绑定手机号
确认绑定









智猩猩AI整理
编辑:六六
长视频生成面临效率与质量的双重挑战:扩散与扩散强迫模型虽生成质量高,但双向注意力机制导致推理效率低下;因果注意力自回归模型虽支持 KV 缓存以快速推理,但受限于长视频训练内存,生成质量随视频长度增加而下降。
此外,除静态提示生成外,交互能力对动态内容创作至关重要,它使用户能实时引导叙事,但也显著增加了系统复杂度,尤其需在提示切换时保证视觉一致性与语义连贯性。
为应对上述挑战,NVIDIA 联合麻省理工学院等研究团队提出LongLive——实时交互式长视频生成框架,现已被 ICLR 2026 收录。LongLive 在交互式长视频生成方面实现了高效与高质量的双重突破。就训练效率而言,LongLive 仅用 32 GPU 天将 1.3B 参数模型微调至分钟级生成;在推理效率方面,单卡 H100 上可达 20.7 FPS,支持生成长达 240 秒视频,VBench评测表现优异。

论文标题:LongLive: Real-time Interactive Long Video Generation
论文链接:https://arxiv.org/pdf/2509.22622
演示页面:https://nvlabs.github.io/LongLive/
源码链接:https://github.com/NVlabs/LongLive
模型链接:https://huggingface.co/Efficient-Large-Model/LongLive-1.3B
01 方法

图 1 LongLive 工作流程。
LongLive 工作流程如图 1 所示,LongLive 接收连续的用户提示,并实时生成相应视频,实现用户引导的长视频生成。
1. KV 重缓存
在DiT架构中,交叉注意力层反复注入提示信息并经自注意力前向传播,使KV缓存持续写入提示信号,导致切换时缓存仍残留旧语义。某些情况下,这导致对新提示的遵循不一致。
为此研究团队提出 KV 重缓存机制:在切换边界,利用已生成帧与新提示重新计算 KV 缓存,擦除旧提示残留的同时保留运动与视觉线索以保证时间连续性。
具体地,切换后首帧将视频前缀编码为视觉上下文,与新提示配对重建缓存,后续步骤基于刷新缓存正常生成,实现语义纯净对齐且无视觉断裂。
为实现训练-推理对齐,将重缓存集成至训练循环,图 2 所示:含切换的迭代中,执行一次重缓存后继续生成,并在蒸馏中使教师模型同步接收新提示,确保学生模型在精确的切换后条件下受训。

图 2 流式长视频微调流程。(a)短微调:仅监督5秒片段(如Self-Forcing方法),导致长视频生成质量下降。(b)朴素长微调:直接扩展至长序列,引发教师监督错误及内存溢出(OOM)。(c)流式长微调:本文方法通过在每轮迭代中复用历史 KV 缓存生成下一个5秒片段,并利用教师模型进行监督,实现长序列训练。
2. 流式长视频微调
LongLive 基于因果帧级自回归视频生成器构建。此类模型仅采用短片段训练,推理时通过滚动式定长上下文窗口反复馈入自身生成结果以生成长视频,但其"短训练-长测试"模式会引发内容漂移,破坏长时间范围内的生成一致性。
为解决该训练-推理失配问题,研究团队提出了"长训练-长测试"策略。训练阶段模型基于自身不完美预测展开长序列生成,并全程施加监督。
自监督方法面临两大实践挑战:教师模型基于短片段训练难以端到端监督长序列,且直接展开长序列反向传播易引发内存溢出(OOM)与计算效率低下。
针对上述挑战,研究团队提出了流式长视频微调流程,如图 2 所示,在保持局部可靠监督与可控内存的前提下实现长视频训练。
首轮迭代中,生成器从零采样短片段,并对其应用 DMD 蒸馏。后续迭代中,生成器基于历史 KV 缓存扩展上一轮片段,生成下一段短视频,并仅对新生成片段施加 DMD 监督。重复此滚动扩展直至预设最大长度,随后重置。
该流程模拟推理时行为,缩小训练-测试差异。每轮中教师模型仅监督当前短片段,片段级监督集合为完整序列提供全局引导。
3. 高效长推理
短窗口注意力:基于视频生成的时间局部性可以得出邻近帧对预测下一帧贡献更大,在推理与流式微调中采用局部窗口注意力。将注意力限制于固定窗口内,可同时降低计算与内存开销:注意力复杂度由窗口大小决定,不再随序列长度增长;每层所需 KV 缓存规模同样取决于窗口而非总视频长度。
帧汇聚点:仅靠注意力汇聚点 token 无法防止视频模型长程生成崩溃,实验发现通过流式长微调解决长程生成崩溃问题,注意力汇聚点便发挥效用。作为持久性全局锚点,注意力汇聚点显著提升长程时间一致性,从而缓解短窗口注意力下的质量-效率权衡。
具体而言,将视频的首帧块固定为全局汇聚点 token;这些 token 永久保留于KV缓存中,并与每个注意力层的键和值拼接,使其在局部窗口注意力下仍可全局访问。其余KV缓存采用短滚动窗口并按常规策略驱逐。
训练与推理一致性:将短窗口注意力与帧汇聚点集成至流式微调,实现训练-推理对齐与效率提升。设局部窗口为 帧,教师监督片段为 帧。每步训练保留:
1)前序上下文末 帧的无梯度 KV 缓存;
2)当前监督 帧的可梯度 KV 缓存。同时维护 个汇聚点 token,其永久驻留并与每层 KV 拼接,确保全局可访问性。
02 评估
1. 短视频生成
研究团队采用 VBench 官方提示集评估 LongLive 的短视频生成能力,并与同量级相关开源视频生成模型进行对比,所有分数均采用 VBench 统一数值系统进行归一化。
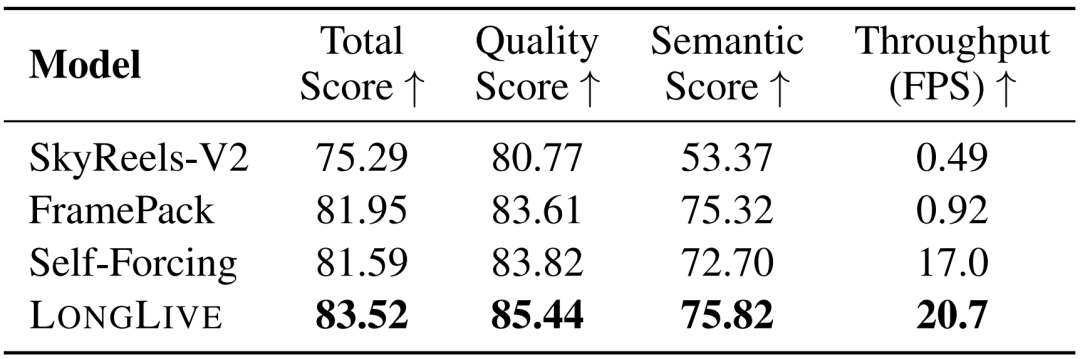
如表 1 所示,在 5 秒片段上,LongLive 在总分上媲美最强基线模型,展现出优异的质量与稳定性。得益于短窗口注意力设计,LongLive 在所有方法中推理速度最快,达到 20.7 FPS 的实时推理帧率。这表明 LongLive 并未牺牲短视频生成能力。
表 1 与相关基线模型对比。将 LongLive 与参数量及分辨率相当的代表性开源视频生成模型进行比较。FPS指标在单块H100 GPU上测得。

2. 长视频生成
研究团队采用 VBench-Long 官方提示集评估LongLive的单提示长视频生成能力。针对每个提示生成 30 秒视频,并依据 VBench-Long 官方脚本将视频分割为片段。表 2 报告了长时质量与一致性的标准VBench-Long指标。LongLive 在取得最先进性能的同时,实现了最快推理速度。
表 2 在VBench-Long上的单提示30秒长视频评估。
3. 交互式长视频生成
由于标准VBench协议无法直接适用,研究团队构建了包含 160 个交互式 60 秒视频的自定义验证集,每个视频由 6 个连续的 10 秒提示组成。长时质量评估采用支持自定义提示视频的 VBench-Long 维度,包括主体一致性、背景一致性、运动平滑性、美学质量和成像质量。语义遵循度评估则按提示边界分割视频,并使用 CLIP 分数计算片段级语义分数。

图 3 交互式长视频生成的定性比较。
定性及定量结果分别如图 3 和表 3 所示。LongLive 展现出强提示遵循能力、平滑过渡特性及高长程一致性,同时保持高吞吐量。相比之下,Self-Forcing 在长时生成中质量下降,SkyReels-v2 则一致性较弱。速度方面,得益于短窗口注意力设计,即便引入KV重缓存,LongLive 仍比 SkyReels-v2 快 41 倍以上,且略快于 Self-Forcing。最后,用户研究进一步验证了所提方法的有效性(图 1 右侧)。
表 3 交互式长视频评估:质量分数基于完整60秒序列报告。CLIP分数基于具有相同语义的10秒视频片段报告。











