绑定手机号
确认绑定









智猩猩AI整理
编辑:发发
大型语言模型(LLM)的快速发展已成为现代人工智能的核心支柱,推动了从自然语言理解到复杂推理等一系列任务的突破性进展 。然而,该领域仍面临一个长期挑战:功能强大的闭源模型与其开源同类模型之间存在性能差距。这种差距通常源于开发者可获取的海量专有高质量训练数据和巨大的计算资源 。在需要长时间思维链和严谨问题解决能力的推理密集型任务中,这种差距尤为明显 。因此,研究界面临着一个重大瓶颈:如何在不依赖这些专属优势的情况下,有效赋能开源模型,使其达到SOTA性能。
克服这一瓶颈的关键途径是生成高质量、多样化且可扩展的指令数据,用于监督微调(SFT)和强化学习(RL)。现有方法通常依赖人工标注或从更大的教师模型中蒸馏,这些方法要么成本过高、规模受限,要么存在继承教师模型局限性的风险 。关键问题在于,标准蒸馏通常只捕捉最终答案,无法传递复杂问题解决所需的复杂 “思维过程”。
为此,OPPO AI Agent团队提出O-Researcher框架,利用Open Ended的特性,通过多智能体驱动的端到端深度研究数据合成,结合创新的两阶段训练策略,使开源模型无需依赖专有数据或模型,在主流深度研究基准上实现新的SOTA性能。该研究为开源大型语言模型的发展提供了一条可扩展且有效的路径,无需依赖专有数据或模型。

论文标题:O-Researcher: An Open Ended Deep Research Model viaMulti-Agent Distillation and Agentic RL
论文链接:https://arxiv.org/pdf/2601.03743
代码链接:https://github.com/OPPO-PersonalAI/O-Researcher
01 方法
(1)用于监督微调(SFT)的高质量轨迹生成
研究团队的基础方法建立在精心策划的深度研究工具集成推理轨迹数据集上。该过程涉及两个关键步骤:数据合成和轨迹合成。
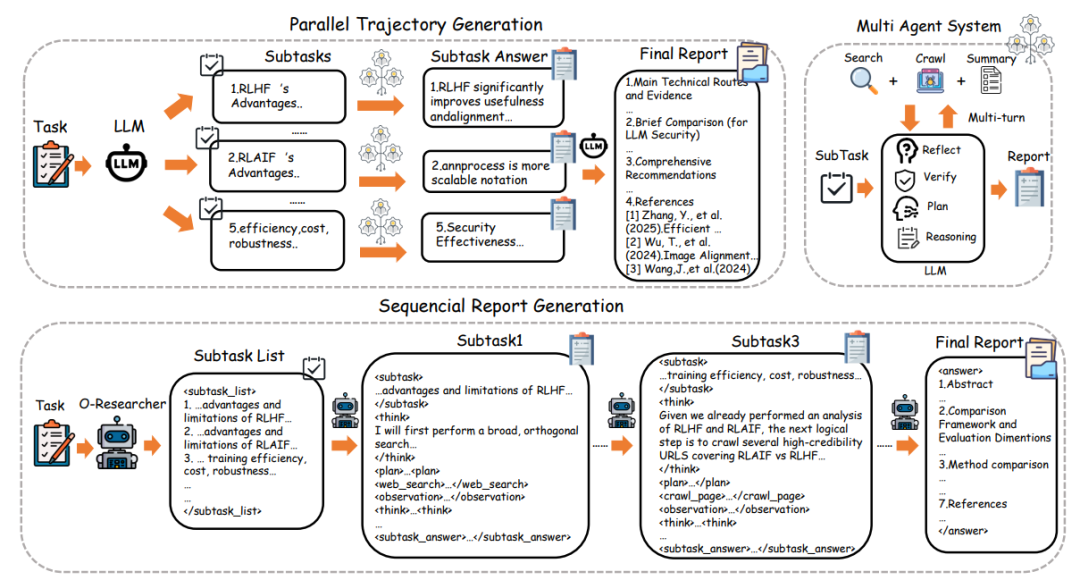
图1:O - Researcher的报告生成过程
并行执行工作流:如图1所示,研究团队设计了一种并行执行工作流来生成研究报告,模拟研究团队中的严格分工。不同模型独立进行多轮工具集成推理,执行连续的"计划-执行-观察"循环以生成详细的子查询报告。这些中间报告随后由专用的总结器模型聚合形成最终答案。同时,所有子报告的基础轨迹被收集合并为单个SFT推理轨迹,确保训练数据捕捉到并行推理过程的全部深度。
质量保证流程:为确保生成高保真训练数据,研究团队设计了全面的多阶段拒绝采样流水线。该流程从为每个查询生成三个不同的候选轨迹开始,然后进行基于规则的硬拒绝检查,包括完整性、上下文长度(≤64k tokens)、复杂性阈值(≥10推理步和5个不同工具使用动作)和一致性。通过确定性检查的轨迹继续进行基于Qwen3的LLM-as-a-Judge语义评估,最后进行主题分层的人工抽查作为最终验证层。
结构化数据表示:研究团队使用连贯的XML风格模式序列化轨迹,训练序列被结构化以明确暴露模型的逐步推理和工具使用行为。
(2)基于 AI 反馈的强化学习(RLAIF)
为进一步提升模型生成高质量、新颖、全面研究报告的能力,研究团队引入强化学习阶段,采用GRPO算法。
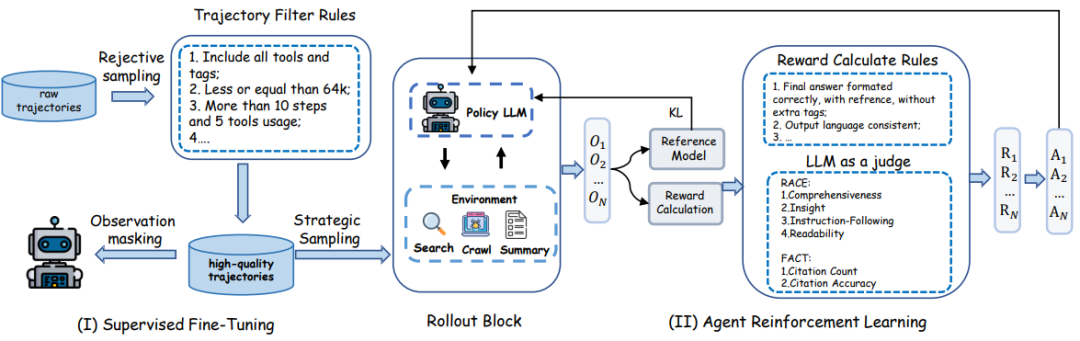
图2:深层研究模型训练过程
奖励函数设计:研究团队的奖励函数旨在平衡报告质量、工具利用效率和格式合规性,公式化为三个主要组件的加权组合:
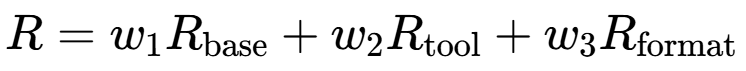
研究团队设置 w1=0.6,w2=0.2和 w3=0.2,更强调高质量报告生成,同时仍鼓励适当的工具使用行为。基础质量奖励Rbase从评估每个(问题,生成报告)对的LLM-as-a-Judge获得,沿四个维度计算:全面性、洞察力、指令遵循性和可读性。
工具使用奖励:为鼓励适当的证据收集,研究团队定义,Ncalls=min(web_search, crawl_page),Nmin=2,Nmax=8。工具使用奖励为:
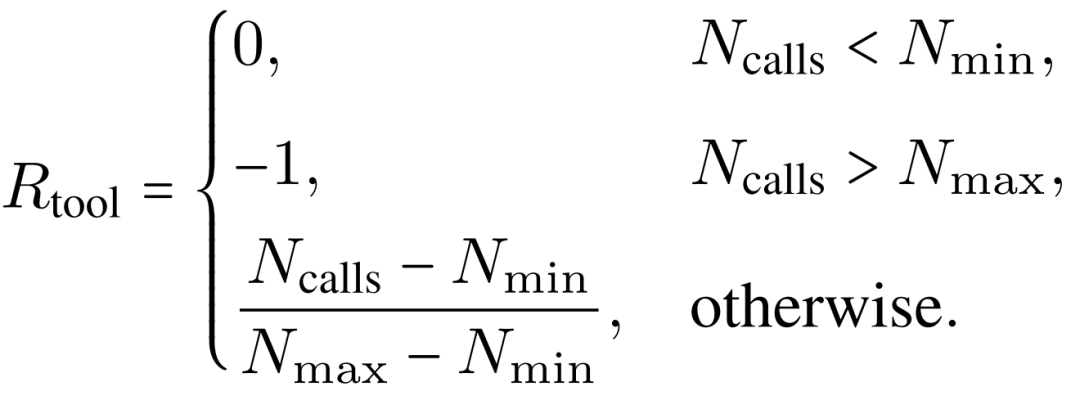
格式化奖励:格式化奖励强制执行结构正确性,验证两个严格条件:
所有XML风格标签必须对称闭合
输出必须包含<suggested_answer>标签。违反任一条件都会产生零格式化奖励
(3)并行执行与推理步骤优化
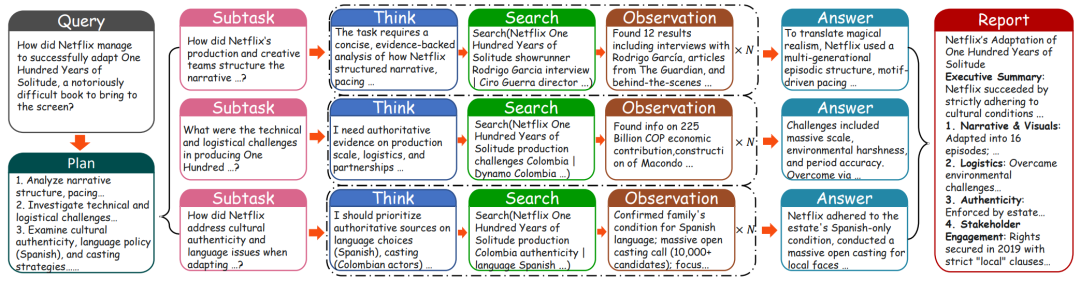
图3:并行执行定性案例研究
并行执行优势:为定量评估并行执行策略的影响,研究团队比较了GPT-5使用和不使用并行执行工作流的性能。如图3所示,通过案例研究展示了并行执行在复杂任务中的有效性。
推理步骤优化:研究团队尝试了三种不同的工作流步骤:5、10和20。
02 评估
(1)DeepResearch Bench基准结果
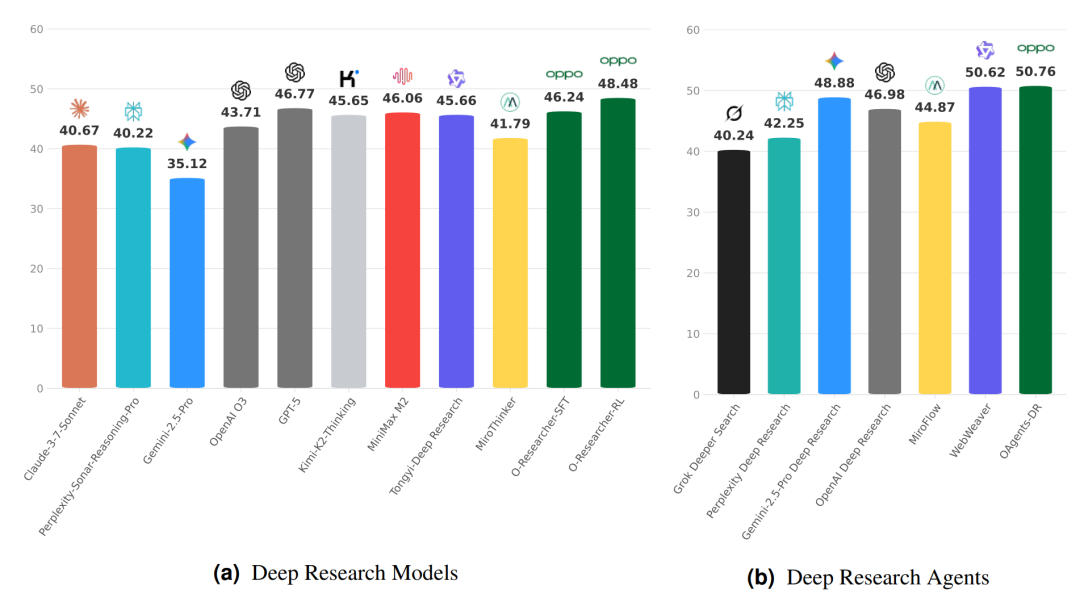
图4:(a)深度研究模型;(b)深度研究Agents
如图4所示,O-Researcher在包含100个doctoral-level研究任务的DeepResearch Bench上,实现了开源模型的新SOTA性能。
表1:Deep Research Bench整体评估结果
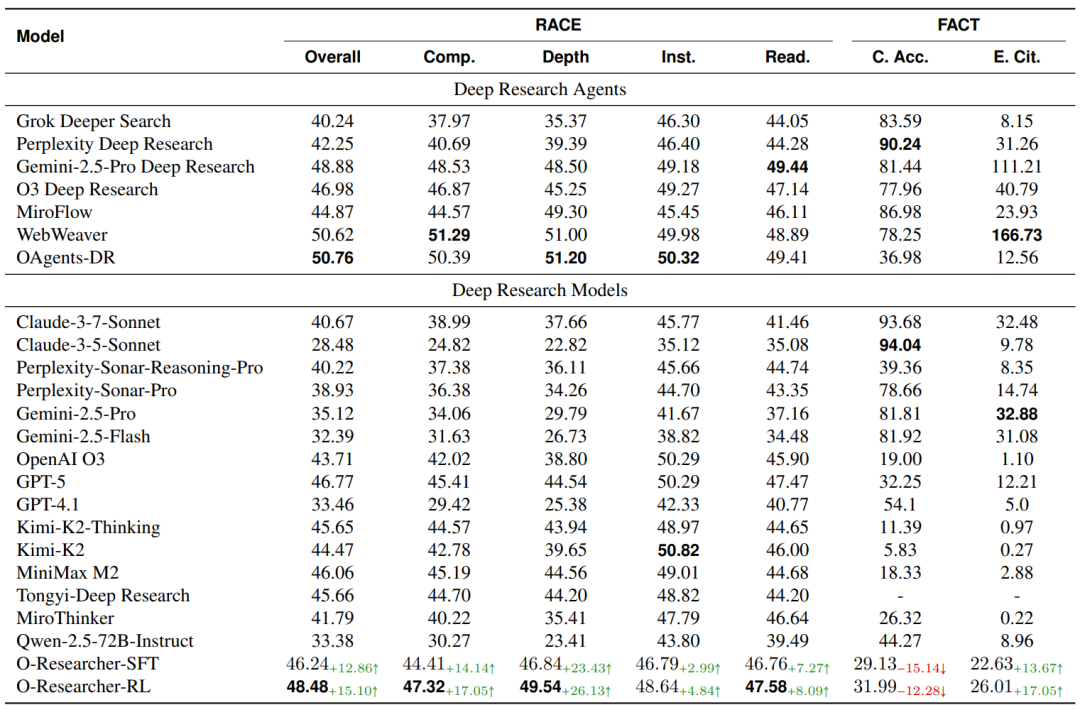
O-Researcher-RL以48.48的总体得分建立开源新SOTA,多轮准确率从基线的33.38%提升至48.48%,有效引用数从8.96大幅提升至26.01。这一结果表明,多智能体工作流成功解决了研究级数据规模化生成难题,通过模拟研究团队分工协作,无需人工标注即可产出高保真轨迹数据。
(2)DeepResearchGym评估结果
表2:对DeepResearchgym - Commercial - 100评估结果
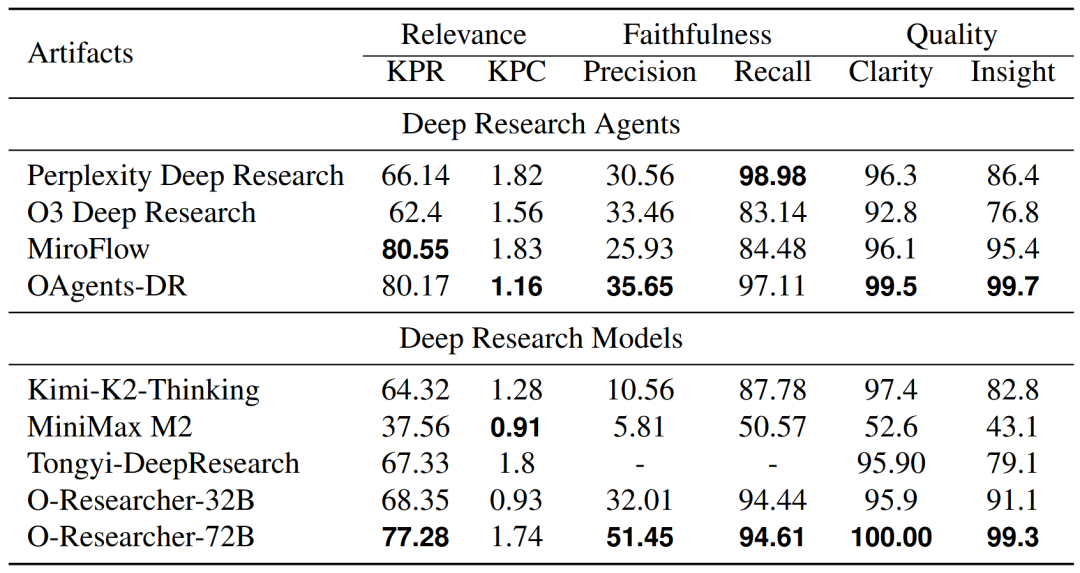
O-Researcher-72B在开源模型中实现 SOTA,且与闭源商业智能体竞争力极强;O-Researcher-72B在清晰度(100.00)和洞察力(99.3)上取得近乎完美分数,引用精度51.45为全类别最高,在保持高召回率的同时避免了幻觉引用。这证明了两阶段训练策略(SFT+RLAIF)有效平衡了模型的分析深度与事实严谨性,使开源模型在深度研究任务上实现突破性进展。
(3)并行执行有效性验证
表3:GPT-5 有无并行工作流的性能对比

并行执行使GPT-5总体得分从42.92提升至49.60,全面性(40.59→49.61)和洞察力(38.58→48.69)提升最为显著。这种并行化减轻了顺序生成中固有的上下文竞争,通过隔离搜索上下文,智能体成功检索并保留了细粒度证据。
(4)推理步数优化分析
表4:推理步数的影响(基于 OAgents 框架的性能)

10步工作流在性能与成本间取得最佳平衡,较5步方法总体得分提升0.81分,而20步虽略有提升但计算开销大幅增加。这表明更细粒度的任务分解能够实现对研究问题更彻底的探索,64k上下文窗口、10步推理、并行执行被验证为提升深度研究能力的关键技术参数。










