型效果。
(1)性能拉满:小模型媲美大模型
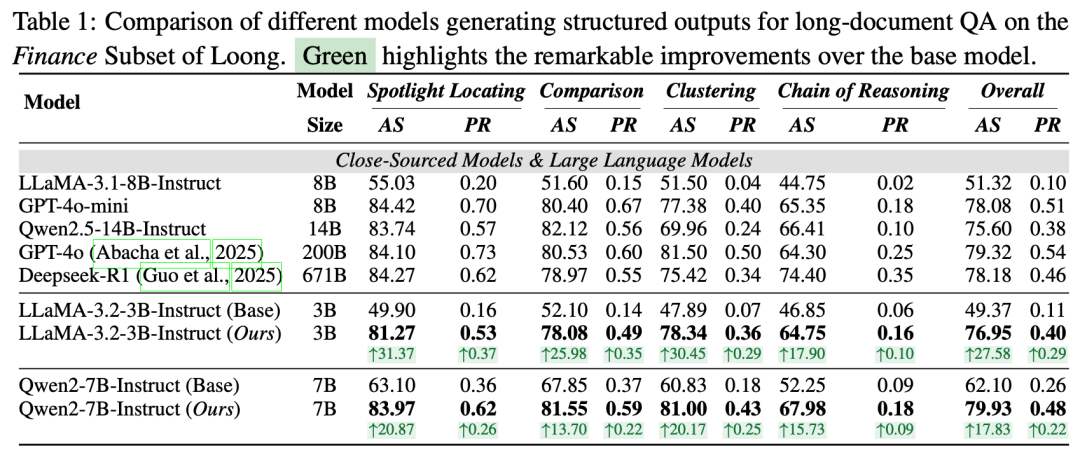
结构化数据赋能大模型:Qwen2-72B、GPT-4omini、GPT-4o、Claude-3.5Sonnet等大模型,借助CoST生成的结构化数据,得分分别提升12.41、8.77、9.04、8.47分,完美率同步提升,充分证明结构化知识对精度的核心增益;
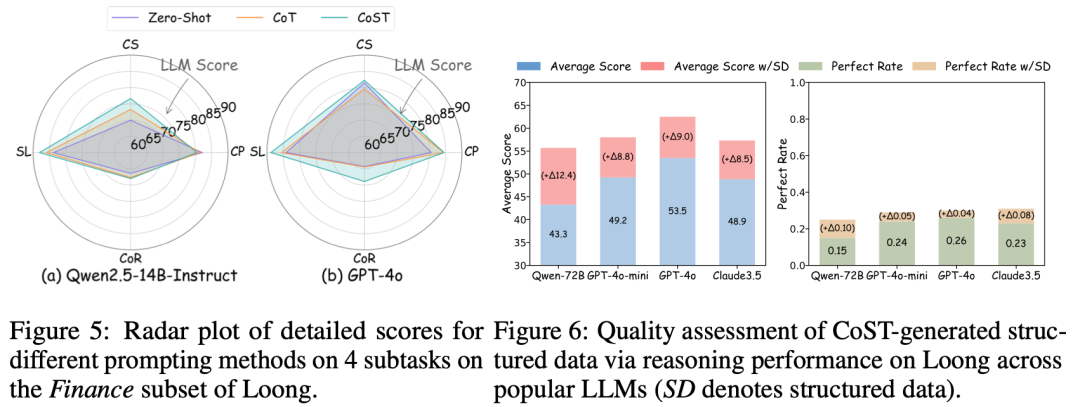
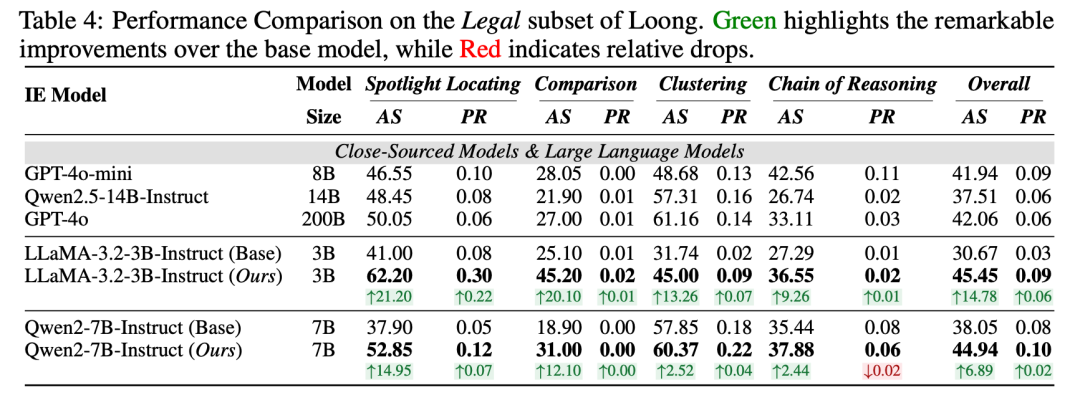
LiteCoST小模型效果炸裂:在金融场景中,LLaMA-3B+LiteCoST得分提升27.6个点、完美率提升0.29;Qwen-7B+LiteCoST得分提升17.8个点、完美率提升0.22,综合表现超越GPT-4o;
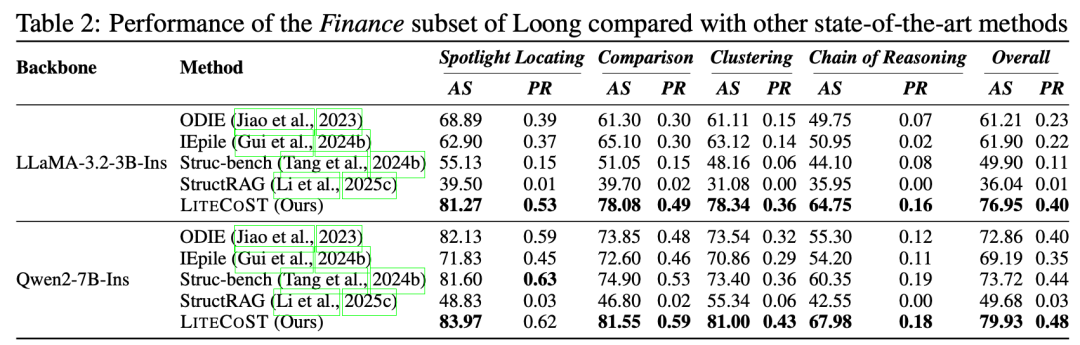
强化学习较传统微调更优:相较于 StructRAG、IEPile、Strucbench 等 SOTA 基线,LiteCoST 在 LLaMA 骨干上分别提升 30.91/15.05 分、完美率提升 0.39/0.18,在 Qwen 骨干上分别提升 30.47/6.41 分、完美率提升 0.46/0.05,RL 强化框架彻底超越传统微调方案。
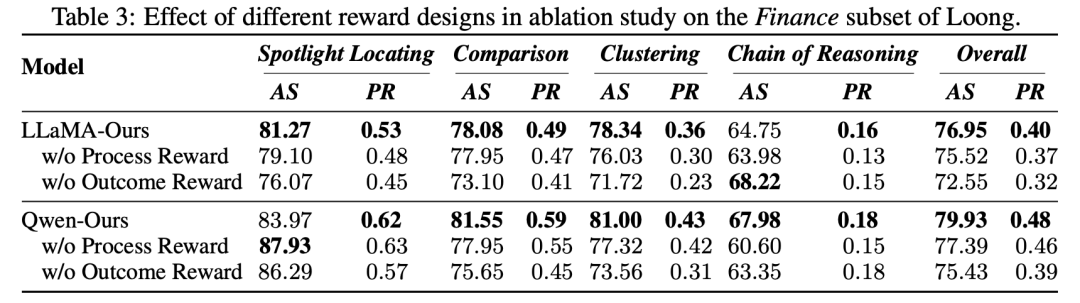
RL 三重奖励协同铸就稳健提升:格式,过程与结果奖励协同发力,三者互补形成更稳健的训练策略,精细化监督有效引导分步抽取、保障答案正确性,为模型性能跃升提供核心支撑。
(2)效率碾压:延迟直降,零门槛本地部署
LiteCoST微调的小模型,实现效率与性能的完美平衡:
推理延迟:仅为GPT-4o的1/2、DeepSeek-R1(671B)的1/4,LLaMA-3B推理延迟低至8.04s;
部署成本:无需依赖云端API,单台八卡RTX 4090即可完成本地运行,数据隐私与部署成本双重优化。
(3) 泛化超强:全场景适配不翻车
无论是金融、法律等专业领域,还是开放域单/多文档QA场景,LiteCoST都能保持稳定优异表现。
法律场景:3B小模型较GPT-4o平均得分提升3.39分、完美率提升0.03,跨域适配能力突出;
开放域场景:LongBench任务中较现有SOTA模型平均提升5.8分,四大数据集全面领先。
从大模型 “精准却昂贵” 的落地桎梏,到小模型 “廉价却无力” 的能力瓶颈,LiteCoST 另辟蹊径,以结构化思维蒸馏搭配轻量化双阶段微调,为轻量小模型赋予了比肩大模型的专业推理能力。
它精准破解了小模型长文档结构化推理能力匮乏、大模型部署成本高企、隐私合规风险凸显的行业痛点,让金融、法律、科研等专业领域的长文本处理,得以挣脱模型体量与成本门槛的双重束缚。
未来,长文档理解将真正迈入「轻量化、低成本、高可信」的新时代,普通用户可轻松解锁超长文档的核心价值,专业从业者能高效驾驭海量文本的分析工作,为长文档 AI 的产业落地擘画了更广阔的发展图景。










